 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHODOR: High-level Object Descriptors for Object Re-segmentation in Video Learned from Static Images
Paper and Code
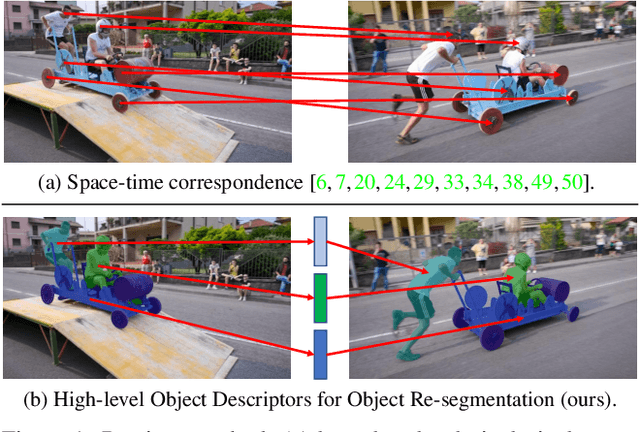
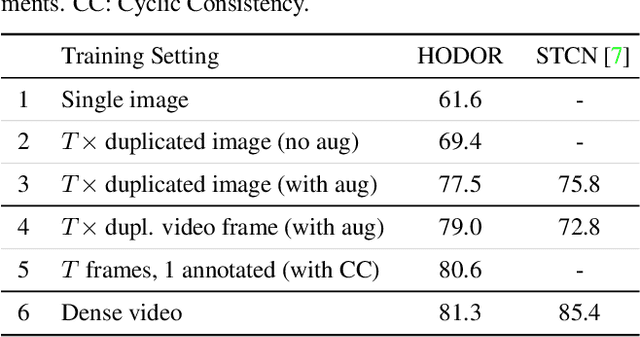

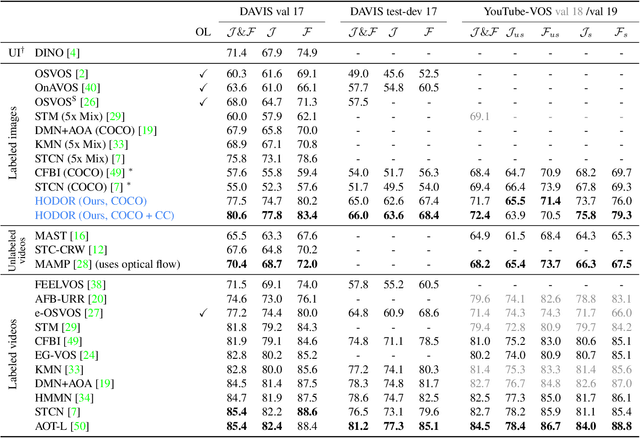
Existing state-of-the-art methods for Video Object Segmentation (VOS) learn low-level pixel-to-pixel correspondences between frames to propagate object masks across video. This requires a large amount of densely annotated video data, which is costly to annotate, and largely redundant since frames within a video are highly correlated. In light of this, we propose HODOR: a novel method that tackles VOS by effectively leveraging annotated static images for understanding object appearance and scene context. We encode object instances and scene information from an image frame into robust high-level descriptors which can then be used to re-segment those objects in different frames. As a result, HODOR achieves state-of-the-art performance on the DAVIS and YouTube-VOS benchmarks compared to existing methods trained without video annotations. Without any architectural modification, HODOR can also learn from video context around single annotated video frames by utilizing cyclic consistency, whereas other methods rely on dense, temporally consistent annotations.