 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling-based Gradient Regularization for Capturing Long-Term Dependencies in Recurrent Neural Networks
Feb 13, 2017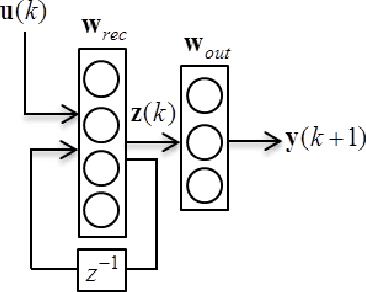

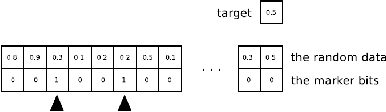

Vanishing (and exploding) gradients effect is a common problem for recurrent neural networks with nonlinear activation functions which use backpropagation method for calculation of derivatives. Deep feedforward neural networks with many hidden layers also suffer from this effect. In this paper we propose a novel universal technique that makes the norm of the gradient stay in the suitable range. We construct a way to estimate a contribution of each training example to the norm of the long-term components of the target function s gradient. Using this subroutine we can construct mini-batches for the stochastic gradient descent (SGD) training that leads to high performance and accuracy of the trained network even for very complex tasks. We provide a straightforward mathematical estimation of minibatch s impact on for the gradient norm and prove its correctness theoretically. To check our framework experimentally we use some special synthetic benchmarks for testing RNNs on ability to capture long-term dependencies. Our network can detect links between events in the (temporal) sequence at the range approx. 100 and longer.
Norm-preserving Orthogonal Permutation Linear Unit Activation Functions (OPLU)
Jan 31, 2017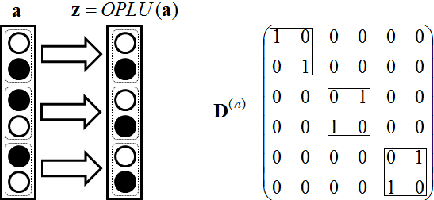



We propose a novel activation function that implements piece-wise orthogonal non-linear mappings based on permutations. It is straightforward to implement, and very computationally efficient, also it has little memory requirements. We tested it on two toy problems for feedforward and recurrent networks, it shows similar performance to tanh and ReLU. OPLU activation function ensures norm preservance of the backpropagated gradients, therefore it is potentially good for the training of deep, extra deep, and recurrent neural networks.