 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Unimodal Regulation for Balanced Multimodal Information Acquisition
Mar 24, 2025Sensory training during the early ages is vital for human development. Inspired by this cognitive phenomenon, we observe that the early training stage is also important for the multimodal learning process, where dataset information is rapidly acquired. We refer to this stage as the prime learning window. However, based on our observation, this prime learning window in multimodal learning is often dominated by information-sufficient modalities, which in turn suppresses the information acquisition of information-insufficient modalities. To address this issue, we propose Information Acquisition Regulation (InfoReg), a method designed to balance information acquisition among modalities. Specifically, InfoReg slows down the information acquisition process of information-sufficient modalities during the prime learning window, which could promote information acquisition of information-insufficient modalities. This regulation enables a more balanced learning process and improves the overall performance of the multimodal network. Experiments show that InfoReg outperforms related multimodal imbalanced methods across various datasets, achieving superior model performance. The code is available at https://github.com/GeWu-Lab/InfoReg_CVPR2025.
Quantifying and Enhancing Multi-modal Robustness with Modality Preference
Feb 09, 2024Multi-modal models have shown a promising capability to effectively integrate information from various sources, yet meanwhile, they are found vulnerable to pervasive perturbations, such as uni-modal attacks and missing conditions. To counter these perturbations, robust multi-modal representations are highly expected, which are positioned well away from the discriminative multi-modal decision boundary. In this paper, different from conventional empirical studies, we focus on a commonly used joint multi-modal framework and theoretically discover that larger uni-modal representation margins and more reliable integration for modalities are essential components for achieving higher robustness. This discovery can further explain the limitation of multi-modal robustness and the phenomenon that multi-modal models are often vulnerable to attacks on the specific modality. Moreover, our analysis reveals how the widespread issue, that the model has different preferences for modalities, limits the multi-modal robustness by influencing the essential components and could lead to attacks on the specific modality highly effective. Inspired by our theoretical finding, we introduce a training procedure called Certifiable Robust Multi-modal Training (CRMT), which can alleviate this influence from modality preference and explicitly regulate essential components to significantly improve robustness in a certifiable manner. Our method demonstrates substantial improvements in performance and robustness compared with existing methods. Furthermore, our training procedure can be easily extended to enhance other robust training strategies, highlighting its credibility and flexibility.
Reasoning with Multi-Structure Commonsense Knowledge in Visual Dialog
Apr 10, 2022
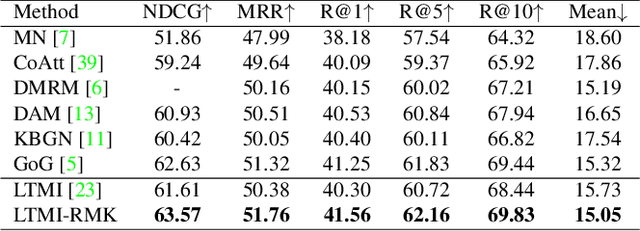
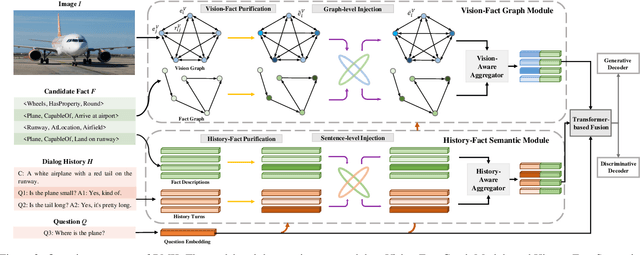
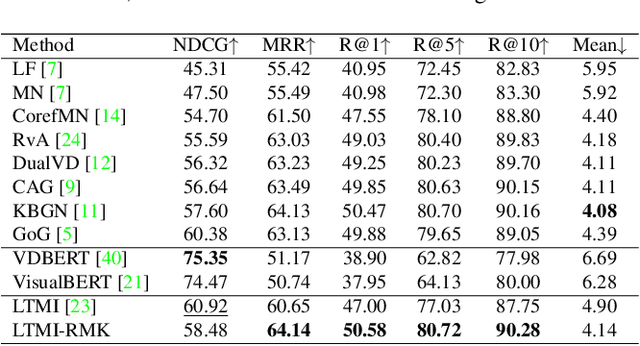
Visual Dialog requires an agent to engage in a conversation with humans grounded in an image. Many studies on Visual Dialog focus on the understanding of the dialog history or the content of an image, while a considerable amount of commonsense-required questions are ignored. Handling these scenarios depends on logical reasoning that requires commonsense priors. How to capture relevant commonsense knowledge complementary to the history and the image remains a key challenge. In this paper, we propose a novel model by Reasoning with Multi-structure Commonsense Knowledge (RMK). In our model, the external knowledge is represented with sentence-level facts and graph-level facts, to properly suit the scenario of the composite of dialog history and image. On top of these multi-structure representations, our model can capture relevant knowledge and incorporate them into the vision and semantic features, via graph-based interaction and transformer-based fusion. Experimental results and analysis on VisDial v1.0 and VisDialCK datasets show that our proposed model effectively outperforms comparative methods.