 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecycling diverse models for out-of-distribution generalization
Paper and Code
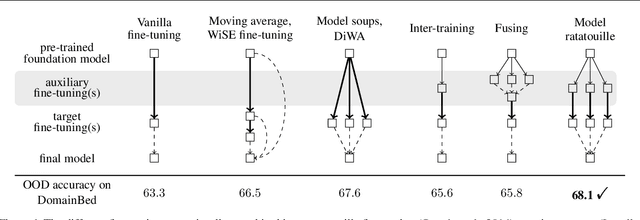

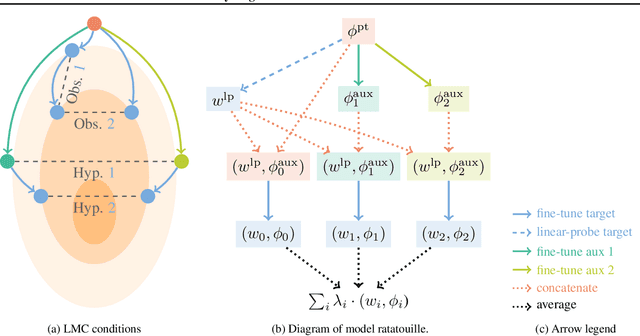

Foundation models are redefining how AI systems are built. Practitioners now follow a standard procedure to build their machine learning solutions: download a copy of a foundation model, and fine-tune it using some in-house data about the target task of interest. Consequently, the Internet is swarmed by a handful of foundation models fine-tuned on many diverse tasks. Yet, these individual fine-tunings often lack strong generalization and exist in isolation without benefiting from each other. In our opinion, this is a missed opportunity, as these specialized models contain diverse features. Based on this insight, we propose model recycling, a simple strategy that leverages multiple fine-tunings of the same foundation model on diverse auxiliary tasks, and repurposes them as rich and diverse initializations for the target task. Specifically, model recycling fine-tunes in parallel each specialized model on the target task, and then averages the weights of all target fine-tunings into a final model. Empirically, we show that model recycling maximizes model diversity by benefiting from diverse auxiliary tasks, and achieves a new state of the art on the reference DomainBed benchmark for out-of-distribution generalization. Looking forward, model recycling is a contribution to the emerging paradigm of updatable machine learning where, akin to open-source software development, the community collaborates to incrementally and reliably update machine learning models.