 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWISER: Weak supervISion and supErvised Representation learning to improve drug response prediction in cancer
May 07, 2024Cancer, a leading cause of death globally, occurs due to genomic changes and manifests heterogeneously across patients. To advance research on personalized treatment strategies, the effectiveness of various drugs on cells derived from cancers (`cell lines') is experimentally determined in laboratory settings. Nevertheless, variations in the distribution of genomic data and drug responses between cell lines and humans arise due to biological and environmental differences. Moreover, while genomic profiles of many cancer patients are readily available, the scarcity of corresponding drug response data limits the ability to train machine learning models that can predict drug response in patients effectively. Recent cancer drug response prediction methods have largely followed the paradigm of unsupervised domain-invariant representation learning followed by a downstream drug response classification step. Introducing supervision in both stages is challenging due to heterogeneous patient response to drugs and limited drug response data. This paper addresses these challenges through a novel representation learning method in the first phase and weak supervision in the second. Experimental results on real patient data demonstrate the efficacy of our method (WISER) over state-of-the-art alternatives on predicting personalized drug response.
Personalised Drug Identifier for Cancer Treatment with Transformers using Auxiliary Information
Feb 16, 2024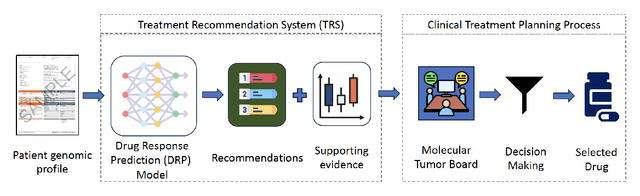
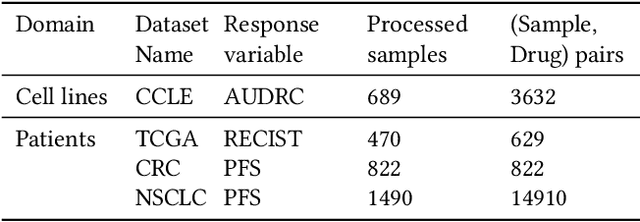
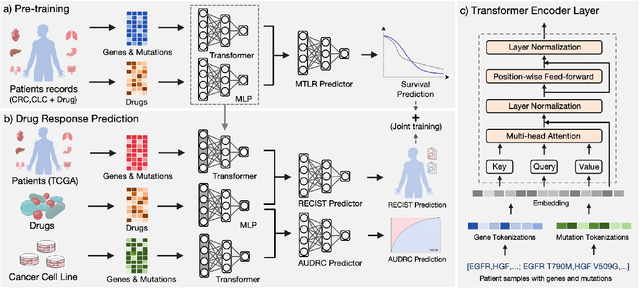
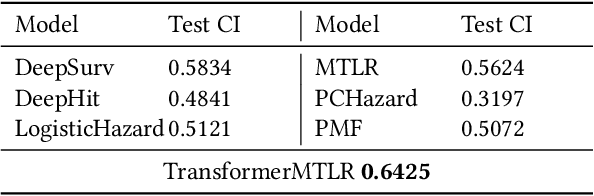
Cancer remains a global challenge due to its growing clinical and economic burden. Its uniquely personal manifestation, which makes treatment difficult, has fuelled the quest for personalized treatment strategies. Thus, genomic profiling is increasingly becoming part of clinical diagnostic panels. Effective use of such panels requires accurate drug response prediction (DRP) models, which are challenging to build due to limited labelled patient data. Previous methods to address this problem have used various forms of transfer learning. However, they do not explicitly model the variable length sequential structure of the list of mutations in such diagnostic panels. Further, they do not utilize auxiliary information (like patient survival) for model training. We address these limitations through a novel transformer based method, which surpasses the performance of state-of-the-art DRP models on benchmark data. We also present the design of a treatment recommendation system (TRS), which is currently deployed at the National University Hospital, Singapore and is being evaluated in a clinical trial.
Multimodal Representation Learning With Text and Images
Apr 30, 2022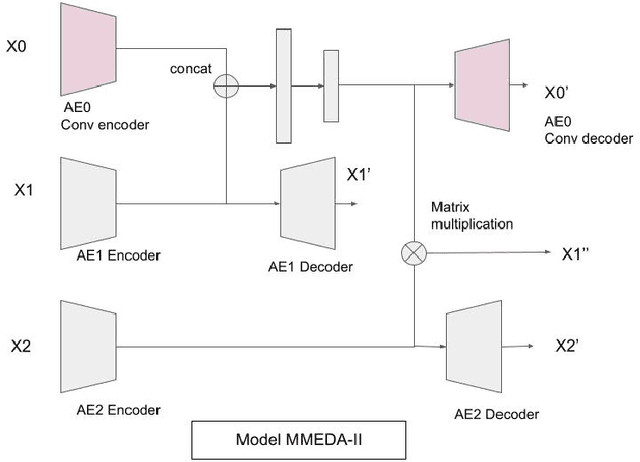
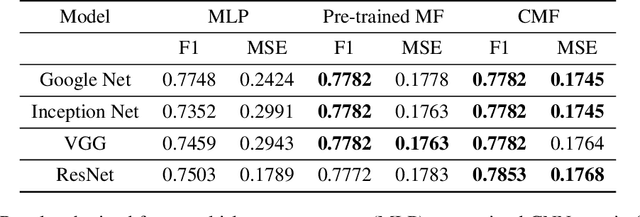
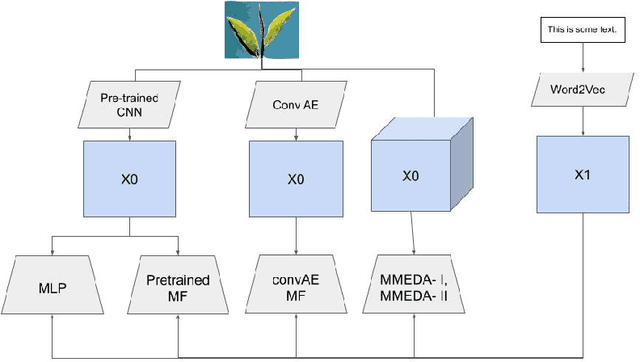
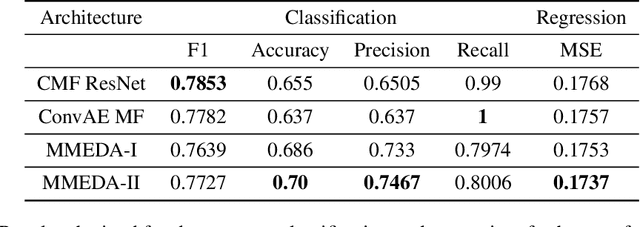
In recent years, multimodal AI has seen an upward trend as researchers are integrating data of different types such as text, images, speech into modelling to get the best results. This project leverages multimodal AI and matrix factorization techniques for representation learning, on text and image data simultaneously, thereby employing the widely used techniques of Natural Language Processing (NLP) and Computer Vision. The learnt representations are evaluated using downstream classification and regression tasks. The methodology adopted can be extended beyond the scope of this project as it uses Auto-Encoders for unsupervised representation learning.