 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLQ-Adapter: ViT-Adapter with Learnable Queries for Gallbladder Cancer Detection from Ultrasound Image
Nov 30, 2024We focus on the problem of Gallbladder Cancer (GBC) detection from Ultrasound (US) images. The problem presents unique challenges to modern Deep Neural Network (DNN) techniques due to low image quality arising from noise, textures, and viewpoint variations. Tackling such challenges would necessitate precise localization performance by the DNN to identify the discerning features for the downstream malignancy prediction. While several techniques have been proposed in the recent years for the problem, all of these methods employ complex custom architectures. Inspired by the success of foundational models for natural image tasks, along with the use of adapters to fine-tune such models for the custom tasks, we investigate the merit of one such design, ViT-Adapter, for the GBC detection problem. We observe that ViT-Adapter relies predominantly on a primitive CNN-based spatial prior module to inject the localization information via cross-attention, which is inefficient for our problem due to the small pathology sizes, and variability in their appearances due to non-regular structure of the malignancy. In response, we propose, LQ-Adapter, a modified Adapter design for ViT, which improves localization information by leveraging learnable content queries over the basic spatial prior module. Our method surpasses existing approaches, enhancing the mean IoU (mIoU) scores by 5.4%, 5.8%, and 2.7% over ViT-Adapters, DINO, and FocalNet-DINO, respectively on the US image-based GBC detection dataset, and establishing a new state-of-the-art (SOTA). Additionally, we validate the applicability and effectiveness of LQ-Adapter on the Kvasir-Seg dataset for polyp detection from colonoscopy images. Superior performance of our design on this problem as well showcases its capability to handle diverse medical imaging tasks across different datasets. Code is released at https://github.com/ChetanMadan/LQ-Adapter
FocusMAE: Gallbladder Cancer Detection from Ultrasound Videos with Focused Masked Autoencoders
Mar 29, 2024In recent years, automated Gallbladder Cancer (GBC) detection has gained the attention of researchers. Current state-of-the-art (SOTA) methodologies relying on ultrasound sonography (US) images exhibit limited generalization, emphasizing the need for transformative approaches. We observe that individual US frames may lack sufficient information to capture disease manifestation. This study advocates for a paradigm shift towards video-based GBC detection, leveraging the inherent advantages of spatiotemporal representations. Employing the Masked Autoencoder (MAE) for representation learning, we address shortcomings in conventional image-based methods. We propose a novel design called FocusMAE to systematically bias the selection of masking tokens from high-information regions, fostering a more refined representation of malignancy. Additionally, we contribute the most extensive US video dataset for GBC detection. We also note that, this is the first study on US video-based GBC detection. We validate the proposed methods on the curated dataset, and report a new state-of-the-art (SOTA) accuracy of 96.4% for the GBC detection problem, against an accuracy of 84% by current Image-based SOTA - GBCNet, and RadFormer, and 94.7% by Video-based SOTA - AdaMAE. We further demonstrate the generality of the proposed FocusMAE on a public CT-based Covid detection dataset, reporting an improvement in accuracy by 3.3% over current baselines. The source code and pretrained models are available at: https://gbc-iitd.github.io/focusmae
Gall Bladder Cancer Detection from US Images with Only Image Level Labels
Sep 11, 2023



Automated detection of Gallbladder Cancer (GBC) from Ultrasound (US) images is an important problem, which has drawn increased interest from researchers. However, most of these works use difficult-to-acquire information such as bounding box annotations or additional US videos. In this paper, we focus on GBC detection using only image-level labels. Such annotation is usually available based on the diagnostic report of a patient, and do not require additional annotation effort from the physicians. However, our analysis reveals that it is difficult to train a standard image classification model for GBC detection. This is due to the low inter-class variance (a malignant region usually occupies only a small portion of a US image), high intra-class variance (due to the US sensor capturing a 2D slice of a 3D object leading to large viewpoint variations), and low training data availability. We posit that even when we have only the image level label, still formulating the problem as object detection (with bounding box output) helps a deep neural network (DNN) model focus on the relevant region of interest. Since no bounding box annotations is available for training, we pose the problem as weakly supervised object detection (WSOD). Motivated by the recent success of transformer models in object detection, we train one such model, DETR, using multi-instance-learning (MIL) with self-supervised instance selection to suit the WSOD task. Our proposed method demonstrates an improvement of AP and detection sensitivity over the SOTA transformer-based and CNN-based WSOD methods. Project page is at https://gbc-iitd.github.io/wsod-gbc
RadFormer: Transformers with Global-Local Attention for Interpretable and Accurate Gallbladder Cancer Detection
Nov 09, 2022



We propose a novel deep neural network architecture to learn interpretable representation for medical image analysis. Our architecture generates a global attention for region of interest, and then learns bag of words style deep feature embeddings with local attention. The global, and local feature maps are combined using a contemporary transformer architecture for highly accurate Gallbladder Cancer (GBC) detection from Ultrasound (USG) images. Our experiments indicate that the detection accuracy of our model beats even human radiologists, and advocates its use as the second reader for GBC diagnosis. Bag of words embeddings allow our model to be probed for generating interpretable explanations for GBC detection consistent with the ones reported in medical literature. We show that the proposed model not only helps understand decisions of neural network models but also aids in discovery of new visual features relevant to the diagnosis of GBC. Source-code and model will be available at https://github.com/sbasu276/RadFormer
Unsupervised Contrastive Learning of Image Representations from Ultrasound Videos with Hard Negative Mining
Jul 26, 2022
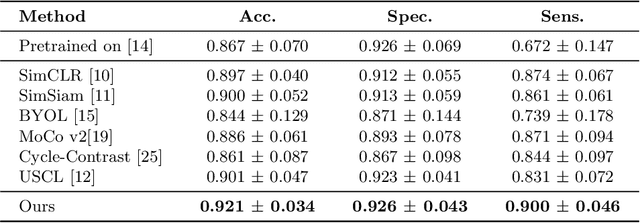
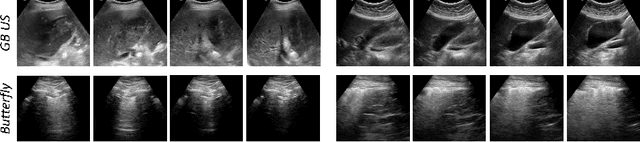
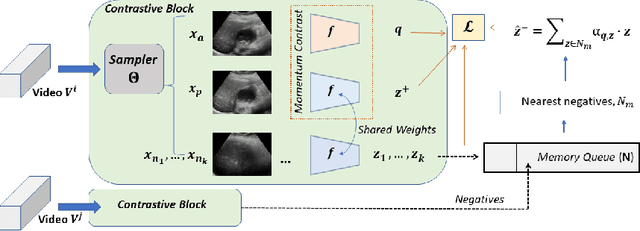
Rich temporal information and variations in viewpoints make video data an attractive choice for learning image representations using unsupervised contrastive learning (UCL) techniques. State-of-the-art (SOTA) contrastive learning techniques consider frames within a video as positives in the embedding space, whereas the frames from other videos are considered negatives. We observe that unlike multiple views of an object in natural scene videos, an Ultrasound (US) video captures different 2D slices of an organ. Hence, there is almost no similarity between the temporally distant frames of even the same US video. In this paper we propose to instead utilize such frames as hard negatives. We advocate mining both intra-video and cross-video negatives in a hardness-sensitive negative mining curriculum in a UCL framework to learn rich image representations. We deploy our framework to learn the representations of Gallbladder (GB) malignancy from US videos. We also construct the first large-scale US video dataset containing 64 videos and 15,800 frames for learning GB representations. We show that the standard ResNet50 backbone trained with our framework improves the accuracy of models pretrained with SOTA UCL techniques as well as supervised pretrained models on ImageNet for the GB malignancy detection task by 2-6%. We further validate the generalizability of our method on a publicly available lung US image dataset of COVID-19 pathologies and show an improvement of 1.5% compared to SOTA. Source code, dataset, and models are available at https://gbc-iitd.github.io/usucl.
Surpassing the Human Accuracy: Detecting Gallbladder Cancer from USG Images with Curriculum Learning
Apr 25, 2022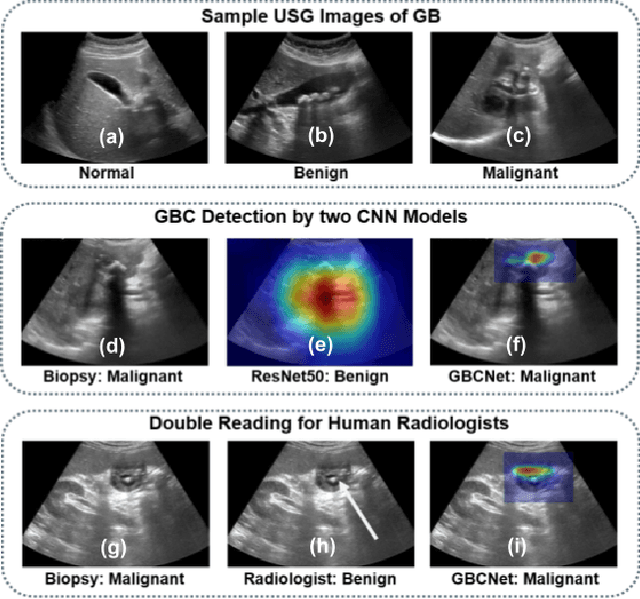
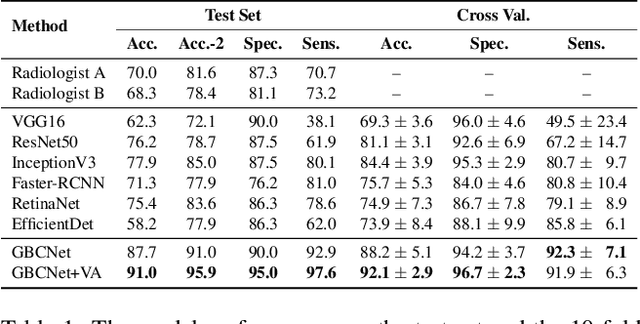

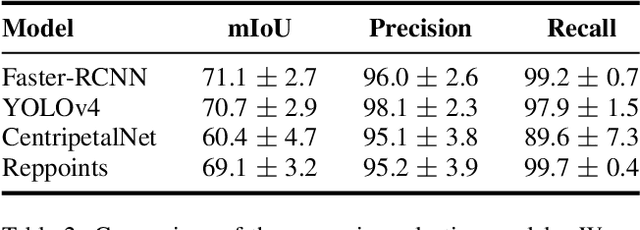
We explore the potential of CNN-based models for gallbladder cancer (GBC) detection from ultrasound (USG) images as no prior study is known. USG is the most common diagnostic modality for GB diseases due to its low cost and accessibility. However, USG images are challenging to analyze due to low image quality, noise, and varying viewpoints due to the handheld nature of the sensor. Our exhaustive study of state-of-the-art (SOTA) image classification techniques for the problem reveals that they often fail to learn the salient GB region due to the presence of shadows in the USG images. SOTA object detection techniques also achieve low accuracy because of spurious textures due to noise or adjacent organs. We propose GBCNet to tackle the challenges in our problem. GBCNet first extracts the regions of interest (ROIs) by detecting the GB (and not the cancer), and then uses a new multi-scale, second-order pooling architecture specializing in classifying GBC. To effectively handle spurious textures, we propose a curriculum inspired by human visual acuity, which reduces the texture biases in GBCNet. Experimental results demonstrate that GBCNet significantly outperforms SOTA CNN models, as well as the expert radiologists. Our technical innovations are generic to other USG image analysis tasks as well. Hence, as a validation, we also show the efficacy of GBCNet in detecting breast cancer from USG images. Project page with source code, trained models, and data is available at https://gbc-iitd.github.io/gbcnet