 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative View Synthesis: From Single-view Semantics to Novel-view Images
Aug 20, 2020
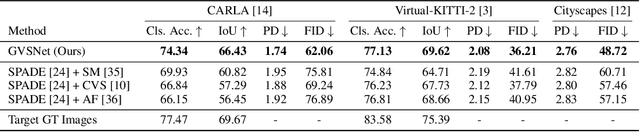


Content creation, central to applications such as virtual reality, can be a tedious and time-consuming. Recent image synthesis methods simplify this task by offering tools to generate new views from as little as a single input image, or by converting a semantic map into a photorealistic image. We propose to push the envelope further, and introduce \emph{Generative View Synthesis} (GVS), which can synthesize multiple photorealistic views of a scene given a single semantic map. We show that the sequential application of existing techniques, e.g., semantics-to-image translation followed by monocular view synthesis, fail at capturing the scene's structure. In contrast, we solve the semantics-to-image translation in concert with the estimation of the 3D layout of the scene, thus producing geometrically consistent novel views that preserve semantic structures. We first lift the input 2D semantic map onto a 3D layered representation of the scene in feature space, thereby preserving the semantic labels of 3D geometric structures. We then project the layered features onto the target views to generate the final novel-view images. We verify the strengths of our method and compare it with several advanced baselines on three different datasets. Our approach also allows for style manipulation and image editing operations, such as the addition or removal of objects, with simple manipulations of the input style images and semantic maps respectively. Visit the project page at https://gvsnet.github.io.
Fast Feature Extraction with CNNs with Pooling Layers
May 08, 2018



In recent years, many publications showed that convolutional neural network based features can have a superior performance to engineered features. However, not much effort was taken so far to extract local features efficiently for a whole image. In this paper, we present an approach to compute patch-based local feature descriptors efficiently in presence of pooling and striding layers for whole images at once. Our approach is generic and can be applied to nearly all existing network architectures. This includes networks for all local feature extraction tasks like camera calibration, Patchmatching, optical flow estimation and stereo matching. In addition, our approach can be applied to other patch-based approaches like sliding window object detection and recognition. We complete our paper with a speed benchmark of popular CNN based feature extraction approaches applied on a whole image, with and without our speedup, and example code (for Torch) that shows how an arbitrary CNN architecture can be easily converted by our approach.
Fast View Synthesis with Deep Stereo Vision
May 07, 2018
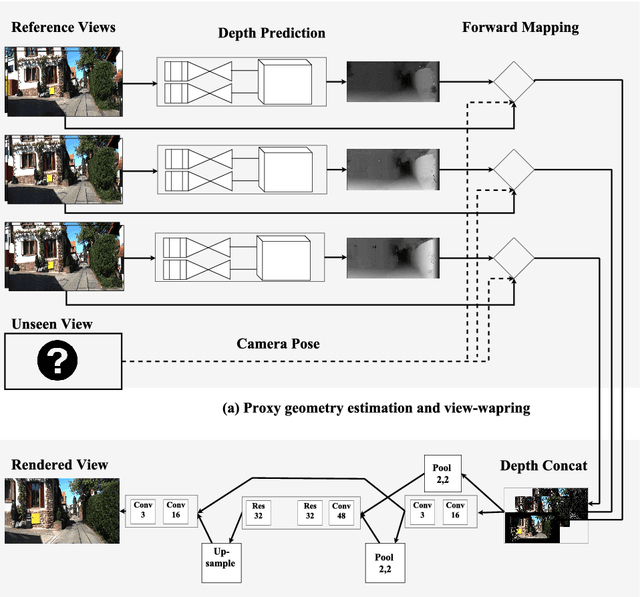
Novel view synthesis is an important problem in computer vision and graphics. Over the years a large number of solutions have been put forward to solve the problem. However, the large-baseline novel view synthesis problem is far from being "solved". Recent works have attempted to use Convolutional Neural Networks (CNNs) to solve view synthesis tasks. Due to the difficulty of learning scene geometry and interpreting camera motion, CNNs are often unable to generate realistic novel views. In this paper, we present a novel view synthesis approach based on stereo-vision and CNNs that decomposes the problem into two sub-tasks: view dependent geometry estimation and texture inpainting. Both tasks are structured prediction problems that could be effectively learned with CNNs. Experiments on the KITTI Odometry dataset show that our approach is more accurate and significantly faster than the current state-of-the-art. The code and supplementary material will be publicly available. Results could be found here https://youtu.be/5pzS9jc-5t0