 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating a Domain-diverse Corpus for Theory-based Argument Quality Assessment
Nov 03, 2020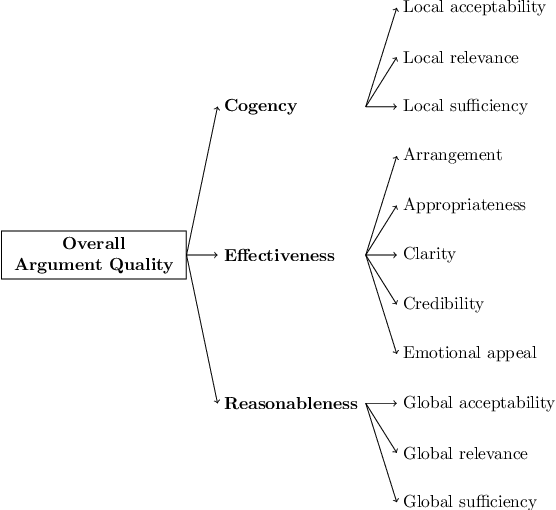
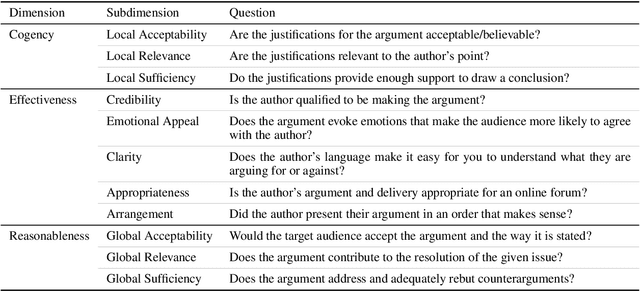
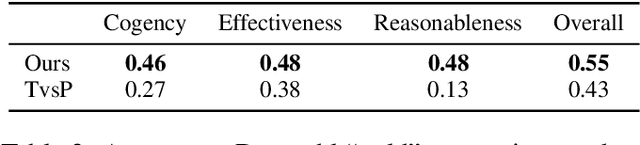
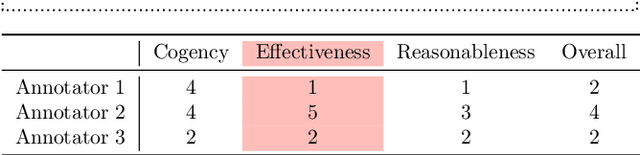
Computational models of argument quality (AQ) have focused primarily on assessing the overall quality or just one specific characteristic of an argument, such as its convincingness or its clarity. However, previous work has claimed that assessment based on theoretical dimensions of argumentation could benefit writers, but developing such models has been limited by the lack of annotated data. In this work, we describe GAQCorpus, the first large, domain-diverse annotated corpus of theory-based AQ. We discuss how we designed the annotation task to reliably collect a large number of judgments with crowdsourcing, formulating theory-based guidelines that helped make subjective judgments of AQ more objective. We demonstrate how to identify arguments and adapt the annotation task for three diverse domains. Our work will inform research on theory-based argumentation annotation and enable the creation of more diverse corpora to support computational AQ assessment.
Rhetoric, Logic, and Dialectic: Advancing Theory-based Argument Quality Assessment in Natural Language Processing
Jun 01, 2020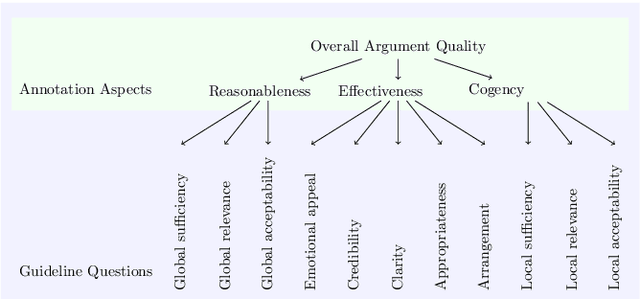

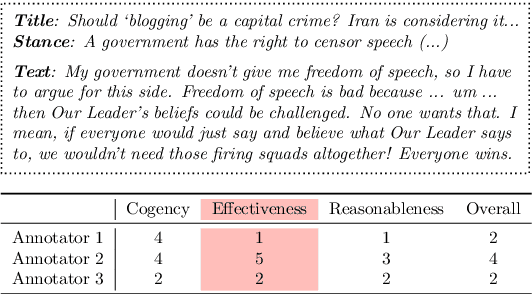
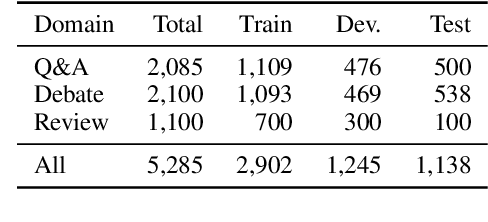
Argumentative quality is an important feature of everyday writing in many textual domains, such as online reviews and question-and-answer (Q&A) forums. Authors can improve their writing with feedback targeting individual aspects of argument quality (AQ), even though preceding work has mostly focused on assessing the overall AQ. These individual aspects are reflected in theory-based dimensions of argument quality, but automatic assessment in real-world texts is still in its infancy -- a large-scale corpus and computational models are missing. In this work, we advance theory-based argument quality research by conducting an extensive analysis covering three diverse domains of online argumentative writing: Q&A forums, debate forums, and review forums. We start with an annotation study with linguistic experts and crowd workers, resulting in the first large-scale English corpus annotated with theory-based argument quality scores, dubbed AQCorpus. Next, we propose the first computational approaches to theory-based argument quality assessment, which can serve as strong baselines for future work. Our research yields interesting findings including the feasibility of large-scale theory-based argument quality annotations, the fact that relations between theory-based argument quality dimensions can be exploited to yield performance improvements, and demonstrates the usefulness of theory-based argument quality predictions with respect to the practical AQ assessment view.