Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Unsupervised Common Representation Learning for LiDAR and Camera Data using Double Siamese Networks
Paper and Code
Jan 03, 2020
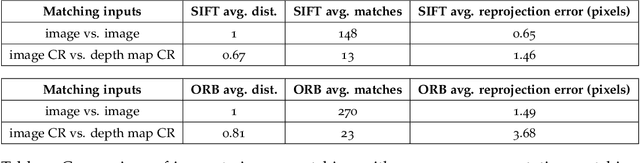

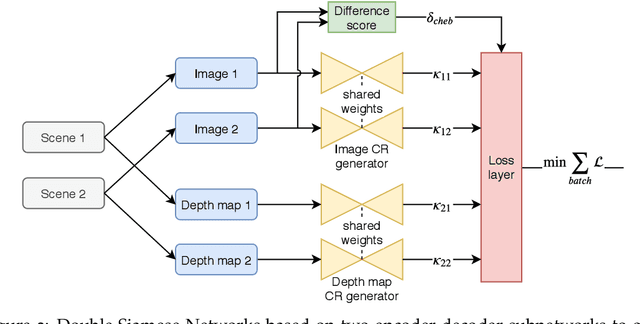
Domain gaps of sensor modalities pose a challenge for the design of autonomous robots. Taking a step towards closing this gap, we propose two unsupervised training frameworks for finding a common representation of LiDAR and camera data. The first method utilizes a double Siamese training structure to ensure consistency in the results. The second method uses a Canny edge image guiding the networks towards a desired representation. All networks are trained in an unsupervised manner, leaving room for scalability. The results are evaluated using common computer vision applications, and the limitations of the proposed approaches are outlined.
* 8 pages, CoRL 2019 template used
View paper on