 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePillars of Grammatical Error Correction: Comprehensive Inspection Of Contemporary Approaches In The Era of Large Language Models
Apr 23, 2024



In this paper, we carry out experimental research on Grammatical Error Correction, delving into the nuances of single-model systems, comparing the efficiency of ensembling and ranking methods, and exploring the application of large language models to GEC as single-model systems, as parts of ensembles, and as ranking methods. We set new state-of-the-art performance with F_0.5 scores of 72.8 on CoNLL-2014-test and 81.4 on BEA-test, respectively. To support further advancements in GEC and ensure the reproducibility of our research, we make our code, trained models, and systems' outputs publicly available.
Gender-Inclusive Grammatical Error Correction through Augmentation
Jun 12, 2023



In this paper we show that GEC systems display gender bias related to the use of masculine and feminine terms and the gender-neutral singular "they". We develop parallel datasets of texts with masculine and feminine terms and singular "they" and use them to quantify gender bias in three competitive GEC systems. We contribute a novel data augmentation technique for singular "they" leveraging linguistic insights about its distribution relative to plural "they". We demonstrate that both this data augmentation technique and a refinement of a similar augmentation technique for masculine and feminine terms can generate training data that reduces bias in GEC systems, especially with respect to singular "they" while maintaining the same level of quality.
Ensembling and Knowledge Distilling of Large Sequence Taggers for Grammatical Error Correction
Mar 24, 2022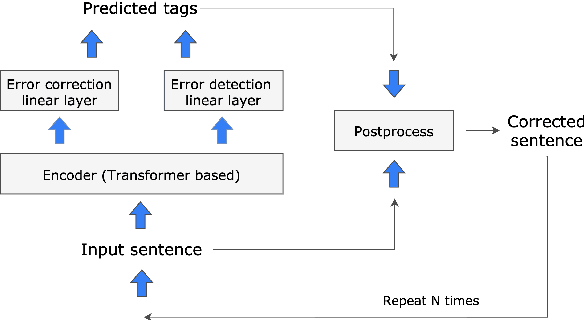
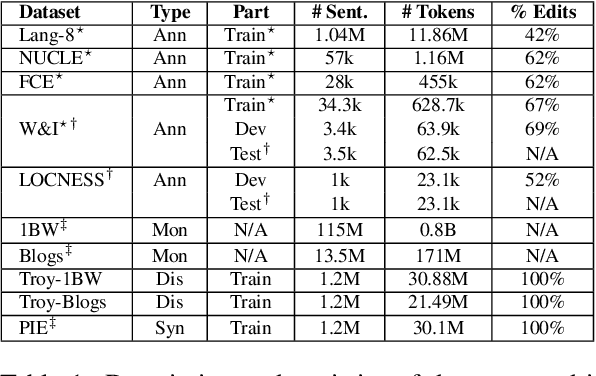
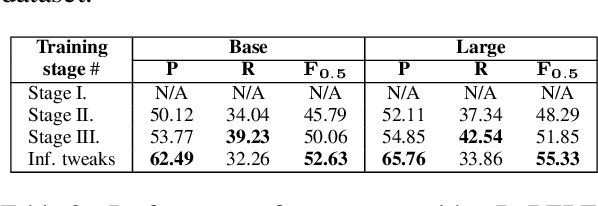

In this paper, we investigate improvements to the GEC sequence tagging architecture with a focus on ensembling of recent cutting-edge Transformer-based encoders in Large configurations. We encourage ensembling models by majority votes on span-level edits because this approach is tolerant to the model architecture and vocabulary size. Our best ensemble achieves a new SOTA result with an $F_{0.5}$ score of 76.05 on BEA-2019 (test), even without pre-training on synthetic datasets. In addition, we perform knowledge distillation with a trained ensemble to generate new synthetic training datasets, "Troy-Blogs" and "Troy-1BW". Our best single sequence tagging model that is pretrained on the generated Troy-datasets in combination with the publicly available synthetic PIE dataset achieves a near-SOTA (To the best of our knowledge, our best single model gives way only to much heavier T5 model result with an $F_{0.5}$ score of 73.21 on BEA-2019 (test). The code, datasets, and trained models are publicly available).
Text Simplification by Tagging
Mar 08, 2021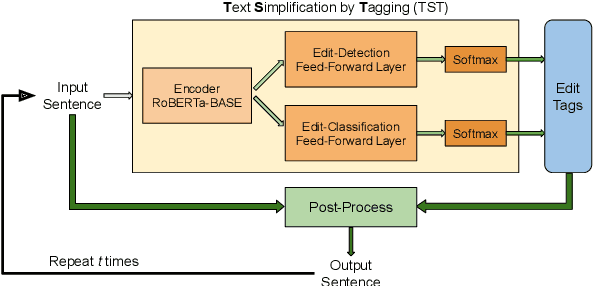


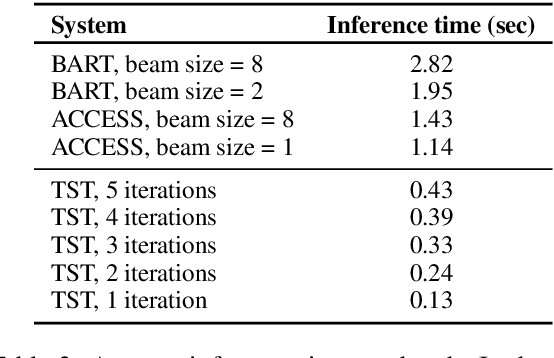
Edit-based approaches have recently shown promising results on multiple monolingual sequence transduction tasks. In contrast to conventional sequence-to-sequence (Seq2Seq) models, which learn to generate text from scratch as they are trained on parallel corpora, these methods have proven to be much more effective since they are able to learn to make fast and accurate transformations while leveraging powerful pre-trained language models. Inspired by these ideas, we present TST, a simple and efficient Text Simplification system based on sequence Tagging, leveraging pre-trained Transformer-based encoders. Our system makes simplistic data augmentations and tweaks in training and inference on a pre-existing system, which makes it less reliant on large amounts of parallel training data, provides more control over the outputs and enables faster inference speeds. Our best model achieves near state-of-the-art performance on benchmark test datasets for the task. Since it is fully non-autoregressive, it achieves faster inference speeds by over 11 times than the current state-of-the-art text simplification system.
GECToR -- Grammatical Error Correction: Tag, Not Rewrite
May 29, 2020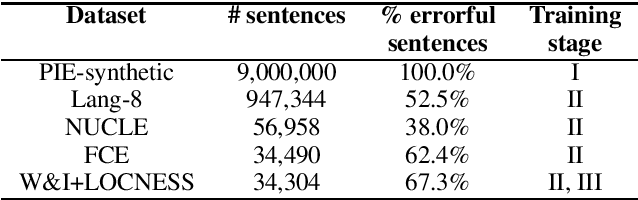
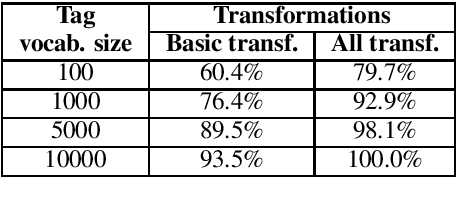

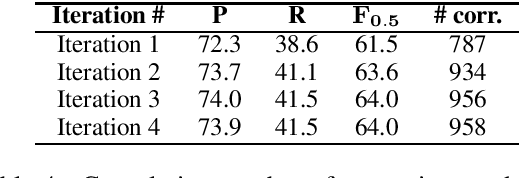
In this paper, we present a simple and efficient GEC sequence tagger using a Transformer encoder. Our system is pre-trained on synthetic data and then fine-tuned in two stages: first on errorful corpora, and second on a combination of errorful and error-free parallel corpora. We design custom token-level transformations to map input tokens to target corrections. Our best single-model/ensemble GEC tagger achieves an $F_{0.5}$ of 65.3/66.5 on CoNLL-2014 (test) and $F_{0.5}$ of 72.4/73.6 on BEA-2019 (test). Its inference speed is up to 10 times as fast as a Transformer-based seq2seq GEC system. The code and trained models are publicly available.
How do you correct run-on sentences it's not as easy as it seems
Sep 21, 2018

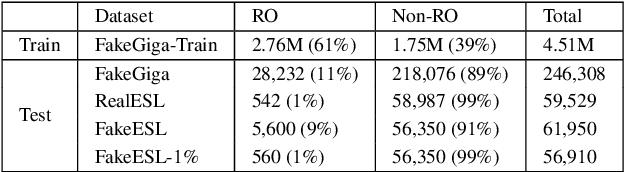
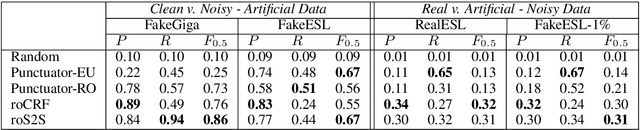
Run-on sentences are common grammatical mistakes but little research has tackled this problem to date. This work introduces two machine learning models to correct run-on sentences that outperform leading methods for related tasks, punctuation restoration and whole-sentence grammatical error correction. Due to the limited annotated data for this error, we experiment with artificially generating training data from clean newswire text. Our findings suggest artificial training data is viable for this task. We discuss implications for correcting run-ons and other types of mistakes that have low coverage in error-annotated corpora.