 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure from Articulated Motion: An Accurate and Stable Monocular 3D Reconstruction Approach without Training Data
May 12, 2019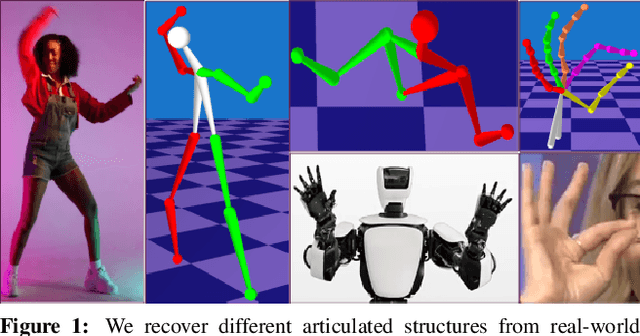
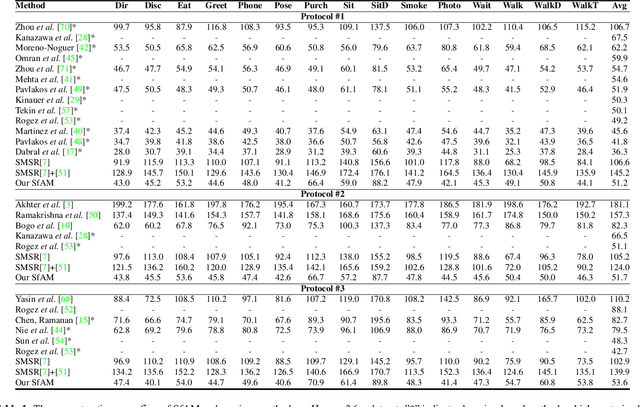

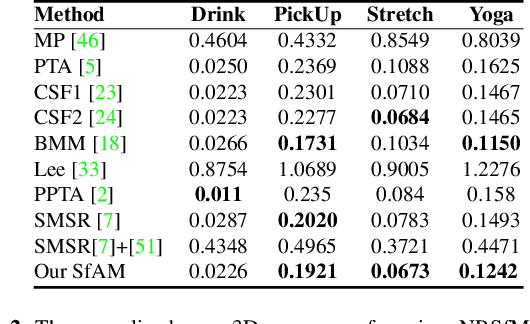
Recovery of articulated 3D structure from 2D observations is a challenging computer vision problem with many applications. Current learning-based approaches achieve state-of-the-art performance on public benchmarks but are limited to the specific types of objects and motions covered by the training datasets. Model-based approaches do not rely on training data but show lower accuracy on public benchmarks. In this paper, we introduce a new model-based method called Structure from Articulated Motion (SfAM). SfAM includes a new articulated structure term which ensures consistency of bone lengths throughout the whole image sequence and recovers a scene-specific configuration of the articulated structure. The proposed approach is highly robust to noisy 2D annotations, generalizes to arbitrary objects and motion types and does not rely on training data. It achieves state-of-the-art accuracy and scales across different scenarios which is shown in extensive experiments on public benchmarks and real video sequences.