 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL3C-Stereo: Lossless Compression for Stereo Images
Aug 21, 2021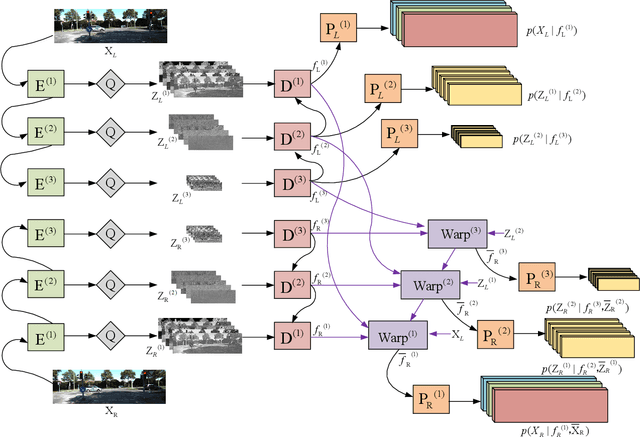
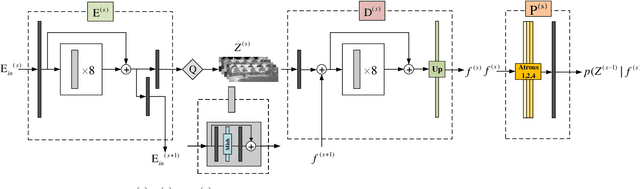
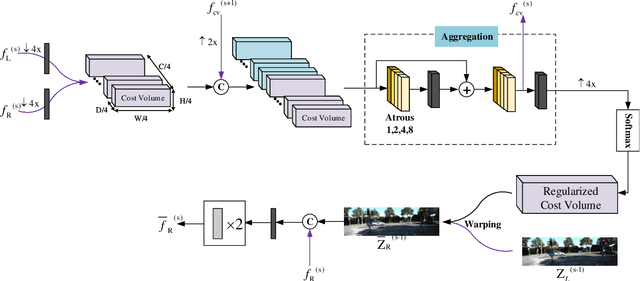

A large number of autonomous driving tasks need high-definition stereo images, which requires a large amount of storage space. Efficiently executing lossless compression has become a practical problem. Commonly, it is hard to make accurate probability estimates for each pixel. To tackle this, we propose L3C-Stereo, a multi-scale lossless compression model consisting of two main modules: the warping module and the probability estimation module. The warping module takes advantage of two view feature maps from the same domain to generate a disparity map, which is used to reconstruct the right view so as to improve the confidence of the probability estimate of the right view. The probability estimation module provides pixel-wise logistic mixture distributions for adaptive arithmetic coding. In the experiments, our method outperforms the hand-crafted compression methods and the learning-based method on all three datasets used. Then, we show that a better maximum disparity can lead to a better compression effect. Furthermore, thanks to a compression property of our model, it naturally generates a disparity map of an acceptable quality for the subsequent stereo tasks.
Serial-EMD: Fast Empirical Mode Decomposition Method for Multi-dimensional Signals Based on Serialization
Jun 22, 2021


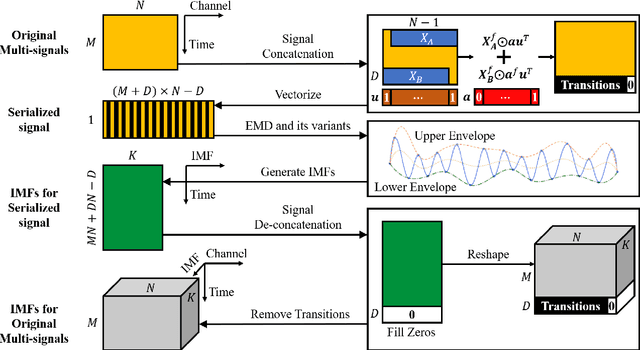
Empirical mode decomposition (EMD) has developed into a prominent tool for adaptive, scale-based signal analysis in various fields like robotics, security and biomedical engineering. Since the dramatic increase in amount of data puts forward higher requirements for the capability of real-time signal analysis, it is difficult for existing EMD and its variants to trade off the growth of data dimension and the speed of signal analysis. In order to decompose multi-dimensional signals at a faster speed, we present a novel signal-serialization method (serial-EMD), which concatenates multi-variate or multi-dimensional signals into a one-dimensional signal and uses various one-dimensional EMD algorithms to decompose it. To verify the effects of the proposed method, synthetic multi-variate time series, artificial 2D images with various textures and real-world facial images are tested. Compared with existing multi-EMD algorithms, the decomposition time becomes significantly reduced. In addition, the results of facial recognition with Intrinsic Mode Functions (IMFs) extracted using our method can achieve a higher accuracy than those obtained by existing multi-EMD algorithms, which demonstrates the superior performance of our method in terms of the quality of IMFs. Furthermore, this method can provide a new perspective to optimize the existing EMD algorithms, that is, transforming the structure of the input signal rather than being constrained by developing envelope computation techniques or signal decomposition methods. In summary, the study suggests that the serial-EMD technique is a highly competitive and fast alternative for multi-dimensional signal analysis.
H-OWAN: Multi-distorted Image Restoration with Tensor 1x1 Convolution
Jan 29, 2020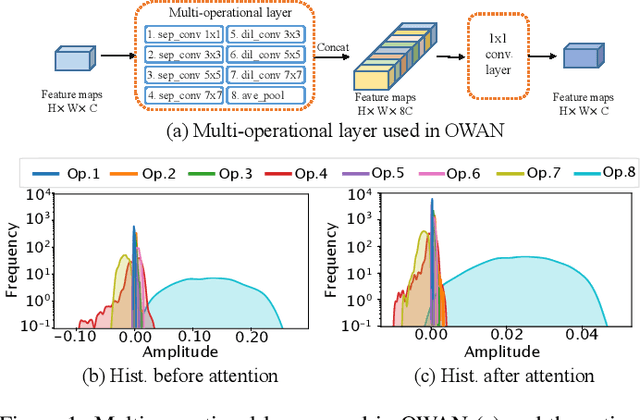
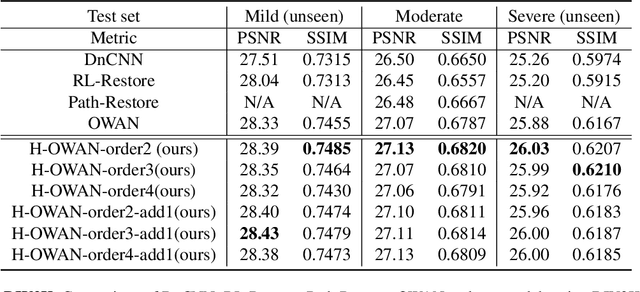
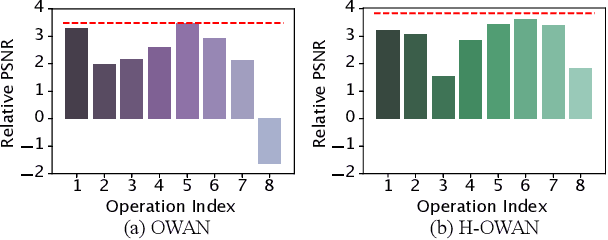
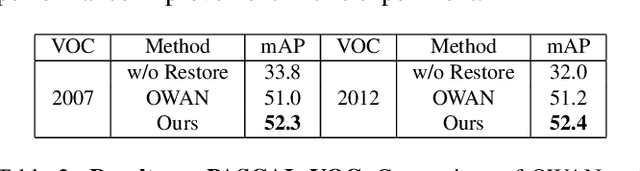
It is a challenging task to restore images from their variants with combined distortions. In the existing works, a promising strategy is to apply parallel "operations" to handle different types of distortion. However, in the feature fusion phase, a small number of operations would dominate the restoration result due to the features' heterogeneity by different operations. To this end, we introduce the tensor 1x1 convolutional layer by imposing high-order tensor (outer) product, by which we not only harmonize the heterogeneous features but also take additional non-linearity into account. To avoid the unacceptable kernel size resulted from the tensor product, we construct the kernels with tensor network decomposition, which is able to convert the exponential growth of the dimension to linear growth. Armed with the new layer, we propose High-order OWAN for multi-distorted image restoration. In the numerical experiments, the proposed net outperforms the previous state-of-the-art and shows promising performance even in more difficult tasks.