 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOZARD: Multi-Modal Localization for Autonomous Vehicles in Urban Outdoor Environments
Paper and Code
Mar 03, 2020
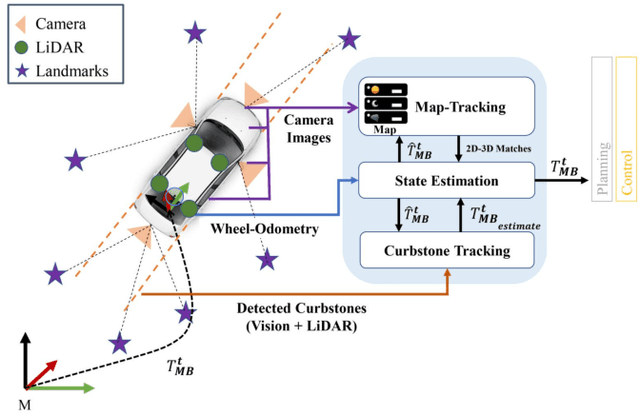


Visually poor scenarios are one of the main sources of failure in visual localization systems in outdoor environments. To address this challenge, we present MOZARD, a multi-modal localization system for urban outdoor environments using vision and LiDAR. By extending our preexisting key-point based visual multi-session local localization approach with the use of semantic data, an improved localization recall can be achieved across vastly different appearance conditions. In particular we focus on the use of curbstone information because of their broad distribution and reliability within urban environments. We present thorough experimental evaluations on several driving kilometers in challenging urban outdoor environments, analyze the recall and accuracy of our localization system and demonstrate in a case study possible failure cases of each subsystem. We demonstrate that MOZARD is able to bridge scenarios where our previous work VIZARD fails, hence yielding an increased recall performance, while a similar localization accuracy of 0.2m is achieved