 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Simplification by Tagging
Paper and Code
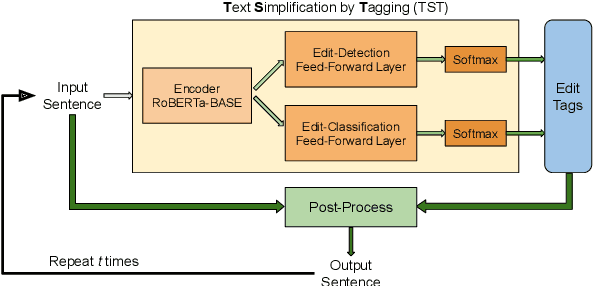


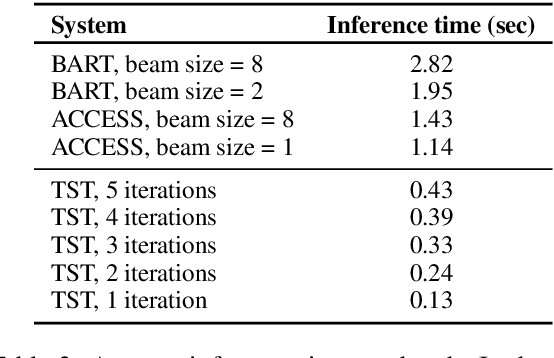
Edit-based approaches have recently shown promising results on multiple monolingual sequence transduction tasks. In contrast to conventional sequence-to-sequence (Seq2Seq) models, which learn to generate text from scratch as they are trained on parallel corpora, these methods have proven to be much more effective since they are able to learn to make fast and accurate transformations while leveraging powerful pre-trained language models. Inspired by these ideas, we present TST, a simple and efficient Text Simplification system based on sequence Tagging, leveraging pre-trained Transformer-based encoders. Our system makes simplistic data augmentations and tweaks in training and inference on a pre-existing system, which makes it less reliant on large amounts of parallel training data, provides more control over the outputs and enables faster inference speeds. Our best model achieves near state-of-the-art performance on benchmark test datasets for the task. Since it is fully non-autoregressive, it achieves faster inference speeds by over 11 times than the current state-of-the-art text simplification system.