 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiCLS : Tightly Coupled Language Text Spotter
Feb 03, 2026Scene text spotting aims to detect and recognize text in real-world images, where instances are often short, fragmented, or visually ambiguous. Existing methods primarily rely on visual cues and implicitly capture local character dependencies, but they overlook the benefits of external linguistic knowledge. Prior attempts to integrate language models either adapt language modeling objectives without external knowledge or apply pretrained models that are misaligned with the word-level granularity of scene text. We propose TiCLS, an end-to-end text spotter that explicitly incorporates external linguistic knowledge from a character-level pretrained language model. TiCLS introduces a linguistic decoder that fuses visual and linguistic features, yet can be initialized by a pretrained language model, enabling robust recognition of ambiguous or fragmented text. Experiments on ICDAR 2015 and Total-Text demonstrate that TiCLS achieves state-of-the-art performance, validating the effectiveness of PLM-guided linguistic integration for scene text spotting.
Improved Point Transformation Methods For Self-Supervised Depth Prediction
Feb 18, 2021
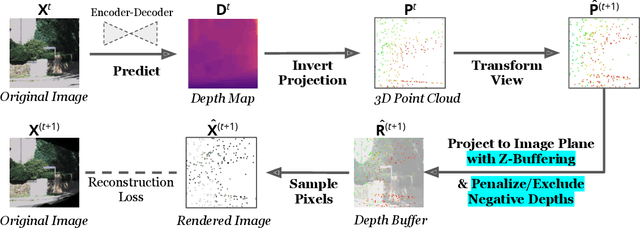
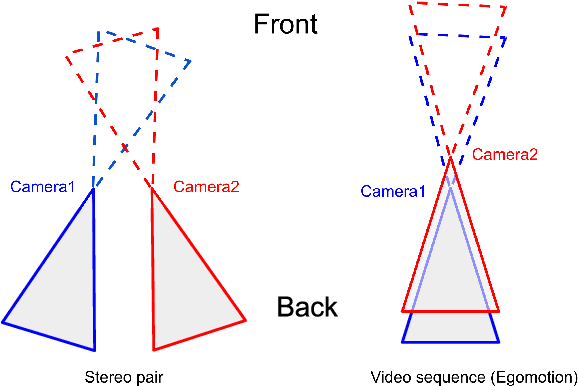
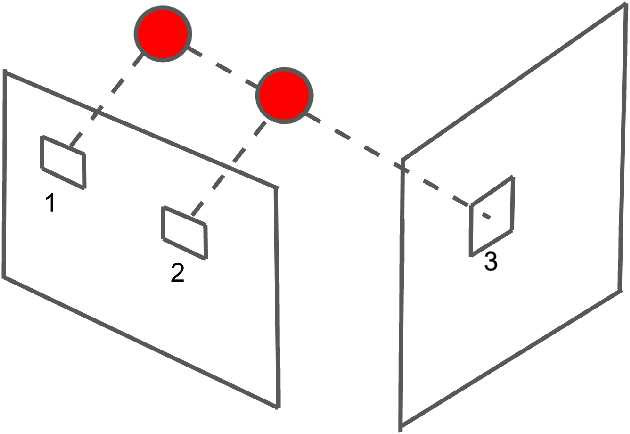
Given stereo or egomotion image pairs, a popular and successful method for unsupervised learning of monocular depth estimation is to measure the quality of image reconstructions resulting from the learned depth predictions. Continued research has improved the overall approach in recent years, yet the common framework still suffers from several important limitations, particularly when dealing with points occluded after transformation to a novel viewpoint. While prior work has addressed this problem heuristically, this paper introduces a z-buffering algorithm that correctly and efficiently handles occluded points. Because our algorithm is implemented with operators typical of machine learning libraries, it can be incorporated into any existing unsupervised depth learning framework with automatic support for differentiation. Additionally, because points having negative depth after transformation often signify erroneously shallow depth predictions, we introduce a loss function to penalize this undesirable behavior explicitly. Experimental results on the KITTI data set show that the z-buffer and negative depth loss both improve the performance of a state of the art depth-prediction network.