 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Accurate Mapping for Autonomous Racing
Mar 12, 2020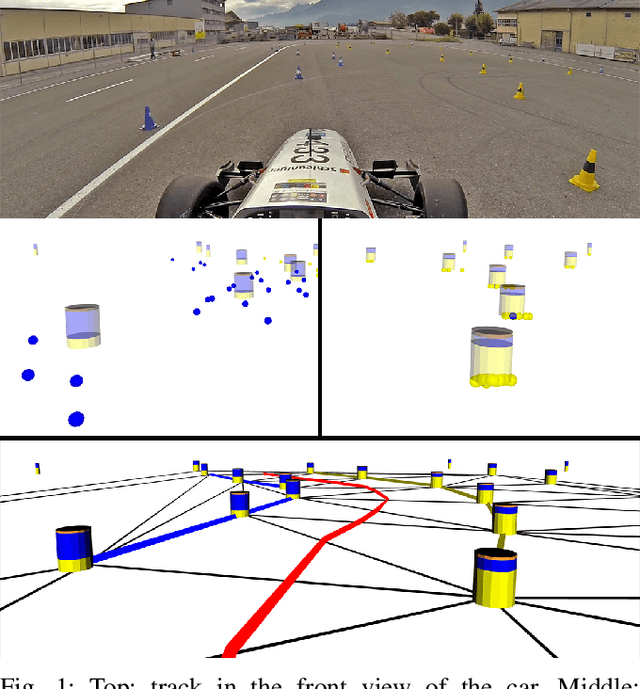
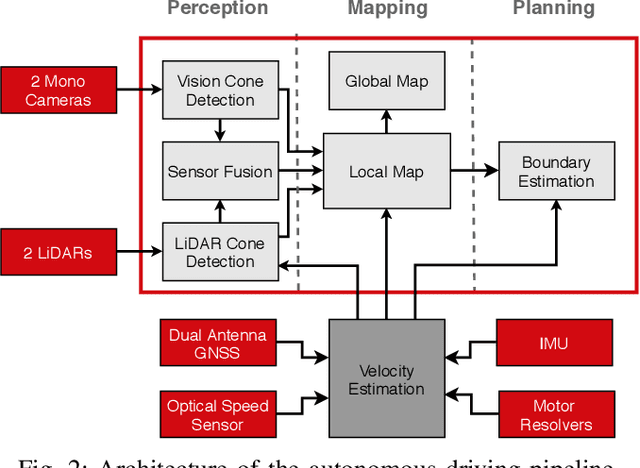
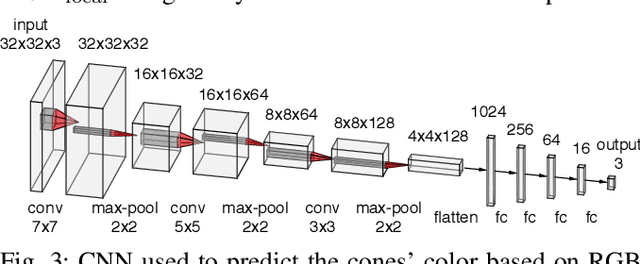

This paper presents the perception, mapping, and planning pipeline implemented on an autonomous race car. It was developed by the 2019 AMZ driverless team for the Formula Student Germany (FSG) 2019 driverless competition, where it won 1st place overall. The presented solution combines early fusion of camera and LiDAR data, a layered mapping approach, and a planning approach that uses Bayesian filtering to achieve high-speed driving on unknown race tracks while creating accurate maps. We benchmark the method against our team's previous solution, which won FSG 2018, and show improved accuracy when driving at the same speeds. Furthermore, the new pipeline makes it possible to reliably raise the maximum driving speed in unknown environments from 3~m/s to 12~m/s while still mapping with an acceptable RMSE of 0.29~m.
MOZARD: Multi-Modal Localization for Autonomous Vehicles in Urban Outdoor Environments
Mar 03, 2020
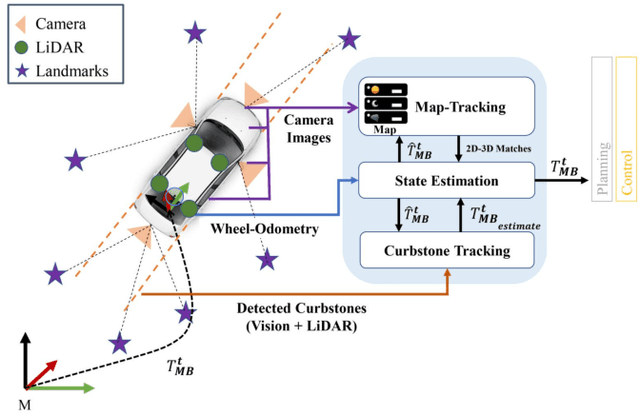


Visually poor scenarios are one of the main sources of failure in visual localization systems in outdoor environments. To address this challenge, we present MOZARD, a multi-modal localization system for urban outdoor environments using vision and LiDAR. By extending our preexisting key-point based visual multi-session local localization approach with the use of semantic data, an improved localization recall can be achieved across vastly different appearance conditions. In particular we focus on the use of curbstone information because of their broad distribution and reliability within urban environments. We present thorough experimental evaluations on several driving kilometers in challenging urban outdoor environments, analyze the recall and accuracy of our localization system and demonstrate in a case study possible failure cases of each subsystem. We demonstrate that MOZARD is able to bridge scenarios where our previous work VIZARD fails, hence yielding an increased recall performance, while a similar localization accuracy of 0.2m is achieved
Deep Unsupervised Common Representation Learning for LiDAR and Camera Data using Double Siamese Networks
Jan 03, 2020
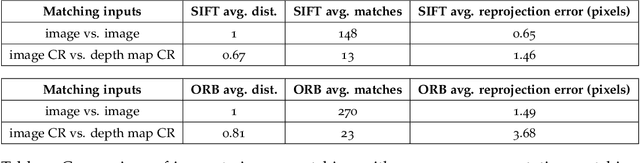

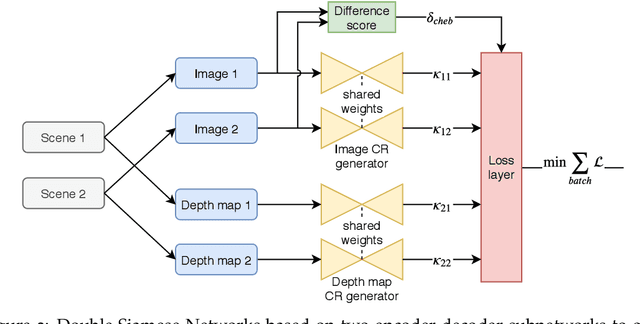
Domain gaps of sensor modalities pose a challenge for the design of autonomous robots. Taking a step towards closing this gap, we propose two unsupervised training frameworks for finding a common representation of LiDAR and camera data. The first method utilizes a double Siamese training structure to ensure consistency in the results. The second method uses a Canny edge image guiding the networks towards a desired representation. All networks are trained in an unsupervised manner, leaving room for scalability. The results are evaluated using common computer vision applications, and the limitations of the proposed approaches are outlined.
OREOS: Oriented Recognition of 3D Point Clouds in Outdoor Scenarios
Mar 19, 2019

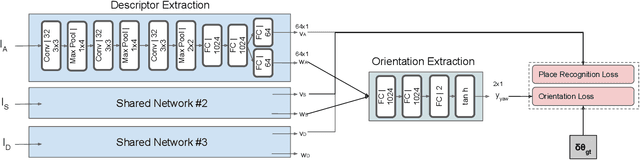
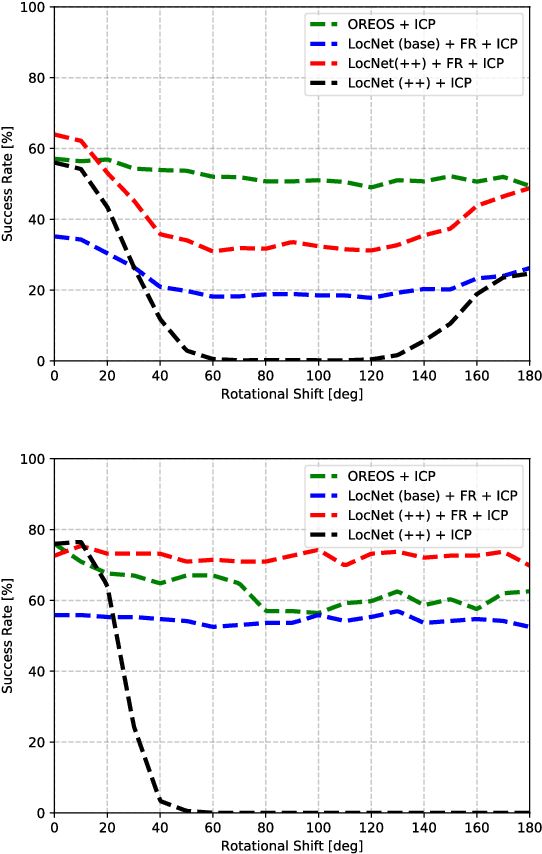
We introduce a novel method for oriented place recognition with 3D LiDAR scans. A Convolutional Neural Network is trained to extract compact descriptors from single 3D LiDAR scans. These can be used both to retrieve near-by place candidates from a map, and to estimate the yaw discrepancy needed for bootstrapping local registration methods. We employ a triplet loss function for training and use a hard-negative mining strategy to further increase the performance of our descriptor extractor. In an evaluation on the NCLT and KITTI datasets, we demonstrate that our method outperforms related state-of-the-art approaches based on both data-driven and handcrafted data representation in challenging long-term outdoor conditions.
VIZARD: Reliable Visual Localization for Autonomous Vehicles in Urban Outdoor Environments
Feb 12, 2019
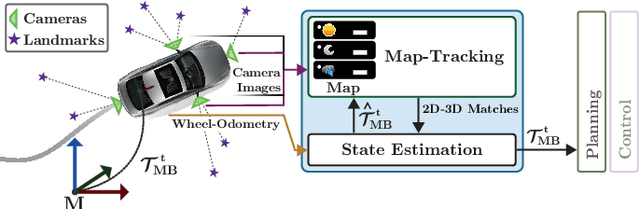
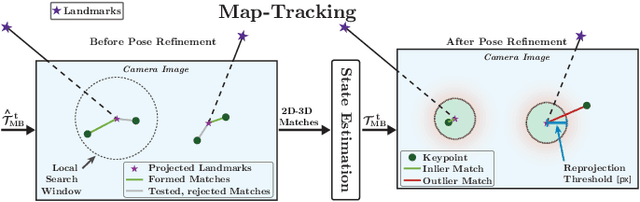
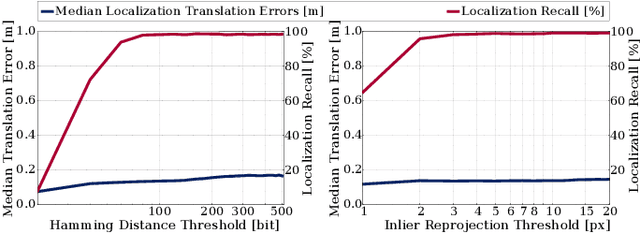
Changes in appearance is one of the main sources of failure in visual localization systems in outdoor environments. To address this challenge, we present VIZARD, a visual localization system for urban outdoor environments. By combining a local localization algorithm with the use of multi-session maps, a high localization recall can be achieved across vastly different appearance conditions. The fusion of the visual localization constraints with wheel-odometry in a state estimation framework further guarantees smooth and accurate pose estimates. In an extensive experimental evaluation on several hundreds of driving kilometers in challenging urban outdoor environments, we analyze the recall and accuracy of our localization system, investigate its key parameters and boundary conditions, and compare different types of feature descriptors. Our results show that VIZARD is able to achieve nearly 100% recall with a localization accuracy below 0.5m under varying outdoor appearance conditions, including at night-time.