Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNorm-preserving Orthogonal Permutation Linear Unit Activation Functions (OPLU)
Paper and Code
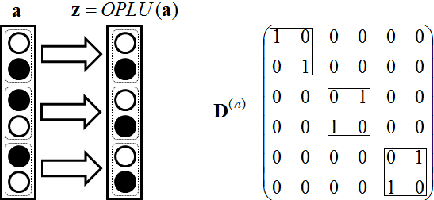



We propose a novel activation function that implements piece-wise orthogonal non-linear mappings based on permutations. It is straightforward to implement, and very computationally efficient, also it has little memory requirements. We tested it on two toy problems for feedforward and recurrent networks, it shows similar performance to tanh and ReLU. OPLU activation function ensures norm preservance of the backpropagated gradients, therefore it is potentially good for the training of deep, extra deep, and recurrent neural networks.
* Submitted to conference ICANN'2016
View paper on