 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Head Distillation for Continual Unsupervised Domain Adaptation in Semantic Segmentation
Apr 25, 2022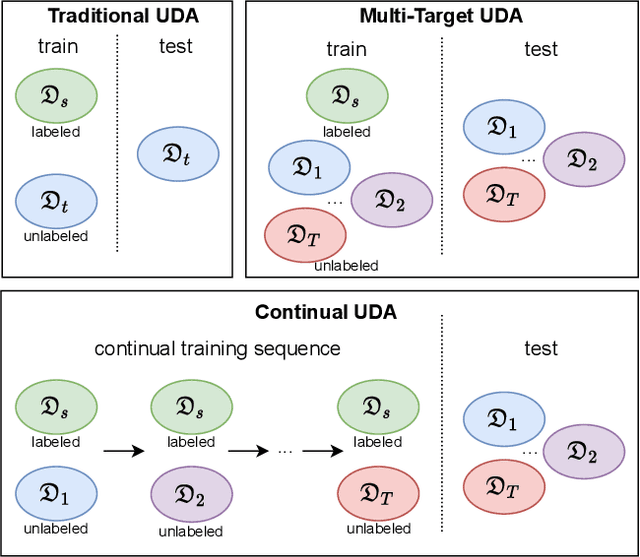
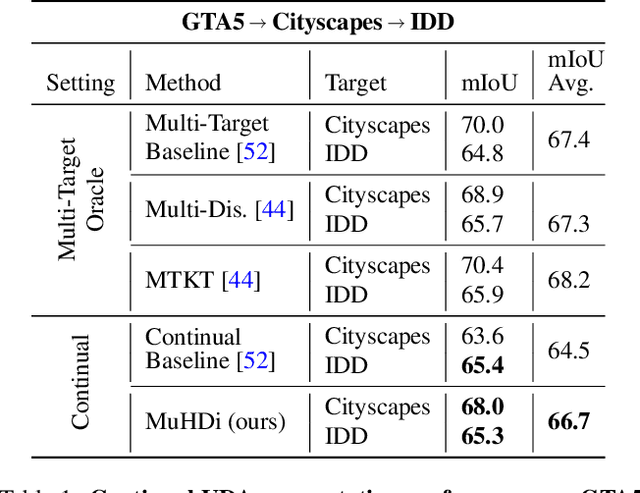
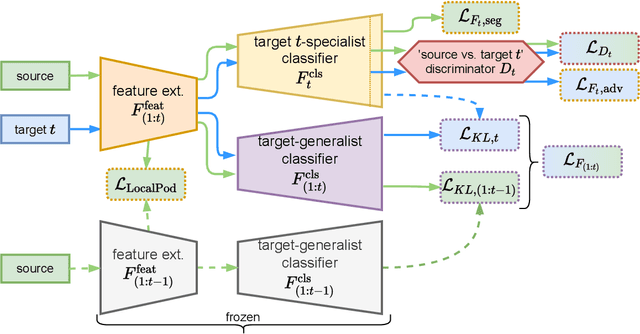
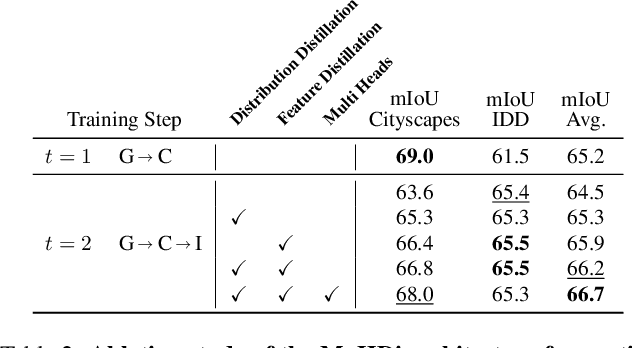
Unsupervised Domain Adaptation (UDA) is a transfer learning task which aims at training on an unlabeled target domain by leveraging a labeled source domain. Beyond the traditional scope of UDA with a single source domain and a single target domain, real-world perception systems face a variety of scenarios to handle, from varying lighting conditions to many cities around the world. In this context, UDAs with several domains increase the challenges with the addition of distribution shifts within the different target domains. This work focuses on a novel framework for learning UDA, continuous UDA, in which models operate on multiple target domains discovered sequentially, without access to previous target domains. We propose MuHDi, for Multi-Head Distillation, a method that solves the catastrophic forgetting problem, inherent in continual learning tasks. MuHDi performs distillation at multiple levels from the previous model as well as an auxiliary target-specialist segmentation head. We report both extensive ablation and experiments on challenging multi-target UDA semantic segmentation benchmarks to validate the proposed learning scheme and architecture.
Multi-Target Adversarial Frameworks for Domain Adaptation in Semantic Segmentation
Aug 16, 2021

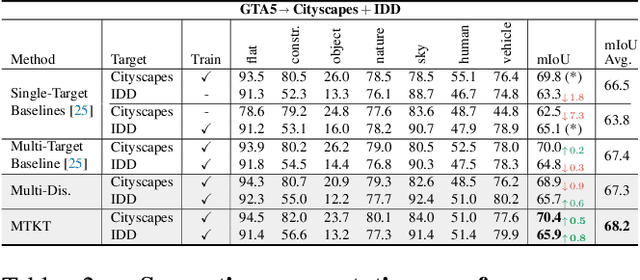

In this work, we address the task of unsupervised domain adaptation (UDA) for semantic segmentation in presence of multiple target domains: The objective is to train a single model that can handle all these domains at test time. Such a multi-target adaptation is crucial for a variety of scenarios that real-world autonomous systems must handle. It is a challenging setup since one faces not only the domain gap between the labeled source set and the unlabeled target set, but also the distribution shifts existing within the latter among the different target domains. To this end, we introduce two adversarial frameworks: (i) multi-discriminator, which explicitly aligns each target domain to its counterparts, and (ii) multi-target knowledge transfer, which learns a target-agnostic model thanks to a multi-teacher/single-student distillation mechanism.The evaluation is done on four newly-proposed multi-target benchmarks for UDA in semantic segmentation. In all tested scenarios, our approaches consistently outperform baselines, setting competitive standards for the novel task.
Confidence Estimation via Auxiliary Models
Dec 11, 2020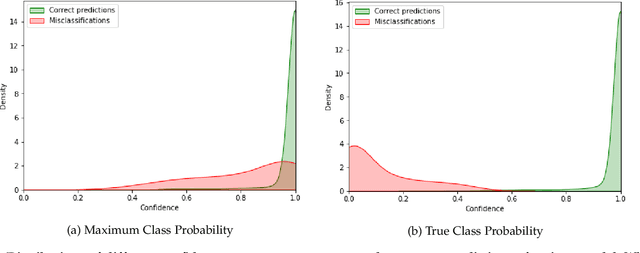
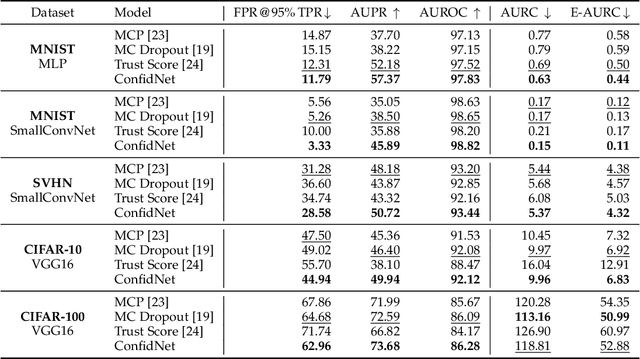
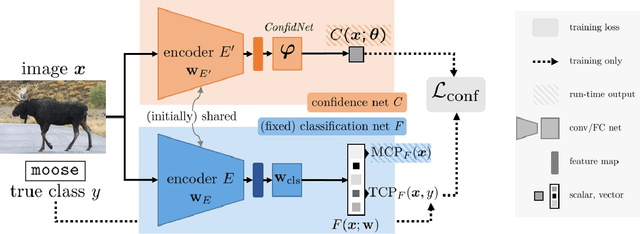

Reliably quantifying the confidence of deep neural classifiers is a challenging yet fundamental requirement for deploying such models in safety-critical applications. In this paper, we introduce a novel target criterion for model confidence, namely the true class probability (TCP). We show that TCP offers better properties for confidence estimation than standard maximum class probability (MCP). Since the true class is by essence unknown at test time, we propose to learn TCP criterion from data with an auxiliary model, introducing a specific learning scheme adapted to this context. We evaluate our approach on the task of failure prediction and of self-training with pseudo-labels for domain adaptation, which both necessitate effective confidence estimates. Extensive experiments are conducted for validating the relevance of the proposed approach in each task. We study various network architectures and experiment with small and large datasets for image classification and semantic segmentation. In every tested benchmark, our approach outperforms strong baselines.
ESL: Entropy-guided Self-supervised Learning for Domain Adaptation in Semantic Segmentation
Jun 15, 2020
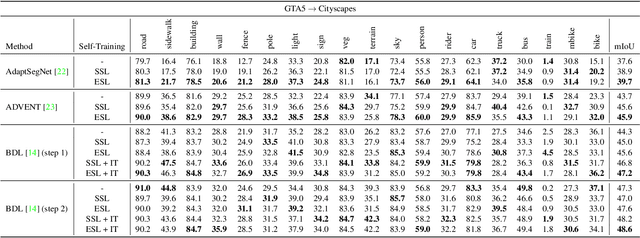


While fully-supervised deep learning yields good models for urban scene semantic segmentation, these models struggle to generalize to new environments with different lighting or weather conditions for instance. In addition, producing the extensive pixel-level annotations that the task requires comes at a great cost. Unsupervised domain adaptation (UDA) is one approach that tries to address these issues in order to make such systems more scalable. In particular, self-supervised learning (SSL) has recently become an effective strategy for UDA in semantic segmentation. At the core of such methods lies `pseudo-labeling', that is, the practice of assigning high-confident class predictions as pseudo-labels, subsequently used as true labels, for target data. To collect pseudo-labels, previous works often rely on the highest softmax score, which we here argue as an unfavorable confidence measurement. In this work, we propose Entropy-guided Self-supervised Learning (ESL), leveraging entropy as the confidence indicator for producing more accurate pseudo-labels. On different UDA benchmarks, ESL consistently outperforms strong SSL baselines and achieves state-of-the-art results.
REVE: Regularizing Deep Learning with Variational Entropy Bound
Oct 15, 2019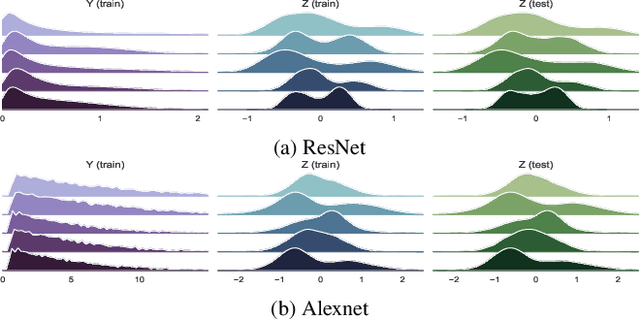
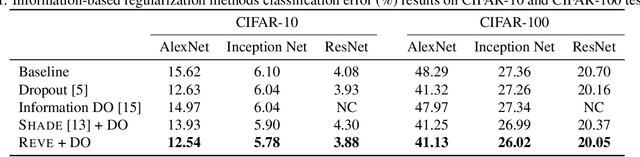

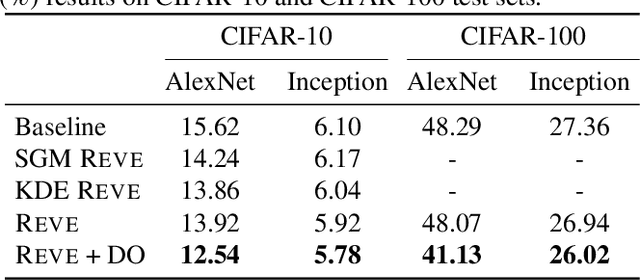
Studies on generalization performance of machine learning algorithms under the scope of information theory suggest that compressed representations can guarantee good generalization, inspiring many compression-based regularization methods. In this paper, we introduce REVE, a new regularization scheme. Noting that compressing the representation can be sub-optimal, our first contribution is to identify a variable that is directly responsible for the final prediction. Our method aims at compressing the class conditioned entropy of this latter variable. Second, we introduce a variational upper bound on this conditional entropy term. Finally, we propose a scheme to instantiate a tractable loss that is integrated within the training procedure of the neural network and demonstrate its efficiency on different neural networks and datasets.