 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Vulnerabilities of Neural Networks in Parameter Learning and Defense Against Explanation-Aware Backdoors
Mar 25, 2024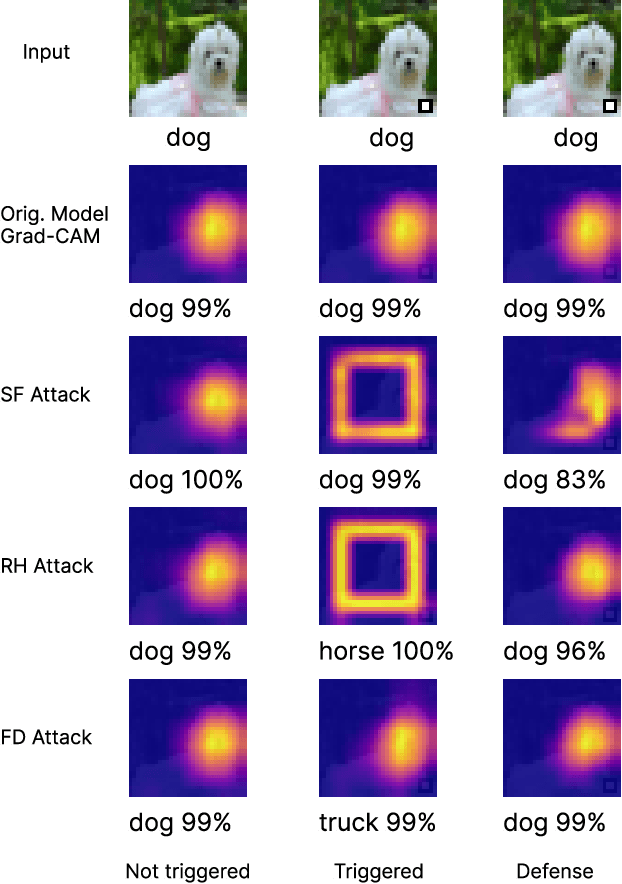
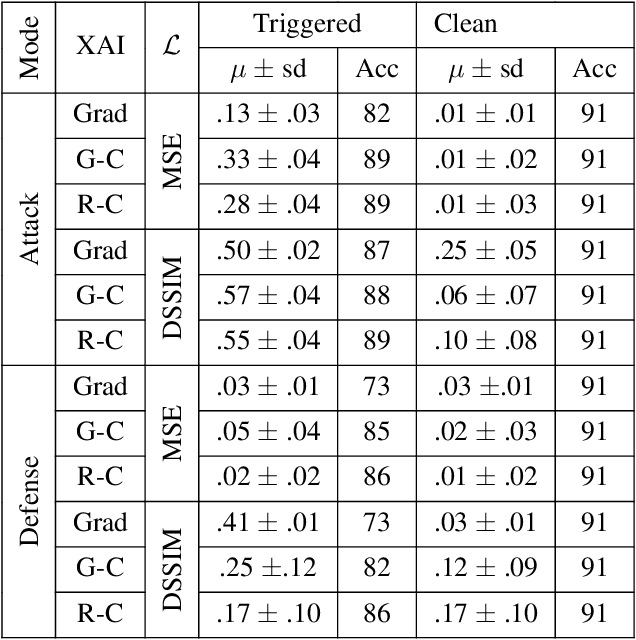
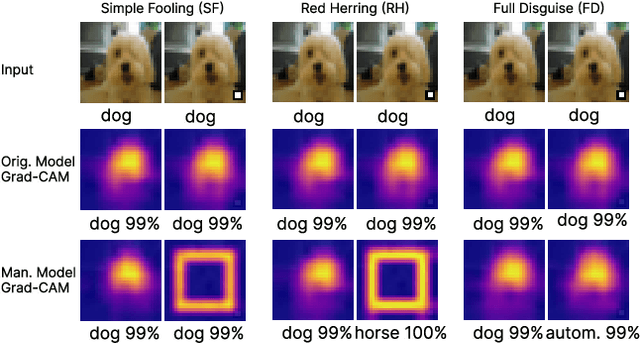

Explainable Artificial Intelligence (XAI) strategies play a crucial part in increasing the understanding and trustworthiness of neural networks. Nonetheless, these techniques could potentially generate misleading explanations. Blinding attacks can drastically alter a machine learning algorithm's prediction and explanation, providing misleading information by adding visually unnoticeable artifacts into the input, while maintaining the model's accuracy. It poses a serious challenge in ensuring the reliability of XAI methods. To ensure the reliability of XAI methods poses a real challenge, we leverage statistical analysis to highlight the changes in CNN weights within a CNN following blinding attacks. We introduce a method specifically designed to limit the effectiveness of such attacks during the evaluation phase, avoiding the need for extra training. The method we suggest defences against most modern explanation-aware adversarial attacks, achieving an approximate decrease of ~99\% in the Attack Success Rate (ASR) and a ~91\% reduction in the Mean Square Error (MSE) between the original explanation and the defended (post-attack) explanation across three unique types of attacks.