 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Point Transformation Methods For Self-Supervised Depth Prediction
Paper and Code

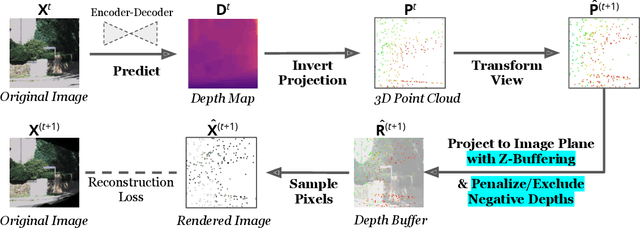
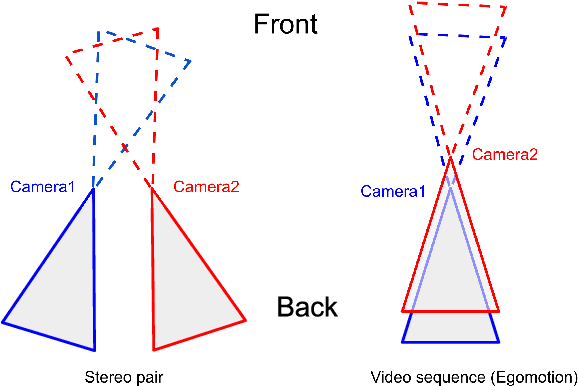
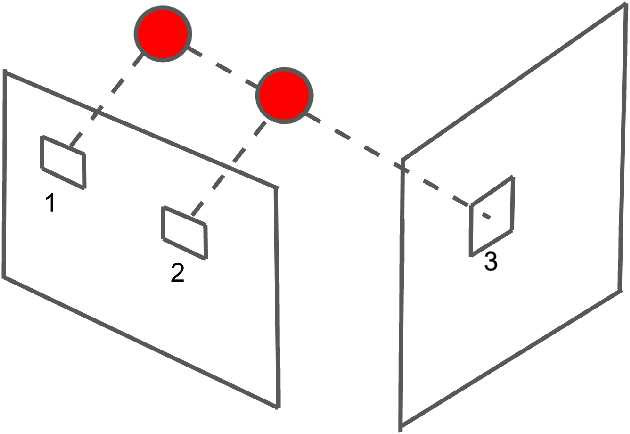
Given stereo or egomotion image pairs, a popular and successful method for unsupervised learning of monocular depth estimation is to measure the quality of image reconstructions resulting from the learned depth predictions. Continued research has improved the overall approach in recent years, yet the common framework still suffers from several important limitations, particularly when dealing with points occluded after transformation to a novel viewpoint. While prior work has addressed this problem heuristically, this paper introduces a z-buffering algorithm that correctly and efficiently handles occluded points. Because our algorithm is implemented with operators typical of machine learning libraries, it can be incorporated into any existing unsupervised depth learning framework with automatic support for differentiation. Additionally, because points having negative depth after transformation often signify erroneously shallow depth predictions, we introduce a loss function to penalize this undesirable behavior explicitly. Experimental results on the KITTI data set show that the z-buffer and negative depth loss both improve the performance of a state of the art depth-prediction network.