Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Representation Learning With Text and Images
Apr 30, 2022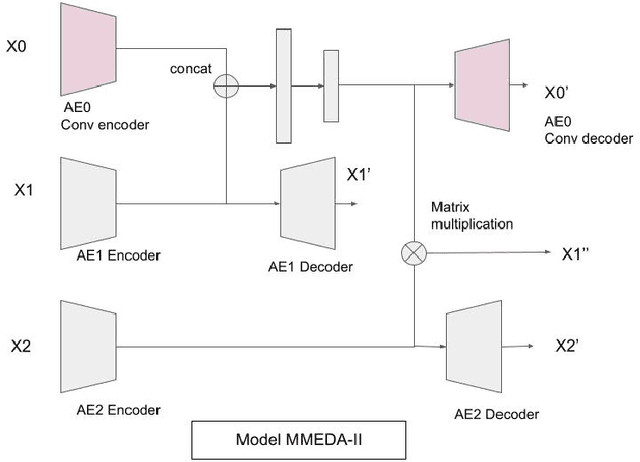
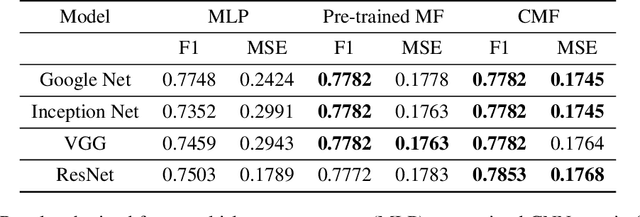
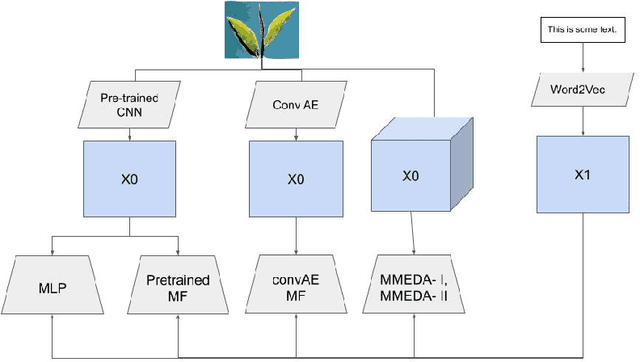
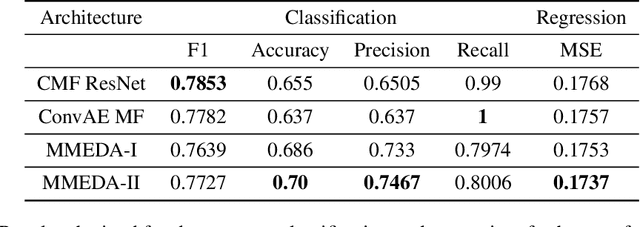
In recent years, multimodal AI has seen an upward trend as researchers are integrating data of different types such as text, images, speech into modelling to get the best results. This project leverages multimodal AI and matrix factorization techniques for representation learning, on text and image data simultaneously, thereby employing the widely used techniques of Natural Language Processing (NLP) and Computer Vision. The learnt representations are evaluated using downstream classification and regression tasks. The methodology adopted can be extended beyond the scope of this project as it uses Auto-Encoders for unsupervised representation learning.
Via