 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating a Domain-diverse Corpus for Theory-based Argument Quality Assessment
Nov 03, 2020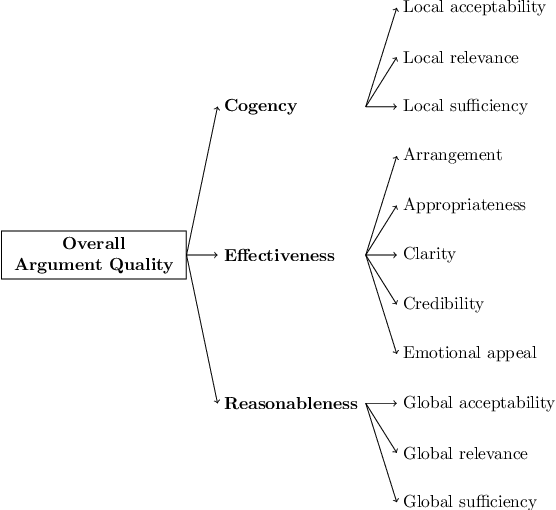
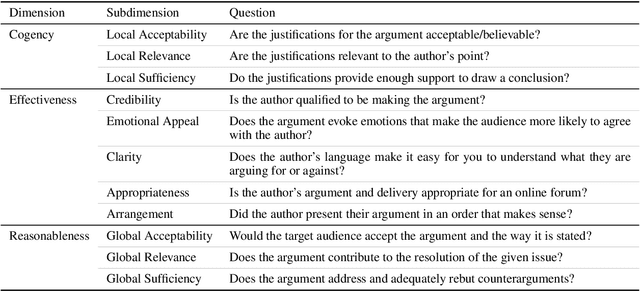
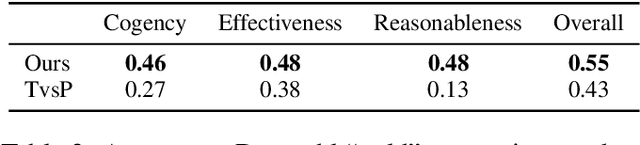
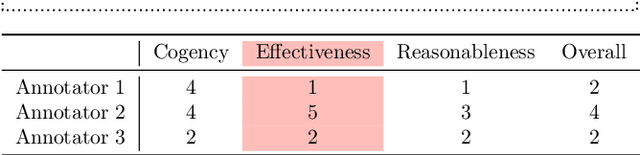
Computational models of argument quality (AQ) have focused primarily on assessing the overall quality or just one specific characteristic of an argument, such as its convincingness or its clarity. However, previous work has claimed that assessment based on theoretical dimensions of argumentation could benefit writers, but developing such models has been limited by the lack of annotated data. In this work, we describe GAQCorpus, the first large, domain-diverse annotated corpus of theory-based AQ. We discuss how we designed the annotation task to reliably collect a large number of judgments with crowdsourcing, formulating theory-based guidelines that helped make subjective judgments of AQ more objective. We demonstrate how to identify arguments and adapt the annotation task for three diverse domains. Our work will inform research on theory-based argumentation annotation and enable the creation of more diverse corpora to support computational AQ assessment.
Rhetoric, Logic, and Dialectic: Advancing Theory-based Argument Quality Assessment in Natural Language Processing
Jun 01, 2020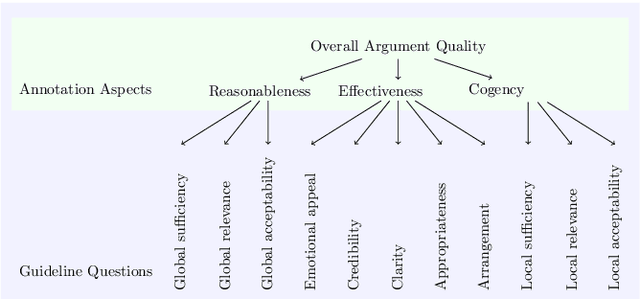

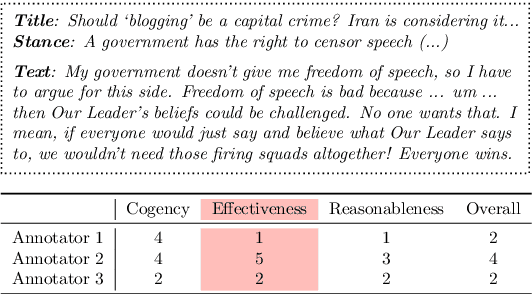
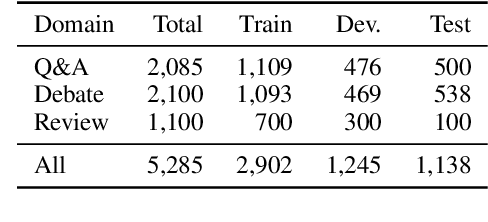
Argumentative quality is an important feature of everyday writing in many textual domains, such as online reviews and question-and-answer (Q&A) forums. Authors can improve their writing with feedback targeting individual aspects of argument quality (AQ), even though preceding work has mostly focused on assessing the overall AQ. These individual aspects are reflected in theory-based dimensions of argument quality, but automatic assessment in real-world texts is still in its infancy -- a large-scale corpus and computational models are missing. In this work, we advance theory-based argument quality research by conducting an extensive analysis covering three diverse domains of online argumentative writing: Q&A forums, debate forums, and review forums. We start with an annotation study with linguistic experts and crowd workers, resulting in the first large-scale English corpus annotated with theory-based argument quality scores, dubbed AQCorpus. Next, we propose the first computational approaches to theory-based argument quality assessment, which can serve as strong baselines for future work. Our research yields interesting findings including the feasibility of large-scale theory-based argument quality annotations, the fact that relations between theory-based argument quality dimensions can be exploited to yield performance improvements, and demonstrates the usefulness of theory-based argument quality predictions with respect to the practical AQ assessment view.
How do you correct run-on sentences it's not as easy as it seems
Sep 21, 2018

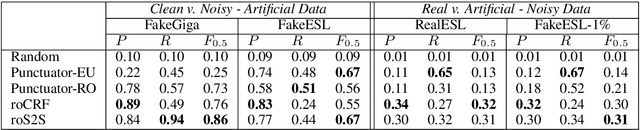
Run-on sentences are common grammatical mistakes but little research has tackled this problem to date. This work introduces two machine learning models to correct run-on sentences that outperform leading methods for related tasks, punctuation restoration and whole-sentence grammatical error correction. Due to the limited annotated data for this error, we experiment with artificially generating training data from clean newswire text. Our findings suggest artificial training data is viable for this task. We discuss implications for correcting run-ons and other types of mistakes that have low coverage in error-annotated corpora.
JFLEG: A Fluency Corpus and Benchmark for Grammatical Error Correction
Feb 14, 2017
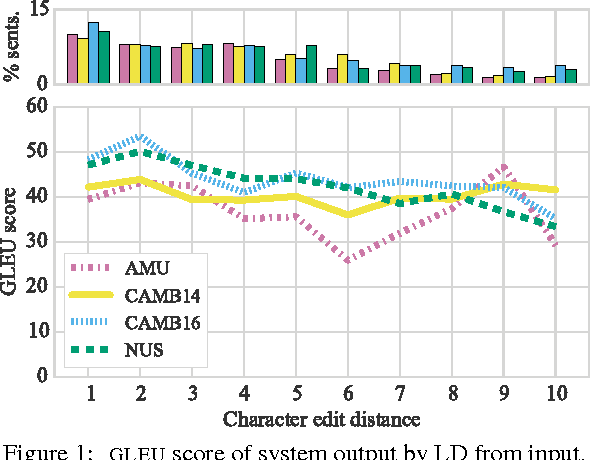
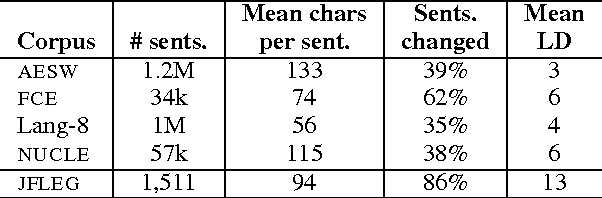
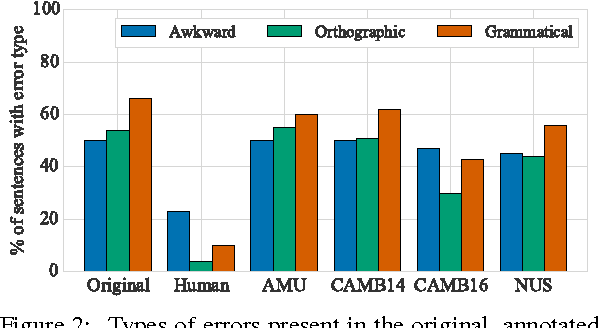
We present a new parallel corpus, JHU FLuency-Extended GUG corpus (JFLEG) for developing and evaluating grammatical error correction (GEC). Unlike other corpora, it represents a broad range of language proficiency levels and uses holistic fluency edits to not only correct grammatical errors but also make the original text more native sounding. We describe the types of corrections made and benchmark four leading GEC systems on this corpus, identifying specific areas in which they do well and how they can improve. JFLEG fulfills the need for a new gold standard to properly assess the current state of GEC.
There's No Comparison: Reference-less Evaluation Metrics in Grammatical Error Correction
Oct 07, 2016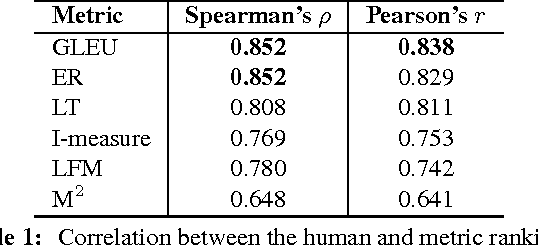
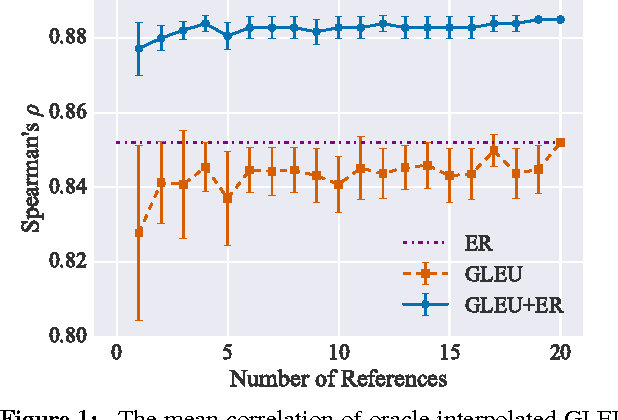

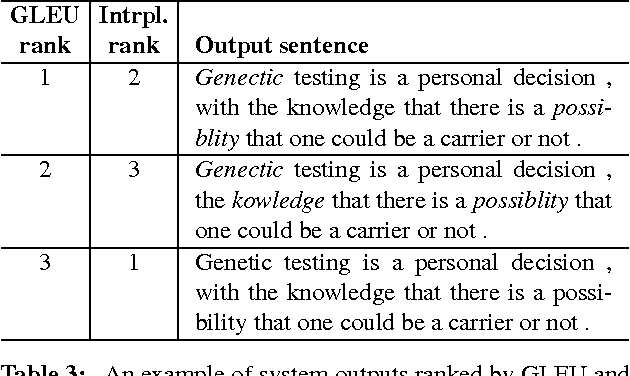
Current methods for automatically evaluating grammatical error correction (GEC) systems rely on gold-standard references. However, these methods suffer from penalizing grammatical edits that are correct but not in the gold standard. We show that reference-less grammaticality metrics correlate very strongly with human judgments and are competitive with the leading reference-based evaluation metrics. By interpolating both methods, we achieve state-of-the-art correlation with human judgments. Finally, we show that GEC metrics are much more reliable when they are calculated at the sentence level instead of the corpus level. We have set up a CodaLab site for benchmarking GEC output using a common dataset and different evaluation metrics.
GLEU Without Tuning
May 09, 2016

The GLEU metric was proposed for evaluating grammatical error corrections using n-gram overlap with a set of reference sentences, as opposed to precision/recall of specific annotated errors (Napoles et al., 2015). This paper describes improvements made to the GLEU metric that address problems that arise when using an increasing number of reference sets. Unlike the originally presented metric, the modified metric does not require tuning. We recommend that this version be used instead of the original version.