 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerBite: A Curated Diagnostic Workflow for Bite-Aware Food Volume Estimation
Jun 01, 2026Can a visually plausible food mesh be trusted to estimate the volume of consumed food? \method investigates this question using selected paired before- and after-consumption states from the MetaFood CVPR 2026 Continuous 3D Reconstruction While Eating Challenge. The submitted workflow follows a curated reconstruction protocol: SAM~3 segments the food and plate regions; Hunyuan3D/SAM~3D generates a dimensionless food mesh; the plate diameter provides the metric scale; the plate geometry is removed in Blender; and the remaining mesh is hole-filled, made watertight, and integrated to estimate volume. MoGe-2 is used only as an auxiliary cue for initial dish-diameter estimation when direct plate measurement is uncertain; it is not the primary scale source for the reported challenge result. \method ranks first, with an average Chamfer distance of 8.31 across 34 meshes using rigid ICP without scale correction. On 17 before- and after-pairs, it achieves 33.87\% state-level volume MAPE and zero monotonicity violations, while consumed-volume MAPE remains 53.74\%. The results show that surface reconstruction, metric scale, controlled mesh cleanup, watertight volume integration, and physical depletion consistency should be evaluated separately for dietary assessment. Source code and evaluation scripts will be available at \href{https://github.com/GCVCG/PerBite-CVPR-MetaFood-2026}{github.com/GCVCG/PerBite-CVPR-MetaFood-2026}.
BenchSeg: A Large-Scale Dataset and Benchmark for Multi-View Food Video Segmentation
Jan 12, 2026Food image segmentation is a critical task for dietary analysis, enabling accurate estimation of food volume and nutrients. However, current methods suffer from limited multi-view data and poor generalization to new viewpoints. We introduce BenchSeg, a novel multi-view food video segmentation dataset and benchmark. BenchSeg aggregates 55 dish scenes (from Nutrition5k, Vegetables & Fruits, MetaFood3D, and FoodKit) with 25,284 meticulously annotated frames, capturing each dish under free 360° camera motion. We evaluate a diverse set of 20 state-of-the-art segmentation models (e.g., SAM-based, transformer, CNN, and large multimodal) on the existing FoodSeg103 dataset and evaluate them (alone and combined with video-memory modules) on BenchSeg. Quantitative and qualitative results demonstrate that while standard image segmenters degrade sharply under novel viewpoints, memory-augmented methods maintain temporal consistency across frames. Our best model based on a combination of SeTR-MLA+XMem2 outperforms prior work (e.g., improving over FoodMem by ~2.63% mAP), offering new insights into food segmentation and tracking for dietary analysis. We release BenchSeg to foster future research. The project page including the dataset annotations and the food segmentation models can be found at https://amughrabi.github.io/benchseg.
VolE: A Point-cloud Framework for Food 3D Reconstruction and Volume Estimation
May 15, 2025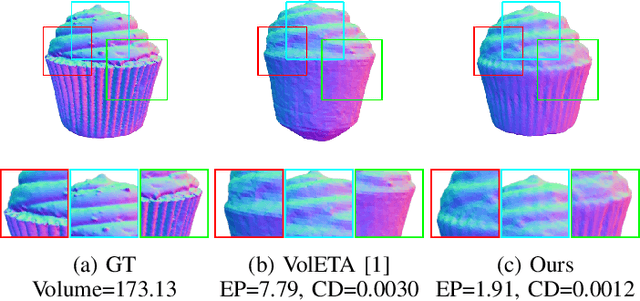



Accurate food volume estimation is crucial for medical nutrition management and health monitoring applications, but current food volume estimation methods are often limited by mononuclear data, leveraging single-purpose hardware such as 3D scanners, gathering sensor-oriented information such as depth information, or relying on camera calibration using a reference object. In this paper, we present VolE, a novel framework that leverages mobile device-driven 3D reconstruction to estimate food volume. VolE captures images and camera locations in free motion to generate precise 3D models, thanks to AR-capable mobile devices. To achieve real-world measurement, VolE is a reference- and depth-free framework that leverages food video segmentation for food mask generation. We also introduce a new food dataset encompassing the challenging scenarios absent in the previous benchmarks. Our experiments demonstrate that VolE outperforms the existing volume estimation techniques across multiple datasets by achieving 2.22 % MAPE, highlighting its superior performance in food volume estimation.
FoodMem: Near Real-time and Precise Food Video Segmentation
Jul 16, 2024



Food segmentation, including in videos, is vital for addressing real-world health, agriculture, and food biotechnology issues. Current limitations lead to inaccurate nutritional analysis, inefficient crop management, and suboptimal food processing, impacting food security and public health. Improving segmentation techniques can enhance dietary assessments, agricultural productivity, and the food production process. This study introduces the development of a robust framework for high-quality, near-real-time segmentation and tracking of food items in videos, using minimal hardware resources. We present FoodMem, a novel framework designed to segment food items from video sequences of 360-degree unbounded scenes. FoodMem can consistently generate masks of food portions in a video sequence, overcoming the limitations of existing semantic segmentation models, such as flickering and prohibitive inference speeds in video processing contexts. To address these issues, FoodMem leverages a two-phase solution: a transformer segmentation phase to create initial segmentation masks and a memory-based tracking phase to monitor food masks in complex scenes. Our framework outperforms current state-of-the-art food segmentation models, yielding superior performance across various conditions, such as camera angles, lighting, reflections, scene complexity, and food diversity. This results in reduced segmentation noise, elimination of artifacts, and completion of missing segments. Here, we also introduce a new annotated food dataset encompassing challenging scenarios absent in previous benchmarks. Extensive experiments conducted on Nutrition5k and Vegetables & Fruits datasets demonstrate that FoodMem enhances the state-of-the-art by 2.5% mean average precision in food video segmentation and is 58 x faster on average.
MetaFood CVPR 2024 Challenge on Physically Informed 3D Food Reconstruction: Methods and Results
Jul 12, 2024
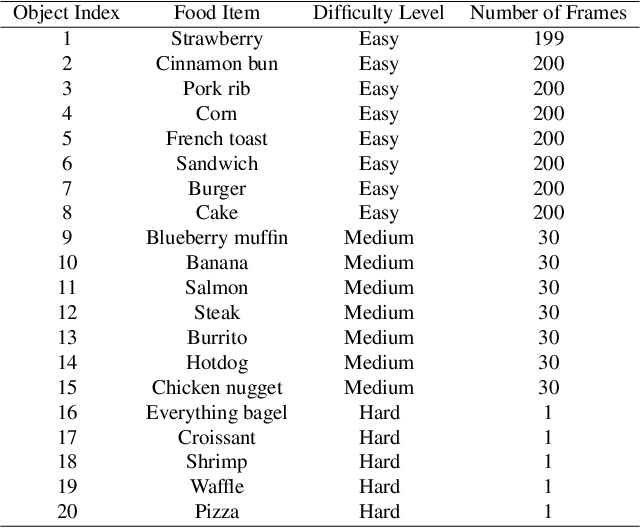
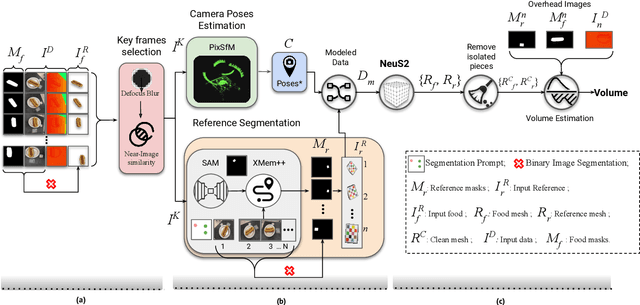
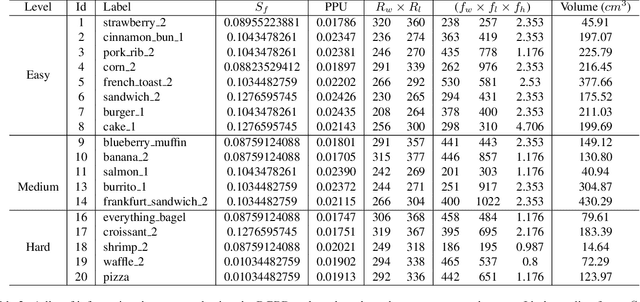
The increasing interest in computer vision applications for nutrition and dietary monitoring has led to the development of advanced 3D reconstruction techniques for food items. However, the scarcity of high-quality data and limited collaboration between industry and academia have constrained progress in this field. Building on recent advancements in 3D reconstruction, we host the MetaFood Workshop and its challenge for Physically Informed 3D Food Reconstruction. This challenge focuses on reconstructing volume-accurate 3D models of food items from 2D images, using a visible checkerboard as a size reference. Participants were tasked with reconstructing 3D models for 20 selected food items of varying difficulty levels: easy, medium, and hard. The easy level provides 200 images, the medium level provides 30 images, and the hard level provides only 1 image for reconstruction. In total, 16 teams submitted results in the final testing phase. The solutions developed in this challenge achieved promising results in 3D food reconstruction, with significant potential for improving portion estimation for dietary assessment and nutritional monitoring. More details about this workshop challenge and access to the dataset can be found at https://sites.google.com/view/cvpr-metafood-2024.
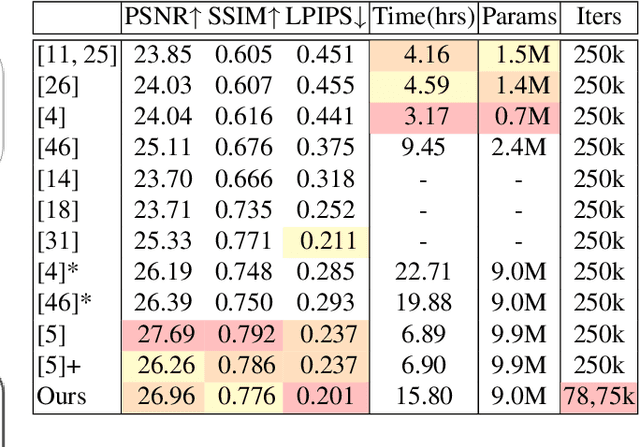
MomentsNeRF: Leveraging Orthogonal Moments for Few-Shot Neural Rendering
Jul 02, 2024



We propose MomentsNeRF, a novel framework for one- and few-shot neural rendering that predicts a neural representation of a 3D scene using Orthogonal Moments. Our architecture offers a new transfer learning method to train on multi-scenes and incorporate a per-scene optimization using one or a few images at test time. Our approach is the first to successfully harness features extracted from Gabor and Zernike moments, seamlessly integrating them into the NeRF architecture. We show that MomentsNeRF performs better in synthesizing images with complex textures and shapes, achieving a significant noise reduction, artifact elimination, and completing the missing parts compared to the recent one- and few-shot neural rendering frameworks. Extensive experiments on the DTU and Shapenet datasets show that MomentsNeRF improves the state-of-the-art by {3.39\;dB\;PSNR}, 11.1% SSIM, 17.9% LPIPS, and 8.3% DISTS metrics. Moreover, it outperforms state-of-the-art performance for both novel view synthesis and single-image 3D view reconstruction. The source code is accessible at: https://amughrabi.github.io/momentsnerf/.
VolETA: One- and Few-shot Food Volume Estimation
Jul 01, 2024



Accurate food volume estimation is essential for dietary assessment, nutritional tracking, and portion control applications. We present VolETA, a sophisticated methodology for estimating food volume using 3D generative techniques. Our approach creates a scaled 3D mesh of food objects using one- or few-RGBD images. We start by selecting keyframes based on the RGB images and then segmenting the reference object in the RGB images using XMem++. Simultaneously, camera positions are estimated and refined using the PixSfM technique. The segmented food images, reference objects, and camera poses are combined to form a data model suitable for NeuS2. Independent mesh reconstructions for reference and food objects are carried out, with scaling factors determined using MeshLab based on the reference object. Moreover, depth information is used to fine-tune the scaling factors by estimating the potential volume range. The fine-tuned scaling factors are then applied to the cleaned food meshes for accurate volume measurements. Similarly, we enter a segmented RGB image to the One-2-3-45 model for one-shot food volume estimation, resulting in a mesh. We then leverage the obtained scaling factors to the cleaned food mesh for accurate volume measurements. Our experiments show that our method effectively addresses occlusions, varying lighting conditions, and complex food geometries, achieving robust and accurate volume estimations with 10.97% MAPE using the MTF dataset. This innovative approach enhances the precision of volume assessments and significantly contributes to computational nutrition and dietary monitoring advancements.
MVSBoost: An Efficient Point Cloud-based 3D Reconstruction
Jun 19, 2024
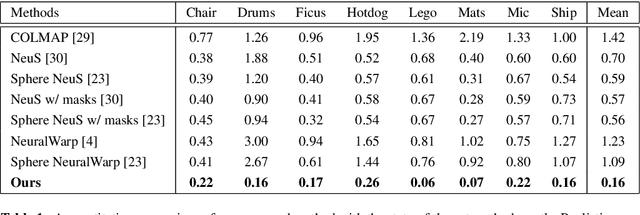
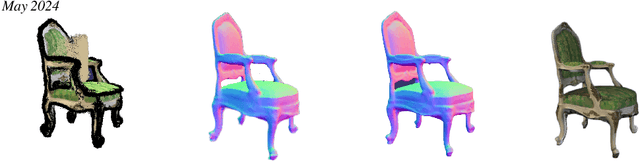
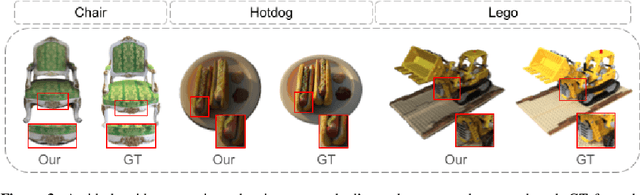
Efficient and accurate 3D reconstruction is crucial for various applications, including augmented and virtual reality, medical imaging, and cinematic special effects. While traditional Multi-View Stereo (MVS) systems have been fundamental in these applications, using neural implicit fields in implicit 3D scene modeling has introduced new possibilities for handling complex topologies and continuous surfaces. However, neural implicit fields often suffer from computational inefficiencies, overfitting, and heavy reliance on data quality, limiting their practical use. This paper presents an enhanced MVS framework that integrates multi-view 360-degree imagery with robust camera pose estimation via Structure from Motion (SfM) and advanced image processing for point cloud densification, mesh reconstruction, and texturing. Our approach significantly improves upon traditional MVS methods, offering superior accuracy and precision as validated using Chamfer distance metrics on the Realistic Synthetic 360 dataset. The developed MVS technique enhances the detail and clarity of 3D reconstructions and demonstrates superior computational efficiency and robustness in complex scene reconstruction, effectively handling occlusions and varying viewpoints. These improvements suggest that our MVS framework can compete with and potentially exceed current state-of-the-art neural implicit field methods, especially in scenarios requiring real-time processing and scalability.
Pre-NeRF 360: Enriching Unbounded Appearances for Neural Radiance Fields
Mar 21, 2023


Neural radiance fields (NeRF) appeared recently as a powerful tool to generate realistic views of objects and confined areas. Still, they face serious challenges with open scenes, where the camera has unrestricted movement and content can appear at any distance. In such scenarios, current NeRF-inspired models frequently yield hazy or pixelated outputs, suffer slow training times, and might display irregularities, because of the challenging task of reconstructing an extensive scene from a limited number of images. We propose a new framework to boost the performance of NeRF-based architectures yielding significantly superior outcomes compared to the prior work. Our solution overcomes several obstacles that plagued earlier versions of NeRF, including handling multiple video inputs, selecting keyframes, and extracting poses from real-world frames that are ambiguous and symmetrical. Furthermore, we applied our framework, dubbed as "Pre-NeRF 360", to enable the use of the Nutrition5k dataset in NeRF and introduce an updated version of this dataset, known as the N5k360 dataset.
A Perceptually-Validated Metric for Crowd Trajectory Quality Evaluation
Sep 04, 2021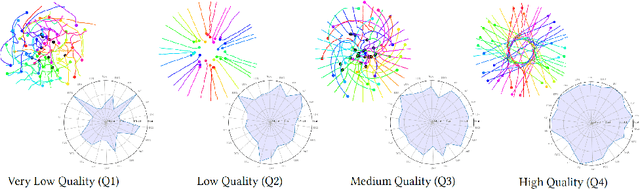

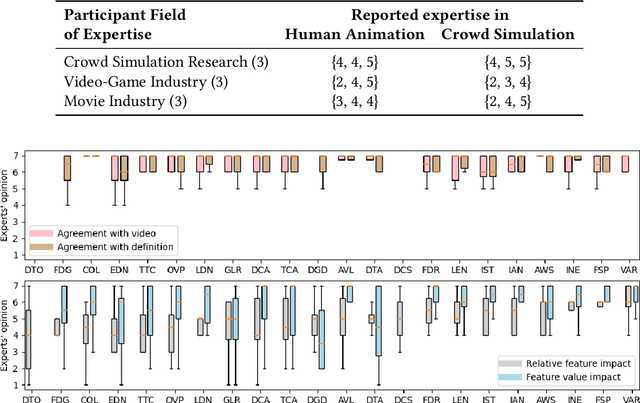
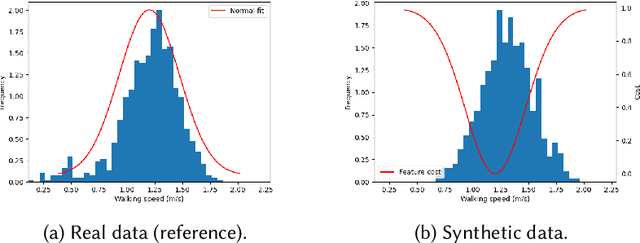
Simulating crowds requires controlling a very large number of trajectories and is usually performed using crowd motion algorithms for which appropriate parameter values need to be found. The study of the relation between parametric values for simulation techniques and the quality of the resulting trajectories has been studied either through perceptual experiments or by comparison with real crowd trajectories. In this paper, we integrate both strategies. A quality metric, QF, is proposed to abstract from reference data while capturing the most salient features that affect the perception of trajectory realism. QF weights and combines cost functions that are based on several individual, local and global properties of trajectories. These trajectory features are selected from the literature and from interviews with experts. To validate the capacity of QF to capture perceived trajectory quality, we conduct an online experiment that demonstrates the high agreement between the automatic quality score and non-expert users. To further demonstrate the usefulness of QF, we use it in a data-free parameter tuning application able to tune any parametric microscopic crowd simulation model that outputs independent trajectories for characters. The learnt parameters for the tuned crowd motion model maintain the influence of the reference data which was used to weight the terms of QF.