 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Detective: Seek Critical Clues Recurrently to Answer Question from Long Videos
Dec 19, 2025Long Video Question-Answering (LVQA) presents a significant challenge for Multi-modal Large Language Models (MLLMs) due to immense context and overloaded information, which could also lead to prohibitive memory consumption. While existing methods attempt to address these issues by reducing visual tokens or extending model's context length, they may miss useful information or take considerable computation. In fact, when answering given questions, only a small amount of crucial information is required. Therefore, we propose an efficient question-aware memory mechanism, enabling MLLMs to recurrently seek these critical clues. Our approach, named VideoDetective, simplifies this task by iteratively processing video sub-segments. For each sub-segment, a question-aware compression strategy is employed by introducing a few special memory tokens to achieve purposefully compression. This allows models to effectively seek critical clues while reducing visual tokens. Then, due to history context could have a significant impact, we recurrently aggregate and store these memory tokens to update history context, which would be reused for subsequent sub-segments. Furthermore, to more effectively measure model's long video understanding ability, we introduce GLVC (Grounding Long Video Clues), a long video question-answering dataset, which features grounding critical and concrete clues scattered throughout entire videos. Experimental results demonstrate our method enables MLLMs with limited context length of 32K to efficiently process 100K tokens (3600 frames, an hour-long video sampled at 1fps), requiring only 2 minutes and 37GB GPU memory usage. Evaluation results across multiple long video benchmarks illustrate our method can more effectively seek critical clues from massive information.
Crab: A Unified Audio-Visual Scene Understanding Model with Explicit Cooperation
Mar 17, 2025In recent years, numerous tasks have been proposed to encourage model to develop specified capability in understanding audio-visual scene, primarily categorized into temporal localization, spatial localization, spatio-temporal reasoning, and pixel-level understanding. Instead, human possesses a unified understanding ability for diversified tasks. Therefore, designing an audio-visual model with general capability to unify these tasks is of great value. However, simply joint training for all tasks can lead to interference due to the heterogeneity of audiovisual data and complex relationship among tasks. We argue that this problem can be solved through explicit cooperation among tasks. To achieve this goal, we propose a unified learning method which achieves explicit inter-task cooperation from both the perspectives of data and model thoroughly. Specifically, considering the labels of existing datasets are simple words, we carefully refine these datasets and construct an Audio-Visual Unified Instruction-tuning dataset with Explicit reasoning process (AV-UIE), which clarifies the cooperative relationship among tasks. Subsequently, to facilitate concrete cooperation in learning stage, an interaction-aware LoRA structure with multiple LoRA heads is designed to learn different aspects of audiovisual data interaction. By unifying the explicit cooperation across the data and model aspect, our method not only surpasses existing unified audio-visual model on multiple tasks, but also outperforms most specialized models for certain tasks. Furthermore, we also visualize the process of explicit cooperation and surprisingly find that each LoRA head has certain audio-visual understanding ability. Code and dataset: https://github.com/GeWu-Lab/Crab
On-the-fly Modulation for Balanced Multimodal Learning
Oct 15, 2024



Multimodal learning is expected to boost model performance by integrating information from different modalities. However, its potential is not fully exploited because the widely-used joint training strategy, which has a uniform objective for all modalities, leads to imbalanced and under-optimized uni-modal representations. Specifically, we point out that there often exists modality with more discriminative information, e.g., vision of playing football and sound of blowing wind. They could dominate the joint training process, resulting in other modalities being significantly under-optimized. To alleviate this problem, we first analyze the under-optimized phenomenon from both the feed-forward and the back-propagation stages during optimization. Then, On-the-fly Prediction Modulation (OPM) and On-the-fly Gradient Modulation (OGM) strategies are proposed to modulate the optimization of each modality, by monitoring the discriminative discrepancy between modalities during training. Concretely, OPM weakens the influence of the dominant modality by dropping its feature with dynamical probability in the feed-forward stage, while OGM mitigates its gradient in the back-propagation stage. In experiments, our methods demonstrate considerable improvement across a variety of multimodal tasks. These simple yet effective strategies not only enhance performance in vanilla and task-oriented multimodal models, but also in more complex multimodal tasks, showcasing their effectiveness and flexibility. The source code is available at \url{https://github.com/GeWu-Lab/BML_TPAMI2024}.
Boosting Audio Visual Question Answering via Key Semantic-Aware Cues
Jul 30, 2024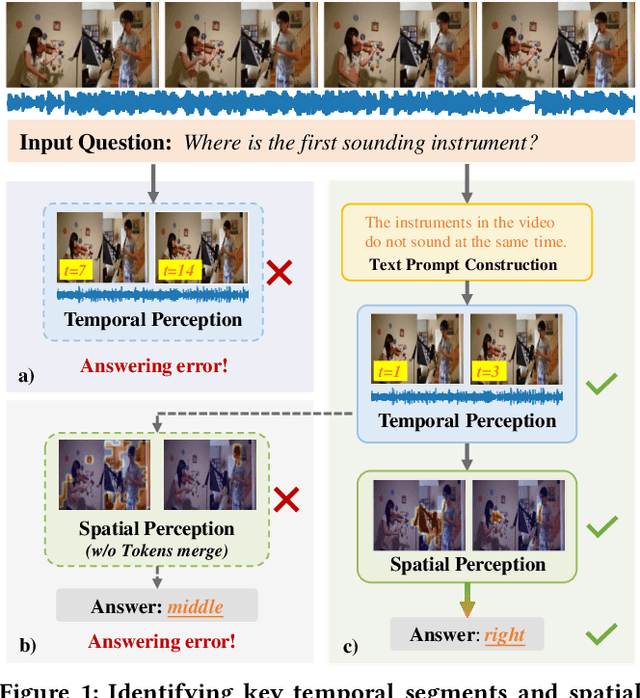
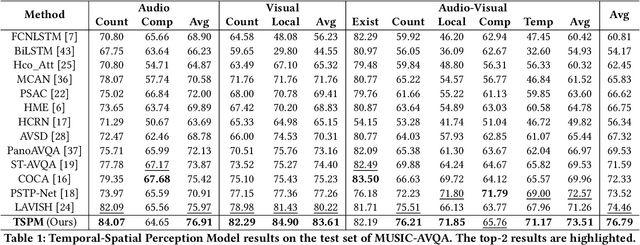
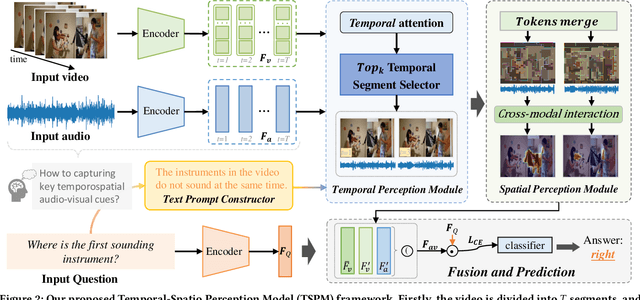
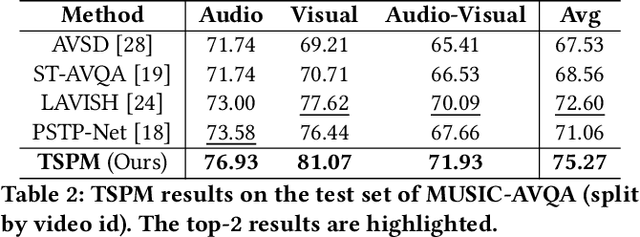
The Audio Visual Question Answering (AVQA) task aims to answer questions related to various visual objects, sounds, and their interactions in videos. Such naturally multimodal videos contain rich and complex dynamic audio-visual components, with only a portion of them closely related to the given questions. Hence, effectively perceiving audio-visual cues relevant to the given questions is crucial for correctly answering them. In this paper, we propose a Temporal-Spatial Perception Model (TSPM), which aims to empower the model to perceive key visual and auditory cues related to the questions. Specifically, considering the challenge of aligning non-declarative questions and visual representations into the same semantic space using visual-language pretrained models, we construct declarative sentence prompts derived from the question template, to assist the temporal perception module in better identifying critical segments relevant to the questions. Subsequently, a spatial perception module is designed to merge visual tokens from selected segments to highlight key latent targets, followed by cross-modal interaction with audio to perceive potential sound-aware areas. Finally, the significant temporal-spatial cues from these modules are integrated to answer the question. Extensive experiments on multiple AVQA benchmarks demonstrate that our framework excels not only in understanding audio-visual scenes but also in answering complex questions effectively. Code is available at https://github.com/GeWu-Lab/TSPM.