 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaDistiller: Network Self-Boosting via Meta-Learned Top-Down Distillation
Aug 27, 2020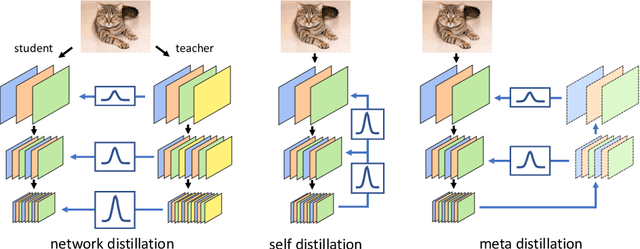
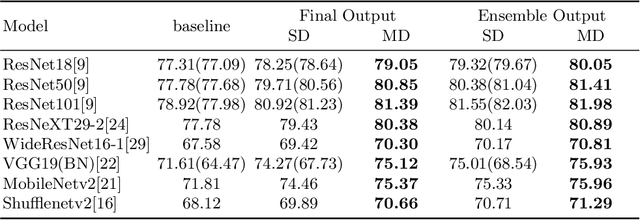
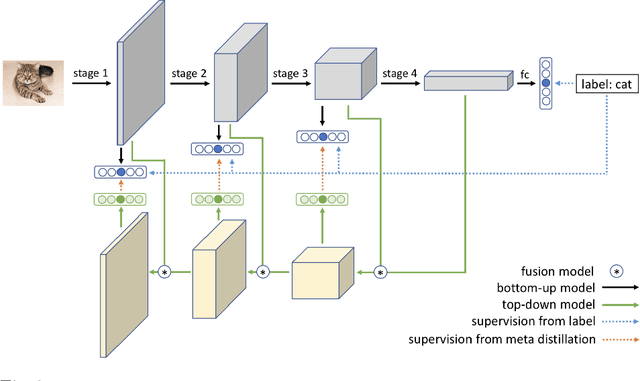

Knowledge Distillation (KD) has been one of the most popu-lar methods to learn a compact model. However, it still suffers from highdemand in time and computational resources caused by sequential train-ing pipeline. Furthermore, the soft targets from deeper models do notoften serve as good cues for the shallower models due to the gap of com-patibility. In this work, we consider these two problems at the same time.Specifically, we propose that better soft targets with higher compatibil-ity can be generated by using a label generator to fuse the feature mapsfrom deeper stages in a top-down manner, and we can employ the meta-learning technique to optimize this label generator. Utilizing the softtargets learned from the intermediate feature maps of the model, we canachieve better self-boosting of the network in comparison with the state-of-the-art. The experiments are conducted on two standard classificationbenchmarks, namely CIFAR-100 and ILSVRC2012. We test various net-work architectures to show the generalizability of our MetaDistiller. Theexperiments results on two datasets strongly demonstrate the effective-ness of our method.
GroupReduce: Block-Wise Low-Rank Approximation for Neural Language Model Shrinking
Jun 18, 2018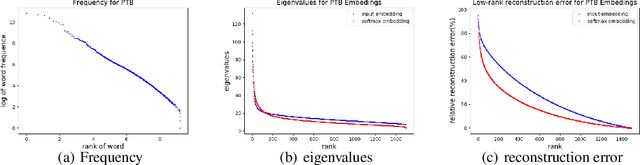

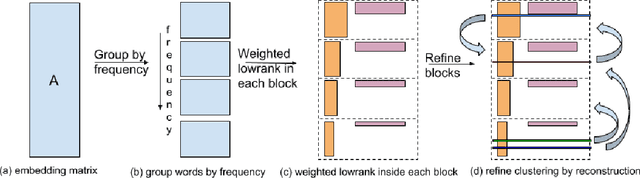
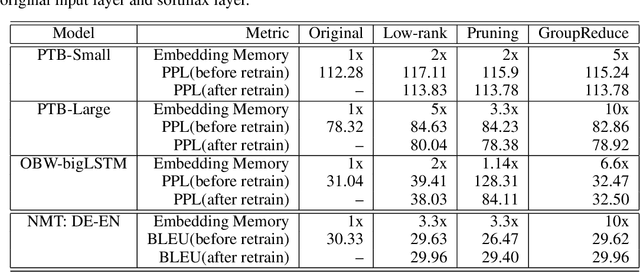
Model compression is essential for serving large deep neural nets on devices with limited resources or applications that require real-time responses. As a case study, a state-of-the-art neural language model usually consists of one or more recurrent layers sandwiched between an embedding layer used for representing input tokens and a softmax layer for generating output tokens. For problems with a very large vocabulary size, the embedding and the softmax matrices can account for more than half of the model size. For instance, the bigLSTM model achieves state-of- the-art performance on the One-Billion-Word (OBW) dataset with around 800k vocabulary, and its word embedding and softmax matrices use more than 6GBytes space, and are responsible for over 90% of the model parameters. In this paper, we propose GroupReduce, a novel compression method for neural language models, based on vocabulary-partition (block) based low-rank matrix approximation and the inherent frequency distribution of tokens (the power-law distribution of words). The experimental results show our method can significantly outperform traditional compression methods such as low-rank approximation and pruning. On the OBW dataset, our method achieved 6.6 times compression rate for the embedding and softmax matrices, and when combined with quantization, our method can achieve 26 times compression rate, which translates to a factor of 12.8 times compression for the entire model with very little degradation in perplexity.