 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDI-MaskDINO: A Joint Object Detection and Instance Segmentation Model
Paper and Code
Oct 22, 2024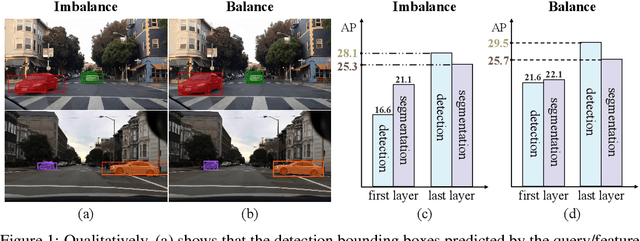
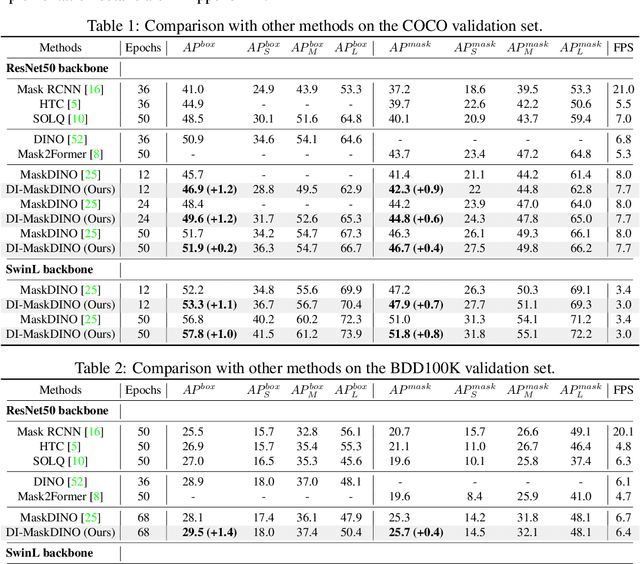
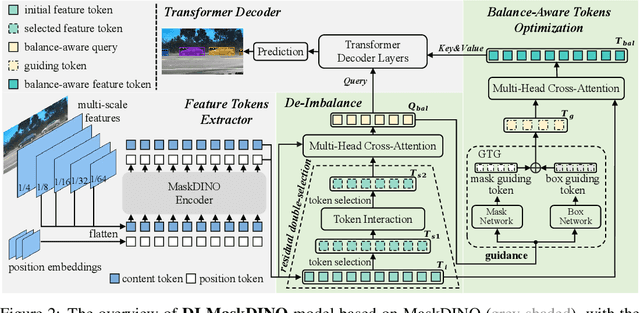
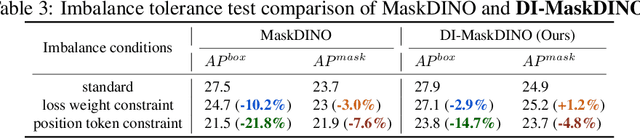
This paper is motivated by an interesting phenomenon: the performance of object detection lags behind that of instance segmentation (i.e., performance imbalance) when investigating the intermediate results from the beginning transformer decoder layer of MaskDINO (i.e., the SOTA model for joint detection and segmentation). This phenomenon inspires us to think about a question: will the performance imbalance at the beginning layer of transformer decoder constrain the upper bound of the final performance? With this question in mind, we further conduct qualitative and quantitative pre-experiments, which validate the negative impact of detection-segmentation imbalance issue on the model performance. To address this issue, this paper proposes DI-MaskDINO model, the core idea of which is to improve the final performance by alleviating the detection-segmentation imbalance. DI-MaskDINO is implemented by configuring our proposed De-Imbalance (DI) module and Balance-Aware Tokens Optimization (BATO) module to MaskDINO. DI is responsible for generating balance-aware query, and BATO uses the balance-aware query to guide the optimization of the initial feature tokens. The balance-aware query and optimized feature tokens are respectively taken as the Query and Key&Value of transformer decoder to perform joint object detection and instance segmentation. DI-MaskDINO outperforms existing joint object detection and instance segmentation models on COCO and BDD100K benchmarks, achieving +1.2 $AP^{box}$ and +0.9 $AP^{mask}$ improvements compared to SOTA joint detection and segmentation model MaskDINO. In addition, DI-MaskDINO also obtains +1.0 $AP^{box}$ improvement compared to SOTA object detection model DINO and +3.0 $AP^{mask}$ improvement compared to SOTA segmentation model Mask2Former.