 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyTouch 2: General Optical Tactile Representation Learning For Dynamic Tactile Perception
Feb 10, 2026Real-world contact-rich manipulation demands robots to perceive temporal tactile feedback, capture subtle surface deformations, and reason about object properties as well as force dynamics. Although optical tactile sensors are uniquely capable of providing such rich information, existing tactile datasets and models remain limited. These resources primarily focus on object-level attributes (e.g., material) while largely overlooking fine-grained tactile temporal dynamics during physical interactions. We consider that advancing dynamic tactile perception requires a systematic hierarchy of dynamic perception capabilities to guide both data collection and model design. To address the lack of tactile data with rich dynamic information, we present ToucHD, a large-scale hierarchical tactile dataset spanning tactile atomic actions, real-world manipulations, and touch-force paired data. Beyond scale, ToucHD establishes a comprehensive tactile dynamic data ecosystem that explicitly supports hierarchical perception capabilities from the data perspective. Building on it, we propose AnyTouch 2, a general tactile representation learning framework for diverse optical tactile sensors that unifies object-level understanding with fine-grained, force-aware dynamic perception. The framework captures both pixel-level and action-specific deformations across frames, while explicitly modeling physical force dynamics, thereby learning multi-level dynamic perception capabilities from the model perspective. We evaluate our model on benchmarks that covers static object properties and dynamic physical attributes, as well as real-world manipulation tasks spanning multiple tiers of dynamic perception capabilities-from basic object-level understanding to force-aware dexterous manipulation. Experimental results demonstrate consistent and strong performance across sensors and tasks.
Phoenix: A Motion-based Self-Reflection Framework for Fine-grained Robotic Action Correction
Apr 20, 2025



Building a generalizable self-correction system is crucial for robots to recover from failures. Despite advancements in Multimodal Large Language Models (MLLMs) that empower robots with semantic reflection ability for failure, translating semantic reflection into how to correct fine-grained robotic actions remains a significant challenge. To address this gap, we build the Phoenix framework, which leverages motion instruction as a bridge to connect high-level semantic reflection with low-level robotic action correction. In this motion-based self-reflection framework, we start with a dual-process motion adjustment mechanism with MLLMs to translate the semantic reflection into coarse-grained motion instruction adjustment. To leverage this motion instruction for guiding how to correct fine-grained robotic actions, a multi-task motion-conditioned diffusion policy is proposed to integrate visual observations for high-frequency robotic action correction. By combining these two models, we could shift the demand for generalization capability from the low-level manipulation policy to the MLLMs-driven motion adjustment model and facilitate precise, fine-grained robotic action correction. Utilizing this framework, we further develop a lifelong learning method to automatically improve the model's capability from interactions with dynamic environments. The experiments conducted in both the RoboMimic simulation and real-world scenarios prove the superior generalization and robustness of our framework across a variety of manipulation tasks. Our code is released at \href{https://github.com/GeWu-Lab/Motion-based-Self-Reflection-Framework}{https://github.com/GeWu-Lab/Motion-based-Self-Reflection-Framework}.
Play to the Score: Stage-Guided Dynamic Multi-Sensory Fusion for Robotic Manipulation
Aug 02, 2024



Humans possess a remarkable talent for flexibly alternating to different senses when interacting with the environment. Picture a chef skillfully gauging the timing of ingredient additions and controlling the heat according to the colors, sounds, and aromas, seamlessly navigating through every stage of the complex cooking process. This ability is founded upon a thorough comprehension of task stages, as achieving the sub-goal within each stage can necessitate the utilization of different senses. In order to endow robots with similar ability, we incorporate the task stages divided by sub-goals into the imitation learning process to accordingly guide dynamic multi-sensory fusion. We propose MS-Bot, a stage-guided dynamic multi-sensory fusion method with coarse-to-fine stage understanding, which dynamically adjusts the priority of modalities based on the fine-grained state within the predicted current stage. We train a robot system equipped with visual, auditory, and tactile sensors to accomplish challenging robotic manipulation tasks: pouring and peg insertion with keyway. Experimental results indicate that our approach enables more effective and explainable dynamic fusion, aligning more closely with the human fusion process than existing methods.
Diagnosing and Re-learning for Balanced Multimodal Learning
Jul 12, 2024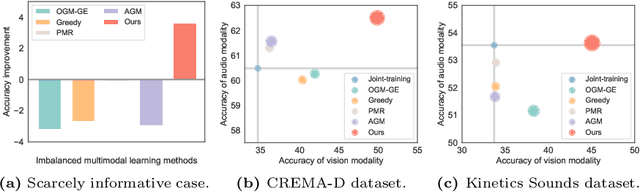
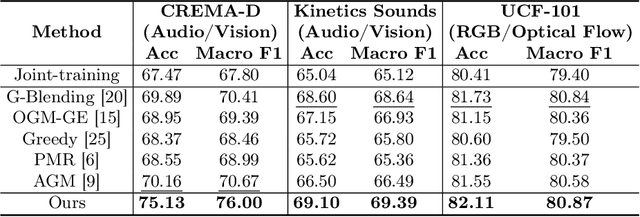
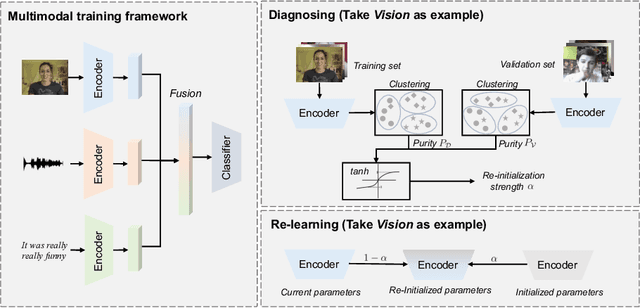
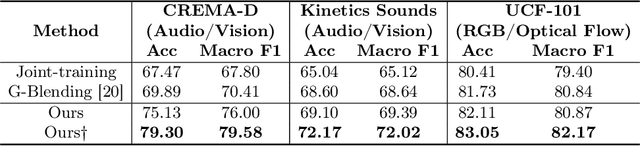
To overcome the imbalanced multimodal learning problem, where models prefer the training of specific modalities, existing methods propose to control the training of uni-modal encoders from different perspectives, taking the inter-modal performance discrepancy as the basis. However, the intrinsic limitation of modality capacity is ignored. The scarcely informative modalities can be recognized as ``worse-learnt'' ones, which could force the model to memorize more noise, counterproductively affecting the multimodal model ability. Moreover, the current modality modulation methods narrowly concentrate on selected worse-learnt modalities, even suppressing the training of others. Hence, it is essential to consider the intrinsic limitation of modality capacity and take all modalities into account during balancing. To this end, we propose the Diagnosing \& Re-learning method. The learning state of each modality is firstly estimated based on the separability of its uni-modal representation space, and then used to softly re-initialize the corresponding uni-modal encoder. In this way, the over-emphasizing of scarcely informative modalities is avoided. In addition, encoders of worse-learnt modalities are enhanced, simultaneously avoiding the over-training of other modalities. Accordingly, multimodal learning is effectively balanced and enhanced. Experiments covering multiple types of modalities and multimodal frameworks demonstrate the superior performance of our simple-yet-effective method for balanced multimodal learning. The source code and dataset are available at \url{https://github.com/GeWu-Lab/Diagnosing_Relearning_ECCV2024}.
Enhancing Multi-modal Cooperation via Fine-grained Modality Valuation
Sep 12, 2023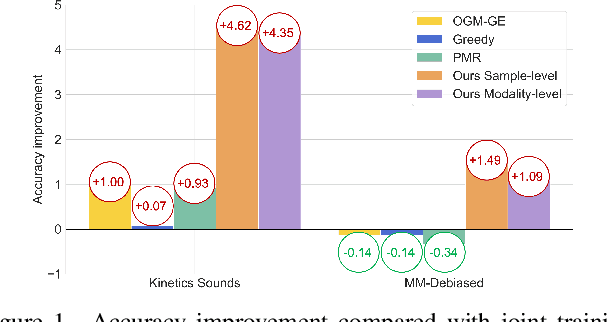
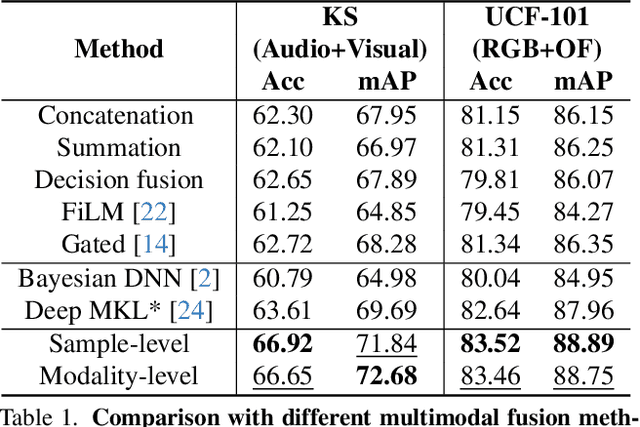
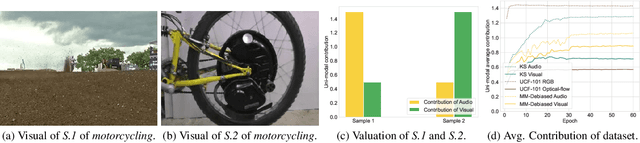
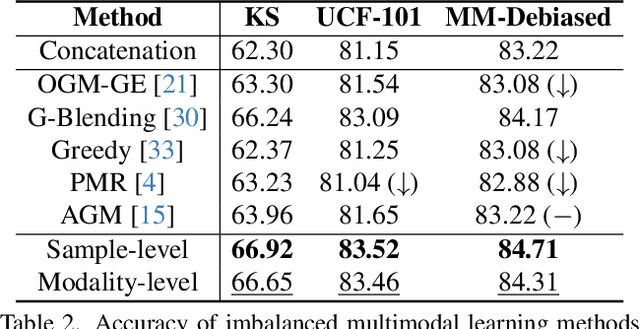
One primary topic of multi-modal learning is to jointly incorporate heterogeneous information from different modalities. However, most models often suffer from unsatisfactory multi-modal cooperation, which could not jointly utilize all modalities well. Some methods are proposed to identify and enhance the worse learnt modality, but are often hard to provide the fine-grained observation of multi-modal cooperation at sample-level with theoretical support. Hence, it is essential to reasonably observe and improve the fine-grained cooperation between modalities, especially when facing realistic scenarios where the modality discrepancy could vary across different samples. To this end, we introduce a fine-grained modality valuation metric to evaluate the contribution of each modality at sample-level. Via modality valuation, we regretfully observe that the multi-modal model tends to rely on one specific modality, resulting in other modalities being low-contributing. We further analyze this issue and improve cooperation between modalities by enhancing the discriminative ability of low-contributing modalities in a targeted manner. Overall, our methods reasonably observe the fine-grained uni-modal contribution at sample-level and achieve considerable improvement on different multi-modal models.
MMCosine: Multi-Modal Cosine Loss Towards Balanced Audio-Visual Fine-Grained Learning
Mar 11, 2023Audio-visual learning helps to comprehensively understand the world by fusing practical information from multiple modalities. However, recent studies show that the imbalanced optimization of uni-modal encoders in a joint-learning model is a bottleneck to enhancing the model's performance. We further find that the up-to-date imbalance-mitigating methods fail on some audio-visual fine-grained tasks, which have a higher demand for distinguishable feature distribution. Fueled by the success of cosine loss that builds hyperspherical feature spaces and achieves lower intra-class angular variability, this paper proposes Multi-Modal Cosine loss, MMCosine. It performs a modality-wise $L_2$ normalization to features and weights towards balanced and better multi-modal fine-grained learning. We demonstrate that our method can alleviate the imbalanced optimization from the perspective of weight norm and fully exploit the discriminability of the cosine metric. Extensive experiments prove the effectiveness of our method and the versatility with advanced multi-modal fusion strategies and up-to-date imbalance-mitigating methods.
Revisiting Pre-training in Audio-Visual Learning
Feb 17, 2023Pre-training technique has gained tremendous success in enhancing model performance on various tasks, but found to perform worse than training from scratch in some uni-modal situations. This inspires us to think: are the pre-trained models always effective in the more complex multi-modal scenario, especially for the heterogeneous modalities such as audio and visual ones? We find that the answer is No. Specifically, we explore the effects of pre-trained models on two audio-visual learning scenarios: cross-modal initialization and multi-modal joint learning. When cross-modal initialization is applied, the phenomena of "dead channel" caused by abnormal Batchnorm parameters hinders the utilization of model capacity. Thus, we propose Adaptive Batchnorm Re-initialization (ABRi) to better exploit the capacity of pre-trained models for target tasks. In multi-modal joint learning, we find a strong pre-trained uni-modal encoder would bring negative effects on the encoder of another modality. To alleviate such problem, we introduce a two-stage Fusion Tuning strategy, taking better advantage of the pre-trained knowledge while making the uni-modal encoders cooperate with an adaptive masking method. The experiment results show that our methods could further exploit pre-trained models' potential and boost performance in audio-visual learning.