 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenetic Algorithm-Based Dynamic Backdoor Attack on Federated Learning-Based Network Traffic Classification
Sep 27, 2023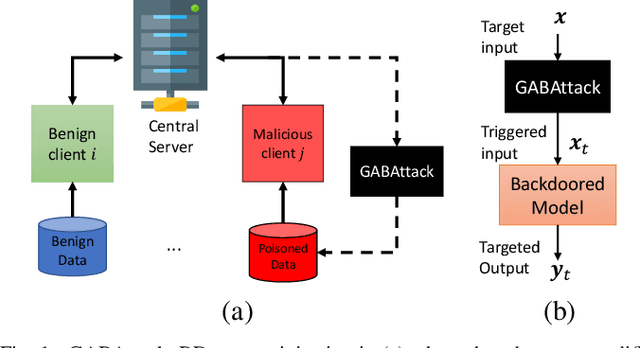
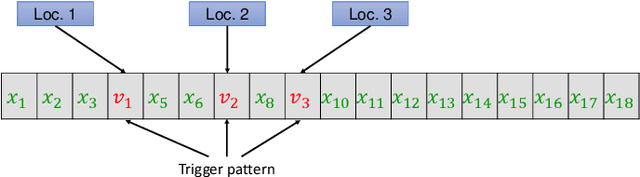
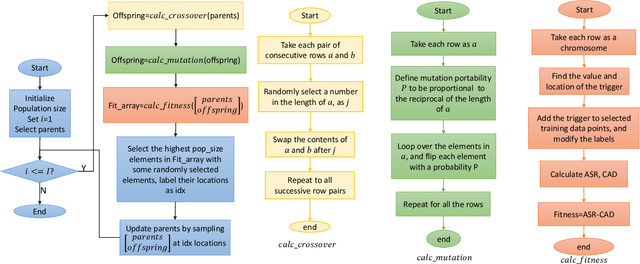
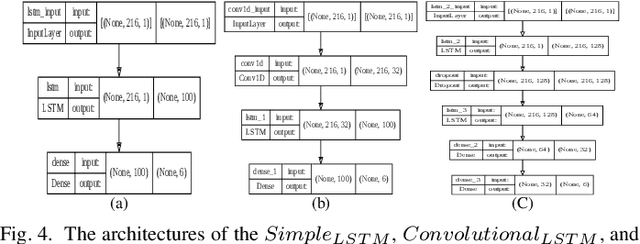
Federated learning enables multiple clients to collaboratively contribute to the learning of a global model orchestrated by a central server. This learning scheme promotes clients' data privacy and requires reduced communication overheads. In an application like network traffic classification, this helps hide the network vulnerabilities and weakness points. However, federated learning is susceptible to backdoor attacks, in which adversaries inject manipulated model updates into the global model. These updates inject a salient functionality in the global model that can be launched with specific input patterns. Nonetheless, the vulnerability of network traffic classification models based on federated learning to these attacks remains unexplored. In this paper, we propose GABAttack, a novel genetic algorithm-based backdoor attack against federated learning for network traffic classification. GABAttack utilizes a genetic algorithm to optimize the values and locations of backdoor trigger patterns, ensuring a better fit with the input and the model. This input-tailored dynamic attack is promising for improved attack evasiveness while being effective. Extensive experiments conducted over real-world network datasets validate the success of the proposed GABAttack in various situations while maintaining almost invisible activity. This research serves as an alarming call for network security experts and practitioners to develop robust defense measures against such attacks.
ManiGen: A Manifold Aided Black-box Generator of Adversarial Examples
Jul 11, 2020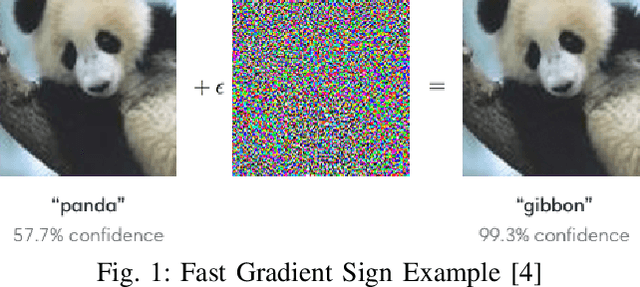


Machine learning models, especially neural network (NN) classifiers, have acceptable performance and accuracy that leads to their wide adoption in different aspects of our daily lives. The underlying assumption is that these models are generated and used in attack free scenarios. However, it has been shown that neural network based classifiers are vulnerable to adversarial examples. Adversarial examples are inputs with special perturbations that are ignored by human eyes while can mislead NN classifiers. Most of the existing methods for generating such perturbations require a certain level of knowledge about the target classifier, which makes them not very practical. For example, some generators require knowledge of pre-softmax logits while others utilize prediction scores. In this paper, we design a practical black-box adversarial example generator, dubbed ManiGen. ManiGen does not require any knowledge of the inner state of the target classifier. It generates adversarial examples by searching along the manifold, which is a concise representation of input data. Through extensive set of experiments on different datasets, we show that (1) adversarial examples generated by ManiGen can mislead standalone classifiers by being as successful as the state-of-the-art white-box generator, Carlini, and (2) adversarial examples generated by ManiGen can more effectively attack classifiers with state-of-the-art defenses.