 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Soft-Masked Attention
Paper and Code
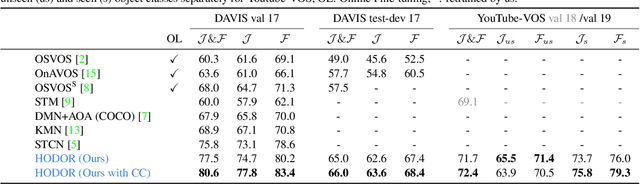
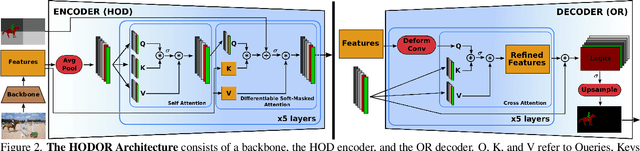

Transformers have become prevalent in computer vision due to their performance and flexibility in modelling complex operations. Of particular significance is the 'cross-attention' operation, which allows a vector representation (e.g. of an object in an image) to be learned by attending to an arbitrarily sized set of input features. Recently, "Masked Attention" was proposed in which a given object representation only attends to those image pixel features for which the segmentation mask of that object is active. This specialization of attention proved beneficial for various image and video segmentation tasks. In this paper, we propose another specialization of attention which enables attending over `soft-masks' (those with continuous mask probabilities instead of binary values), and is also differentiable through these mask probabilities, thus allowing the mask used for attention to be learned within the network without requiring direct loss supervision. This can be useful for several applications. Specifically, we employ our "Differentiable Soft-Masked Attention" for the task of Weakly-Supervised Video Object Segmentation (VOS), where we develop a transformer-based network for VOS which only requires a single annotated image frame for training, but can also benefit from cycle consistency training on a video with just one annotated frame. Although there is no loss for masks in unlabeled frames, the network is still able to segment objects in those frames due to our novel attention formulation.