 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Regression for Dynamic Search Advertising
Paper and Code
Jan 20, 2020
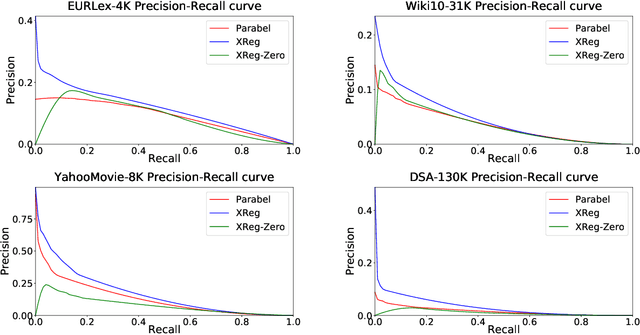
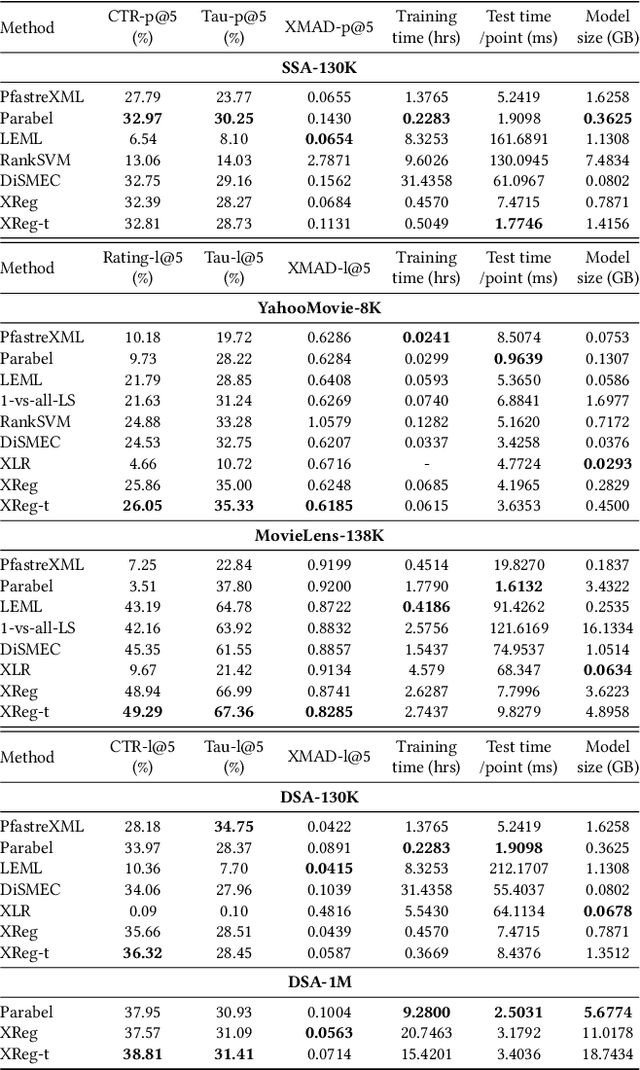
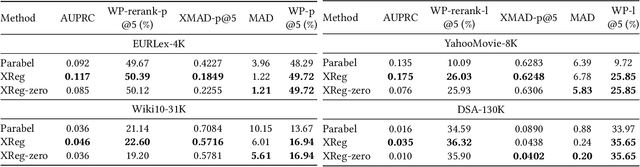
This paper introduces a new learning paradigm called eXtreme Regression (XR) whose objective is to accurately predict the numerical degrees of relevance of an extremely large number of labels to a data point. XR can provide elegant solutions to many large-scale ranking and recommendation applications including Dynamic Search Advertising (DSA). XR can learn more accurate models than the recently popular extreme classifiers which incorrectly assume strictly binary-valued label relevances. Traditional regression metrics which sum the errors over all the labels are unsuitable for XR problems since they could give extremely loose bounds for the label ranking quality. Also, the existing regression algorithms won't efficiently scale to millions of labels. This paper addresses these limitations through: (1) new evaluation metrics for XR which sum only the k largest regression errors; (2) a new algorithm called XReg which decomposes XR task into a hierarchy of much smaller regression problems thus leading to highly efficient training and prediction. This paper also introduces a (3) new labelwise prediction algorithm in XReg useful for DSA and other recommendation tasks. Experiments on benchmark datasets demonstrated that XReg can outperform the state-of-the-art extreme classifiers as well as large-scale regressors and rankers by up to 50% reduction in the new XR error metric, and up to 2% and 2.4% improvements in terms of the propensity-scored precision metric used in extreme classification and the click-through rate metric used in DSA respectively. Deployment of XReg on DSA in Bing resulted in a relative gain of 27% in query coverage. XReg's source code can be downloaded from http://manikvarma.org/code/XReg/download.html.