 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpivavtor: An Instruction Tuned Ukrainian Text Editing Model
Apr 29, 2024We introduce Spivavtor, a dataset, and instruction-tuned models for text editing focused on the Ukrainian language. Spivavtor is the Ukrainian-focused adaptation of the English-only CoEdIT model. Similar to CoEdIT, Spivavtor performs text editing tasks by following instructions in Ukrainian. This paper describes the details of the Spivavtor-Instruct dataset and Spivavtor models. We evaluate Spivavtor on a variety of text editing tasks in Ukrainian, such as Grammatical Error Correction (GEC), Text Simplification, Coherence, and Paraphrasing, and demonstrate its superior performance on all of them. We publicly release our best-performing models and data as resources to the community to advance further research in this space.
Pillars of Grammatical Error Correction: Comprehensive Inspection Of Contemporary Approaches In The Era of Large Language Models
Apr 23, 2024



In this paper, we carry out experimental research on Grammatical Error Correction, delving into the nuances of single-model systems, comparing the efficiency of ensembling and ranking methods, and exploring the application of large language models to GEC as single-model systems, as parts of ensembles, and as ranking methods. We set new state-of-the-art performance with F_0.5 scores of 72.8 on CoNLL-2014-test and 81.4 on BEA-test, respectively. To support further advancements in GEC and ensure the reproducibility of our research, we make our code, trained models, and systems' outputs publicly available.
Privacy- and Utility-Preserving NLP with Anonymized Data: A case study of Pseudonymization
Jun 08, 2023



This work investigates the effectiveness of different pseudonymization techniques, ranging from rule-based substitutions to using pre-trained Large Language Models (LLMs), on a variety of datasets and models used for two widely used NLP tasks: text classification and summarization. Our work provides crucial insights into the gaps between original and anonymized data (focusing on the pseudonymization technique) and model quality and fosters future research into higher-quality anonymization techniques to better balance the trade-offs between data protection and utility preservation. We make our code, pseudonymized datasets, and downstream models publicly available
Ensembling and Knowledge Distilling of Large Sequence Taggers for Grammatical Error Correction
Mar 24, 2022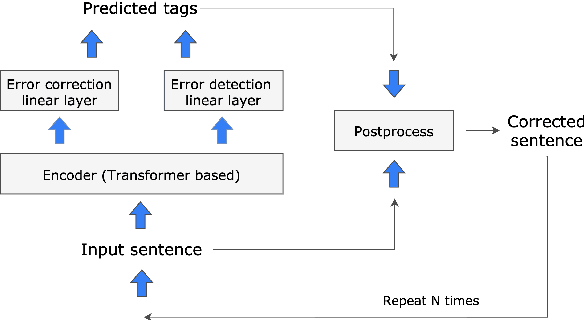
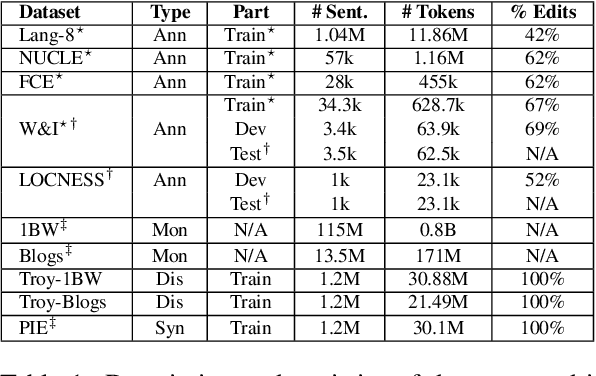

In this paper, we investigate improvements to the GEC sequence tagging architecture with a focus on ensembling of recent cutting-edge Transformer-based encoders in Large configurations. We encourage ensembling models by majority votes on span-level edits because this approach is tolerant to the model architecture and vocabulary size. Our best ensemble achieves a new SOTA result with an $F_{0.5}$ score of 76.05 on BEA-2019 (test), even without pre-training on synthetic datasets. In addition, we perform knowledge distillation with a trained ensemble to generate new synthetic training datasets, "Troy-Blogs" and "Troy-1BW". Our best single sequence tagging model that is pretrained on the generated Troy-datasets in combination with the publicly available synthetic PIE dataset achieves a near-SOTA (To the best of our knowledge, our best single model gives way only to much heavier T5 model result with an $F_{0.5}$ score of 73.21 on BEA-2019 (test). The code, datasets, and trained models are publicly available).
GECToR -- Grammatical Error Correction: Tag, Not Rewrite
May 29, 2020
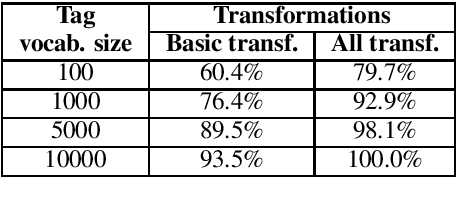

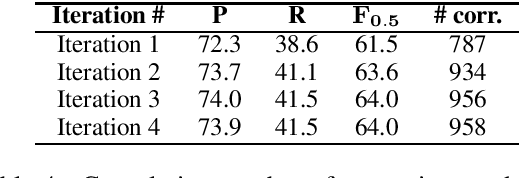
In this paper, we present a simple and efficient GEC sequence tagger using a Transformer encoder. Our system is pre-trained on synthetic data and then fine-tuned in two stages: first on errorful corpora, and second on a combination of errorful and error-free parallel corpora. We design custom token-level transformations to map input tokens to target corrections. Our best single-model/ensemble GEC tagger achieves an $F_{0.5}$ of 65.3/66.5 on CoNLL-2014 (test) and $F_{0.5}$ of 72.4/73.6 on BEA-2019 (test). Its inference speed is up to 10 times as fast as a Transformer-based seq2seq GEC system. The code and trained models are publicly available.
Sampling-based Gradient Regularization for Capturing Long-Term Dependencies in Recurrent Neural Networks
Feb 13, 2017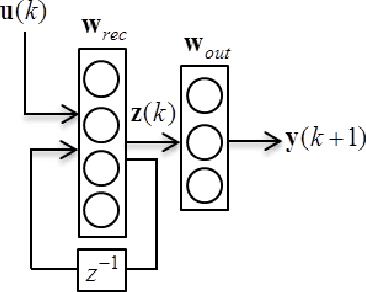

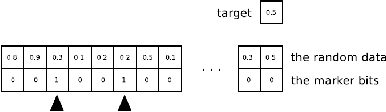

Vanishing (and exploding) gradients effect is a common problem for recurrent neural networks with nonlinear activation functions which use backpropagation method for calculation of derivatives. Deep feedforward neural networks with many hidden layers also suffer from this effect. In this paper we propose a novel universal technique that makes the norm of the gradient stay in the suitable range. We construct a way to estimate a contribution of each training example to the norm of the long-term components of the target function s gradient. Using this subroutine we can construct mini-batches for the stochastic gradient descent (SGD) training that leads to high performance and accuracy of the trained network even for very complex tasks. We provide a straightforward mathematical estimation of minibatch s impact on for the gradient norm and prove its correctness theoretically. To check our framework experimentally we use some special synthetic benchmarks for testing RNNs on ability to capture long-term dependencies. Our network can detect links between events in the (temporal) sequence at the range approx. 100 and longer.
Norm-preserving Orthogonal Permutation Linear Unit Activation Functions (OPLU)
Jan 31, 2017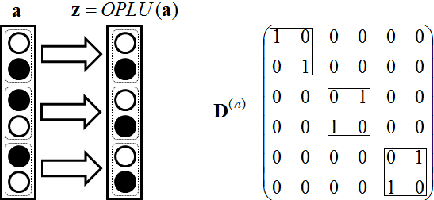



We propose a novel activation function that implements piece-wise orthogonal non-linear mappings based on permutations. It is straightforward to implement, and very computationally efficient, also it has little memory requirements. We tested it on two toy problems for feedforward and recurrent networks, it shows similar performance to tanh and ReLU. OPLU activation function ensures norm preservance of the backpropagated gradients, therefore it is potentially good for the training of deep, extra deep, and recurrent neural networks.
Direct Method for Training Feed-forward Neural Networks using Batch Extended Kalman Filter for Multi-Step-Ahead Predictions
May 12, 2016


This paper is dedicated to the long-term, or multi-step-ahead, time series prediction problem. We propose a novel method for training feed-forward neural networks, such as multilayer perceptrons, with tapped delay lines. Special batch calculation of derivatives called Forecasted Propagation Through Time and batch modification of the Extended Kalman Filter are introduced. Experiments were carried out on well-known time series benchmarks, the Mackey-Glass chaotic process and the Santa Fe Laser Data Series. Recurrent and feed-forward neural networks were evaluated.
Neurocontrol methods review
Nov 17, 2015Methods of applying neural networks to control plants are considered. Methods and schemes are described, their advantages and disadvantages are discussed.
* in Russian