 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D Generic Video Object Proposals
Paper and Code

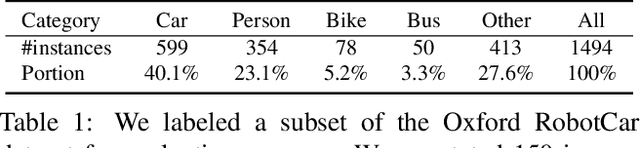
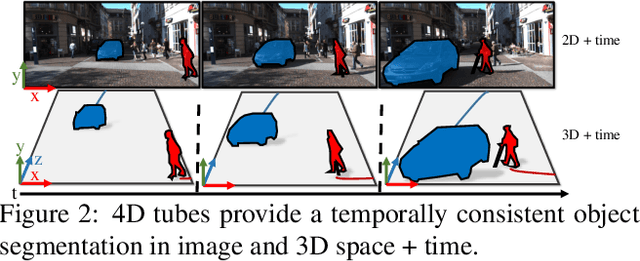
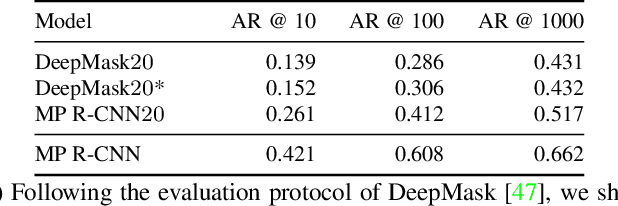
Many high-level video understanding methods require input in the form of object proposals. Currently, such proposals are predominantly generated with the help of networks that were trained for detecting and segmenting a set of known object classes, which limits their applicability to cases where all objects of interest are represented in the training set. This is a restriction for automotive scenarios, where unknown objects can frequently occur. We propose an approach that can reliably extract spatio-temporal object proposals for both known and unknown object categories from stereo video. Our 4D Generic Video Tubes (4D-GVT) method leverages motion cues, stereo data, and object instance segmentation to compute a compact set of video-object proposals that precisely localizes object candidates and their contours in 3D space and time. We show that given only a small amount of labeled data, our 4D-GVT proposal generator generalizes well to real-world scenarios, in which unknown categories appear. It outperforms other approaches that try to detect as many objects as possible by increasing the number of classes in the training set to several thousand.