 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCBM-RAG: Demonstrating Enhanced Interpretability in Radiology Report Generation with Multi-Agent RAG and Concept Bottleneck Models
Apr 29, 2025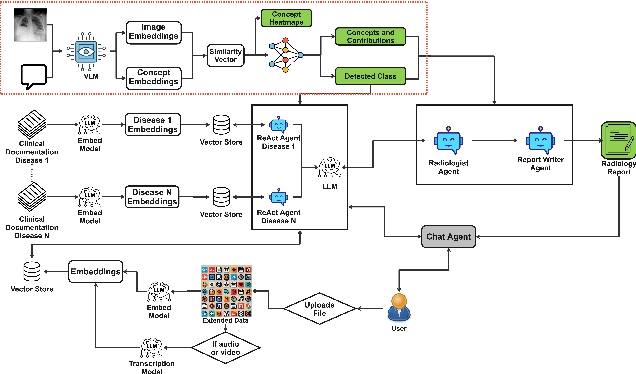
Advancements in generative Artificial Intelligence (AI) hold great promise for automating radiology workflows, yet challenges in interpretability and reliability hinder clinical adoption. This paper presents an automated radiology report generation framework that combines Concept Bottleneck Models (CBMs) with a Multi-Agent Retrieval-Augmented Generation (RAG) system to bridge AI performance with clinical explainability. CBMs map chest X-ray features to human-understandable clinical concepts, enabling transparent disease classification. Meanwhile, the RAG system integrates multi-agent collaboration and external knowledge to produce contextually rich, evidence-based reports. Our demonstration showcases the system's ability to deliver interpretable predictions, mitigate hallucinations, and generate high-quality, tailored reports with an interactive interface addressing accuracy, trust, and usability challenges. This framework provides a pathway to improving diagnostic consistency and empowering radiologists with actionable insights.
Towards Interpretable Radiology Report Generation via Concept Bottlenecks using a Multi-Agentic RAG
Dec 20, 2024Deep learning has advanced medical image classification, but interpretability challenges hinder its clinical adoption. This study enhances interpretability in Chest X-ray (CXR) classification by using concept bottleneck models (CBMs) and a multi-agent Retrieval-Augmented Generation (RAG) system for report generation. By modeling relationships between visual features and clinical concepts, we create interpretable concept vectors that guide a multi-agent RAG system to generate radiology reports, enhancing clinical relevance, explainability, and transparency. Evaluation of the generated reports using an LLM-as-a-judge confirmed the interpretability and clinical utility of our model's outputs. On the COVID-QU dataset, our model achieved 81% classification accuracy and demonstrated robust report generation performance, with five key metrics ranging between 84% and 90%. This interpretable multi-agent framework bridges the gap between high-performance AI and the explainability required for reliable AI-driven CXR analysis in clinical settings.
Revealing Vulnerabilities of Neural Networks in Parameter Learning and Defense Against Explanation-Aware Backdoors
Mar 25, 2024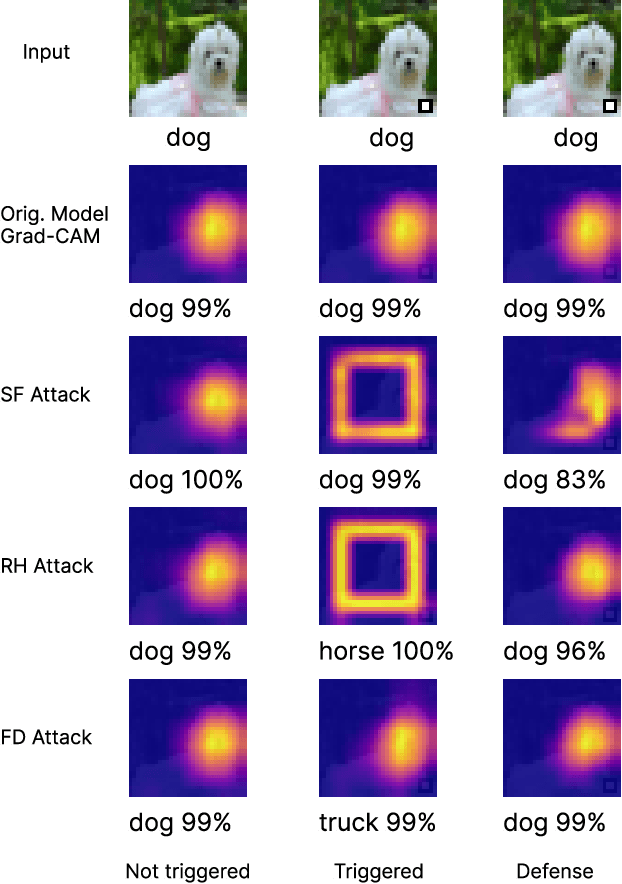
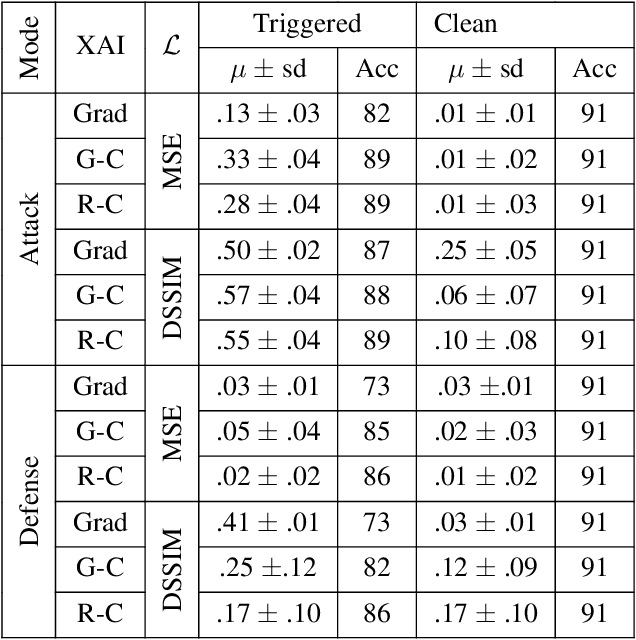
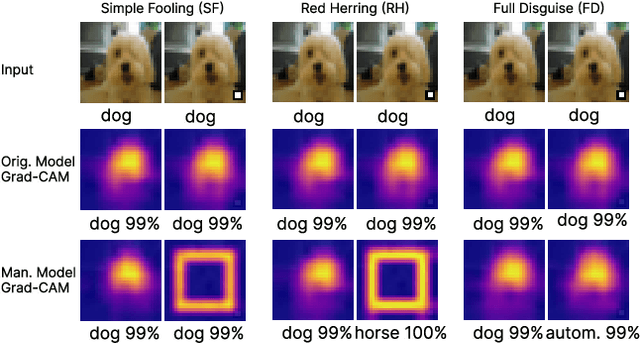

Explainable Artificial Intelligence (XAI) strategies play a crucial part in increasing the understanding and trustworthiness of neural networks. Nonetheless, these techniques could potentially generate misleading explanations. Blinding attacks can drastically alter a machine learning algorithm's prediction and explanation, providing misleading information by adding visually unnoticeable artifacts into the input, while maintaining the model's accuracy. It poses a serious challenge in ensuring the reliability of XAI methods. To ensure the reliability of XAI methods poses a real challenge, we leverage statistical analysis to highlight the changes in CNN weights within a CNN following blinding attacks. We introduce a method specifically designed to limit the effectiveness of such attacks during the evaluation phase, avoiding the need for extra training. The method we suggest defences against most modern explanation-aware adversarial attacks, achieving an approximate decrease of ~99\% in the Attack Success Rate (ASR) and a ~91\% reduction in the Mean Square Error (MSE) between the original explanation and the defended (post-attack) explanation across three unique types of attacks.
Modular Deep Active Learning Framework for Image Annotation: A Technical Report for the Ophthalmo-AI Project
Mar 22, 2024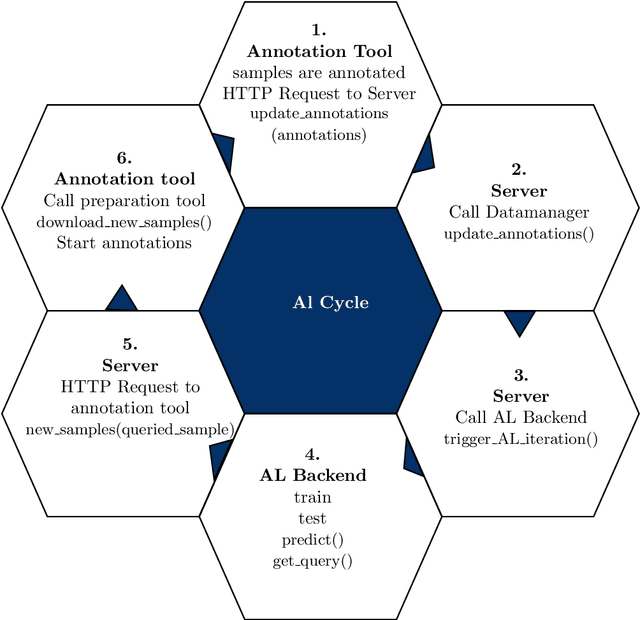

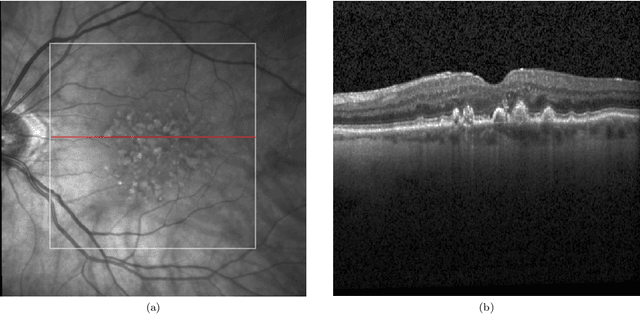
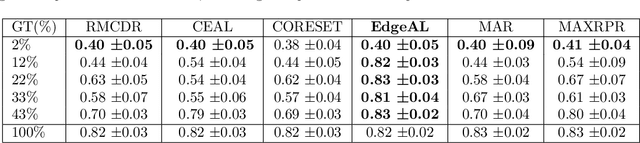
Image annotation is one of the most essential tasks for guaranteeing proper treatment for patients and tracking progress over the course of therapy in the field of medical imaging and disease diagnosis. However, manually annotating a lot of 2D and 3D imaging data can be extremely tedious. Deep Learning (DL) based segmentation algorithms have completely transformed this process and made it possible to automate image segmentation. By accurately segmenting medical images, these algorithms can greatly minimize the time and effort necessary for manual annotation. Additionally, by incorporating Active Learning (AL) methods, these segmentation algorithms can perform far more effectively with a smaller amount of ground truth data. We introduce MedDeepCyleAL, an end-to-end framework implementing the complete AL cycle. It provides researchers with the flexibility to choose the type of deep learning model they wish to employ and includes an annotation tool that supports the classification and segmentation of medical images. The user-friendly interface allows for easy alteration of the AL and DL model settings through a configuration file, requiring no prior programming experience. While MedDeepCyleAL can be applied to any kind of image data, we have specifically applied it to ophthalmology data in this project.
Harmonizing Feature Attributions Across Deep Learning Architectures: Enhancing Interpretability and Consistency
Jul 25, 2023Ensuring the trustworthiness and interpretability of machine learning models is critical to their deployment in real-world applications. Feature attribution methods have gained significant attention, which provide local explanations of model predictions by attributing importance to individual input features. This study examines the generalization of feature attributions across various deep learning architectures, such as convolutional neural networks (CNNs) and vision transformers. We aim to assess the feasibility of utilizing a feature attribution method as a future detector and examine how these features can be harmonized across multiple models employing distinct architectures but trained on the same data distribution. By exploring this harmonization, we aim to develop a more coherent and optimistic understanding of feature attributions, enhancing the consistency of local explanations across diverse deep-learning models. Our findings highlight the potential for harmonized feature attribution methods to improve interpretability and foster trust in machine learning applications, regardless of the underlying architecture.
EdgeAL: An Edge Estimation Based Active Learning Approach for OCT Segmentation
Jul 25, 2023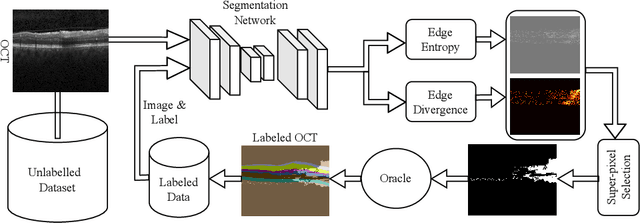


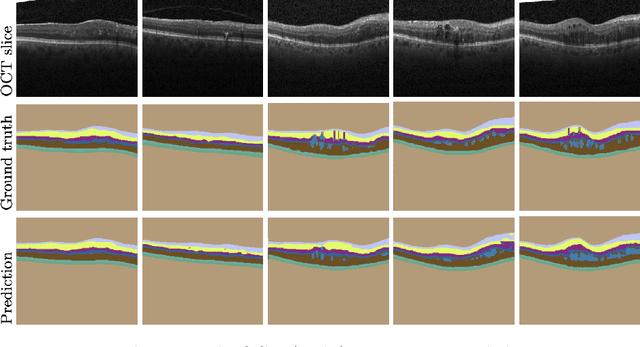
Active learning algorithms have become increasingly popular for training models with limited data. However, selecting data for annotation remains a challenging problem due to the limited information available on unseen data. To address this issue, we propose EdgeAL, which utilizes the edge information of unseen images as {\it a priori} information for measuring uncertainty. The uncertainty is quantified by analyzing the divergence and entropy in model predictions across edges. This measure is then used to select superpixels for annotation. We demonstrate the effectiveness of EdgeAL on multi-class Optical Coherence Tomography (OCT) segmentation tasks, where we achieved a 99% dice score while reducing the annotation label cost to 12%, 2.3%, and 3%, respectively, on three publicly available datasets (Duke, AROI, and UMN). The source code is available at \url{https://github.com/Mak-Ta-Reque/EdgeAL}
Fine-tuning of explainable CNNs for skin lesion classification based on dermatologists' feedback towards increasing trust
Apr 03, 2023



In this paper, we propose a CNN fine-tuning method which enables users to give simultaneous feedback on two outputs: the classification itself and the visual explanation for the classification. We present the effect of this feedback strategy in a skin lesion classification task and measure how CNNs react to the two types of user feedback. To implement this approach, we propose a novel CNN architecture that integrates the Grad-CAM technique for explaining the model's decision in the training loop. Using simulated user feedback, we found that fine-tuning our model on both classification and explanation improves visual explanation while preserving classification accuracy, thus potentially increasing the trust of users in using CNN-based skin lesion classifiers.