 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Learning to Index and Search in Large Output Spaces
Oct 16, 2022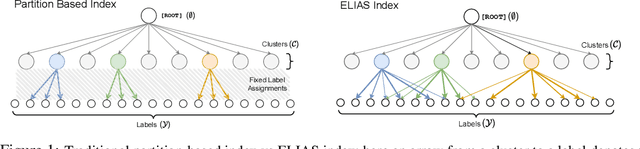
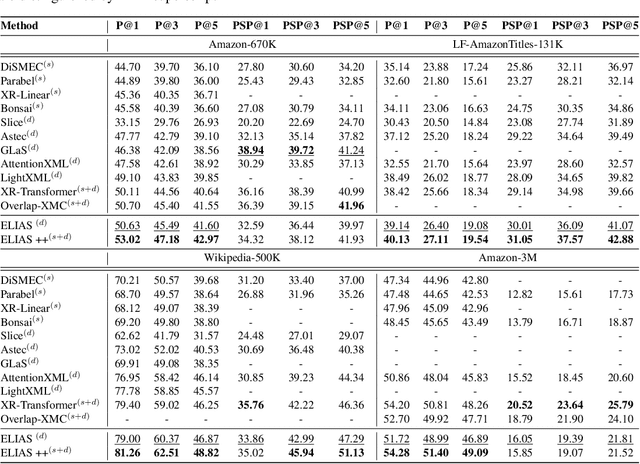
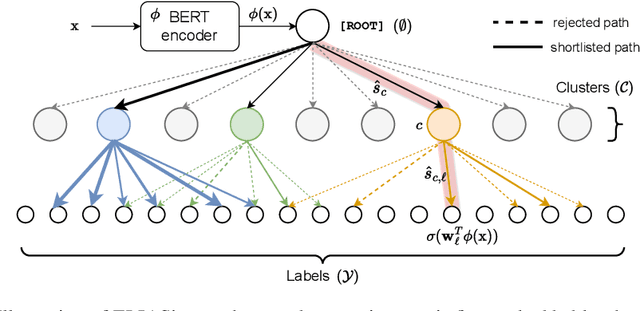
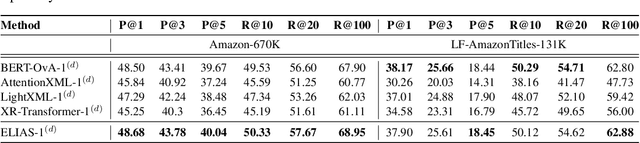
Extreme multi-label classification (XMC) is a popular framework for solving many real-world problems that require accurate prediction from a very large number of potential output choices. A popular approach for dealing with the large label space is to arrange the labels into a shallow tree-based index and then learn an ML model to efficiently search this index via beam search. Existing methods initialize the tree index by clustering the label space into a few mutually exclusive clusters based on pre-defined features and keep it fixed throughout the training procedure. This approach results in a sub-optimal indexing structure over the label space and limits the search performance to the quality of choices made during the initialization of the index. In this paper, we propose a novel method ELIAS which relaxes the tree-based index to a specialized weighted graph-based index which is learned end-to-end with the final task objective. More specifically, ELIAS models the discrete cluster-to-label assignments in the existing tree-based index as soft learnable parameters that are learned jointly with the rest of the ML model. ELIAS achieves state-of-the-art performance on several large-scale extreme classification benchmarks with millions of labels. In particular, ELIAS can be up to 2.5% better at precision@1 and up to 4% better at recall@100 than existing XMC methods. A PyTorch implementation of ELIAS along with other resources is available at https://github.com/nilesh2797/ELIAS.
FINGER: Fast Inference for Graph-based Approximate Nearest Neighbor Search
Jun 22, 2022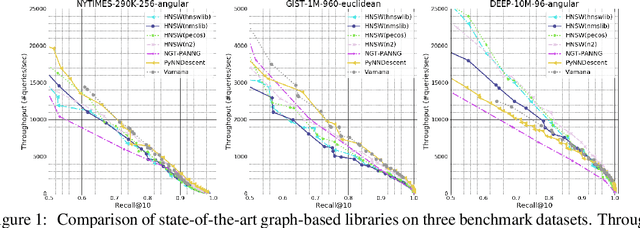
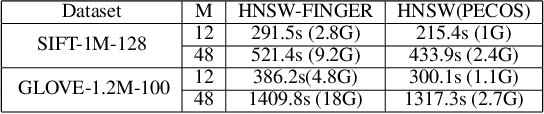
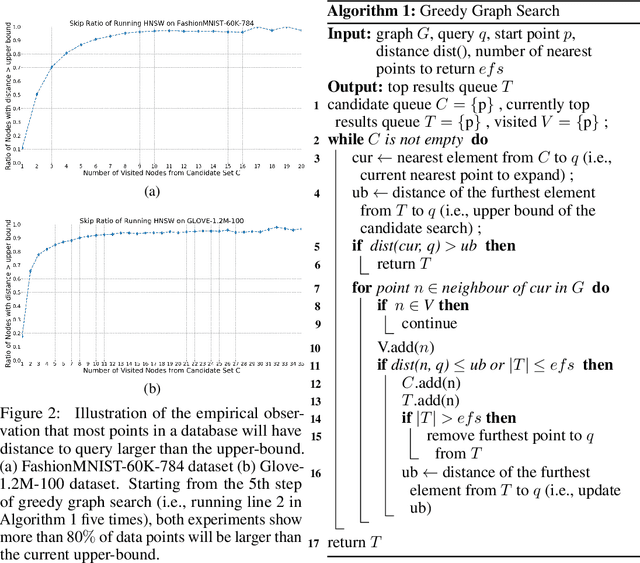
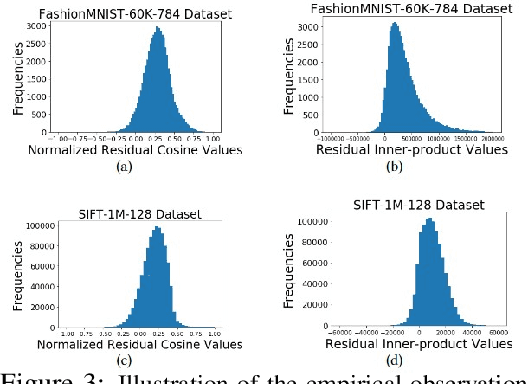
Approximate K-Nearest Neighbor Search (AKNNS) has now become ubiquitous in modern applications, for example, as a fast search procedure with two tower deep learning models. Graph-based methods for AKNNS in particular have received great attention due to their superior performance. These methods rely on greedy graph search to traverse the data points as embedding vectors in a database. Under this greedy search scheme, we make a key observation: many distance computations do not influence search updates so these computations can be approximated without hurting performance. As a result, we propose FINGER, a fast inference method to achieve efficient graph search. FINGER approximates the distance function by estimating angles between neighboring residual vectors with low-rank bases and distribution matching. The approximated distance can be used to bypass unnecessary computations, which leads to faster searches. Empirically, accelerating a popular graph-based method named HNSW by FINGER is shown to outperform existing graph-based methods by 20%-60% across different benchmark datasets.
Overcoming Catastrophic Forgetting by Generative Regularization
Dec 03, 2019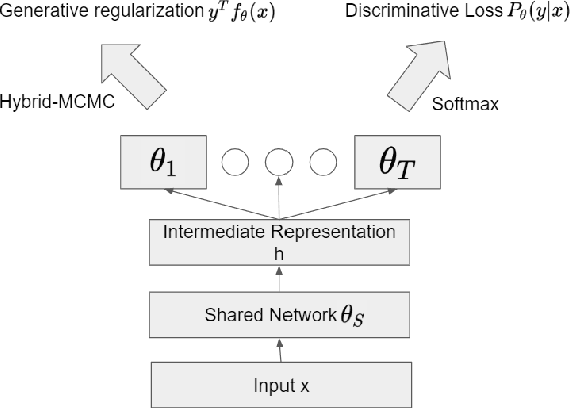
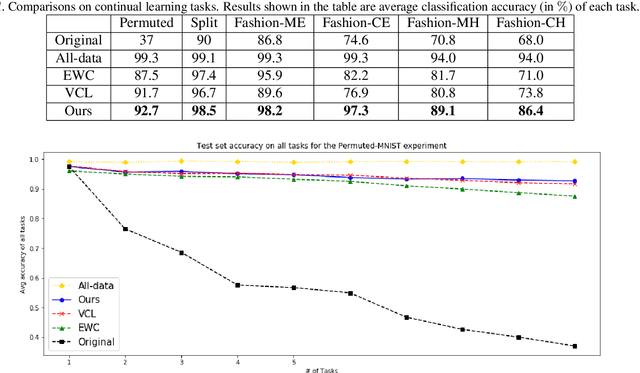
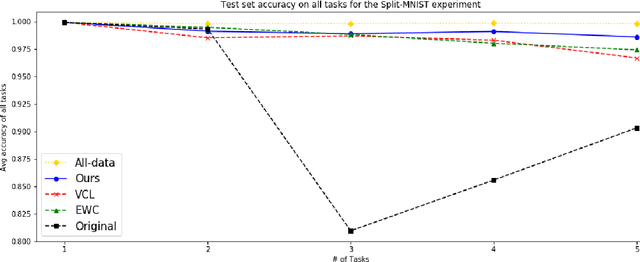
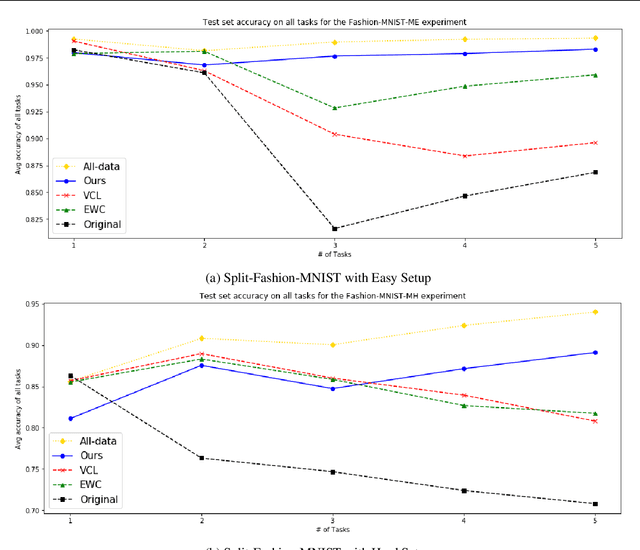
In this paper, we propose a new method to overcome catastrophic forgetting by adding generative regularization to Bayesian inference framework. We could construct generative regularization term for all given models by leveraging Energy-based models and Langevin-Dynamic sampling. By combining discriminative and generative loss together, we show that this intuitively provides a better posterior formulation in Bayesian inference. Experimental results show that the proposed method outperforms state of-the-art methods on a variety of tasks, avoiding catastrophic forgetting in continual learning. In particular, the proposed method outperforms previous methos over 10$\%$ in Fashion-MNIST dataset.
Efficient Contextual Representation Learning Without Softmax Layer
Feb 28, 2019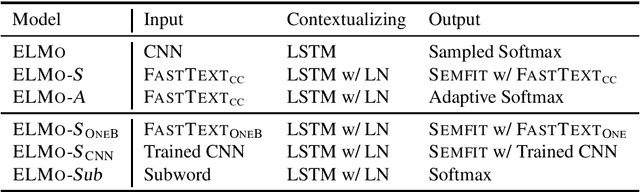



Contextual representation models have achieved great success in improving various downstream tasks. However, these language-model-based encoders are difficult to train due to the large parameter sizes and high computational complexity. By carefully examining the training procedure, we find that the softmax layer (the output layer) causes significant inefficiency due to the large vocabulary size. Therefore, we redesign the learning objective and propose an efficient framework for training contextual representation models. Specifically, the proposed approach bypasses the softmax layer by performing language modeling with dimension reduction, and allows the models to leverage pre-trained word embeddings. Our framework reduces the time spent on the output layer to a negligible level, eliminates almost all the trainable parameters of the softmax layer and performs language modeling without truncating the vocabulary. When applied to ELMo, our method achieves a 4 times speedup and eliminates 80% trainable parameters while achieving competitive performance on downstream tasks.
Learning to Screen for Fast Softmax Inference on Large Vocabulary Neural Networks
Oct 29, 2018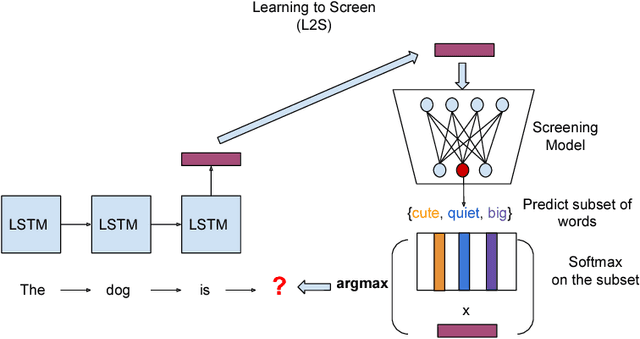

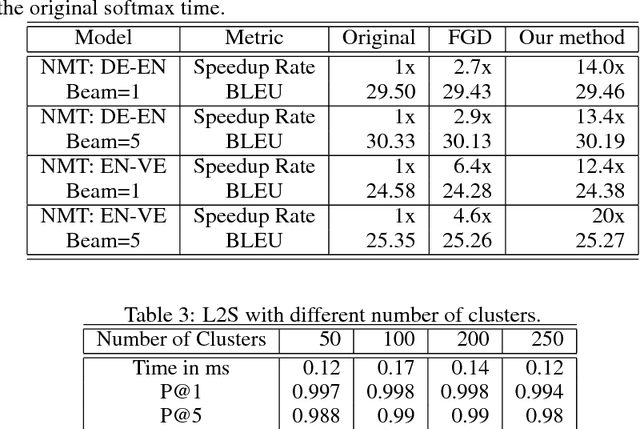
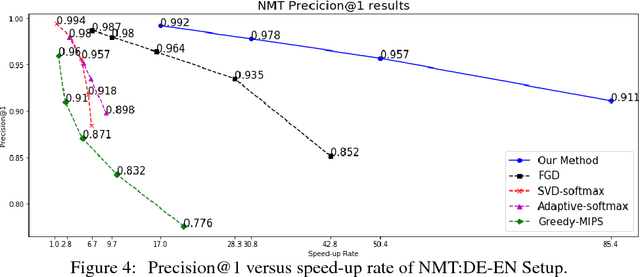
Neural language models have been widely used in various NLP tasks, including machine translation, next word prediction and conversational agents. However, it is challenging to deploy these models on mobile devices due to their slow prediction speed, where the bottleneck is to compute top candidates in the softmax layer. In this paper, we introduce a novel softmax layer approximation algorithm by exploiting the clustering structure of context vectors. Our algorithm uses a light-weight screening model to predict a much smaller set of candidate words based on the given context, and then conducts an exact softmax only within that subset. Training such a procedure end-to-end is challenging as traditional clustering methods are discrete and non-differentiable, and thus unable to be used with back-propagation in the training process. Using the Gumbel softmax, we are able to train the screening model end-to-end on the training set to exploit data distribution. The algorithm achieves an order of magnitude faster inference than the original softmax layer for predicting top-$k$ words in various tasks such as beam search in machine translation or next words prediction. For example, for machine translation task on German to English dataset with around 25K vocabulary, we can achieve 20.4 times speed up with 98.9\% precision@1 and 99.3\% precision@5 with the original softmax layer prediction, while state-of-the-art ~\citep{MSRprediction} only achieves 6.7x speedup with 98.7\% precision@1 and 98.1\% precision@5 for the same task.
GroupReduce: Block-Wise Low-Rank Approximation for Neural Language Model Shrinking
Jun 18, 2018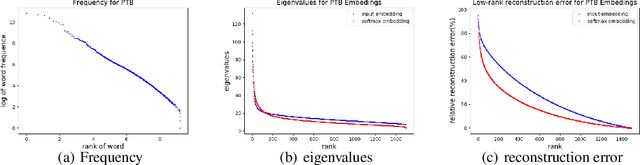

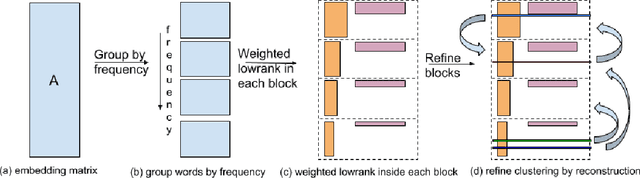
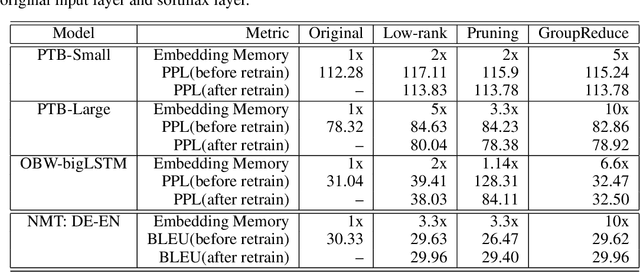
Model compression is essential for serving large deep neural nets on devices with limited resources or applications that require real-time responses. As a case study, a state-of-the-art neural language model usually consists of one or more recurrent layers sandwiched between an embedding layer used for representing input tokens and a softmax layer for generating output tokens. For problems with a very large vocabulary size, the embedding and the softmax matrices can account for more than half of the model size. For instance, the bigLSTM model achieves state-of- the-art performance on the One-Billion-Word (OBW) dataset with around 800k vocabulary, and its word embedding and softmax matrices use more than 6GBytes space, and are responsible for over 90% of the model parameters. In this paper, we propose GroupReduce, a novel compression method for neural language models, based on vocabulary-partition (block) based low-rank matrix approximation and the inherent frequency distribution of tokens (the power-law distribution of words). The experimental results show our method can significantly outperform traditional compression methods such as low-rank approximation and pruning. On the OBW dataset, our method achieved 6.6 times compression rate for the embedding and softmax matrices, and when combined with quantization, our method can achieve 26 times compression rate, which translates to a factor of 12.8 times compression for the entire model with very little degradation in perplexity.