 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalker: Self-supervised Multiple Object Tracking by Walking on Temporal Appearance Graphs
Paper and Code

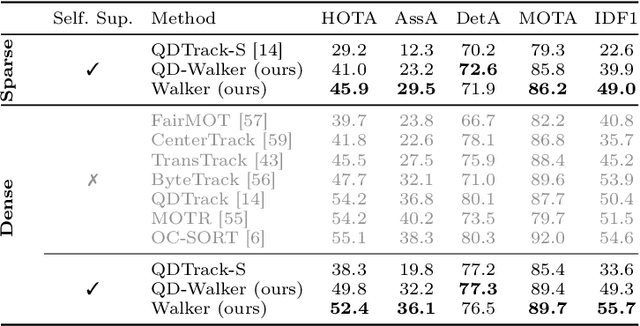

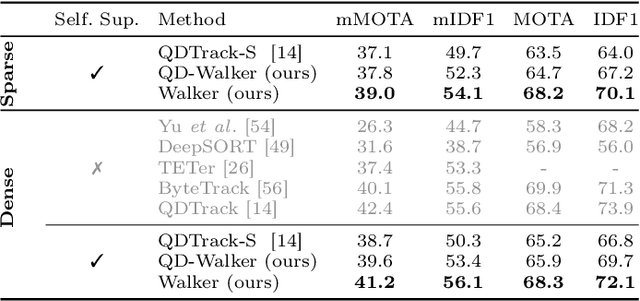
The supervision of state-of-the-art multiple object tracking (MOT) methods requires enormous annotation efforts to provide bounding boxes for all frames of all videos, and instance IDs to associate them through time. To this end, we introduce Walker, the first self-supervised tracker that learns from videos with sparse bounding box annotations, and no tracking labels. First, we design a quasi-dense temporal object appearance graph, and propose a novel multi-positive contrastive objective to optimize random walks on the graph and learn instance similarities. Then, we introduce an algorithm to enforce mutually-exclusive connective properties across instances in the graph, optimizing the learned topology for MOT. At inference time, we propose to associate detected instances to tracklets based on the max-likelihood transition state under motion-constrained bi-directional walks. Walker is the first self-supervised tracker to achieve competitive performance on MOT17, DanceTrack, and BDD100K. Remarkably, our proposal outperforms the previous self-supervised trackers even when drastically reducing the annotation requirements by up to 400x.