 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Tokens to Policy: Causal and Interpretable Heterogeneous Treatment Effects Identification
Jun 15, 2026Heterogeneous Treatment Effect (HTE) identification is crucial to explain the impact of an intervention and optimize our policies accordingly. Existing approaches trade expressivity for interpretability, but, if some active heterogeneity drivers are unmeasured, methods at both ends of this spectrum allow for spurious HTE characterization with no causal reading. In this work, we focus on controlled experiments and argue that an oracle HTE causal characterization via the latent interactors is now within reach, thanks to (i) more extensive pre-treatment measurements, i.e., multi-modal and multi-view, and (ii) scalable representations with minimal human supervision. We then re-frame HTE identification as a Markov-blanket discovery problem on a sufficient and aligned pre-treatment representation, and introduce Neural EXposure Interaction Search (NEXIS), an iterative procedure with provable and empirically validated consistent selection. We deploy NEXIS on two anti-poverty programs in Africa, augmenting each with satellite imagery capturing previously unmeasured environmental effect modifiers, leading to novel, interpretable and prescriptive guidelines to optimize the programs' next iterations.
Exploratory Causal Inference in SAEnce
Oct 15, 2025Randomized Controlled Trials are one of the pillars of science; nevertheless, they rely on hand-crafted hypotheses and expensive analysis. Such constraints prevent causal effect estimation at scale, potentially anchoring on popular yet incomplete hypotheses. We propose to discover the unknown effects of a treatment directly from data. For this, we turn unstructured data from a trial into meaningful representations via pretrained foundation models and interpret them via a sparse autoencoder. However, discovering significant causal effects at the neural level is not trivial due to multiple-testing issues and effects entanglement. To address these challenges, we introduce Neural Effect Search, a novel recursive procedure solving both issues by progressive stratification. After assessing the robustness of our algorithm on semi-synthetic experiments, we showcase, in the context of experimental ecology, the first successful unsupervised causal effect identification on a real-world scientific trial.
The Third Pillar of Causal Analysis? A Measurement Perspective on Causal Representations
May 23, 2025Causal reasoning and discovery, two fundamental tasks of causal analysis, often face challenges in applications due to the complexity, noisiness, and high-dimensionality of real-world data. Despite recent progress in identifying latent causal structures using causal representation learning (CRL), what makes learned representations useful for causal downstream tasks and how to evaluate them are still not well understood. In this paper, we reinterpret CRL using a measurement model framework, where the learned representations are viewed as proxy measurements of the latent causal variables. Our approach clarifies the conditions under which learned representations support downstream causal reasoning and provides a principled basis for quantitatively assessing the quality of representations using a new Test-based Measurement EXclusivity (T-MEX) score. We validate T-MEX across diverse causal inference scenarios, including numerical simulations and real-world ecological video analysis, demonstrating that the proposed framework and corresponding score effectively assess the identification of learned representations and their usefulness for causal downstream tasks.
Causal Lifting of Neural Representations: Zero-Shot Generalization for Causal Inferences
Feb 10, 2025



A plethora of real-world scientific investigations is waiting to scale with the support of trustworthy predictive models that can reduce the need for costly data annotations. We focus on causal inferences on a target experiment with unlabeled factual outcomes, retrieved by a predictive model fine-tuned on a labeled similar experiment. First, we show that factual outcome estimation via Empirical Risk Minimization (ERM) may fail to yield valid causal inferences on the target population, even in a randomized controlled experiment and infinite training samples. Then, we propose to leverage the observed experimental settings during training to empower generalization to downstream interventional investigations, ``Causal Lifting'' the predictive model. We propose Deconfounded Empirical Risk Minimization (DERM), a new simple learning procedure minimizing the risk over a fictitious target population, preventing potential confounding effects. We validate our method on both synthetic and real-world scientific data. Notably, for the first time, we zero-shot generalize causal inferences on ISTAnt dataset (without annotation) by causal lifting a predictive model on our experiment variant.
Unifying Causal Representation Learning with the Invariance Principle
Sep 04, 2024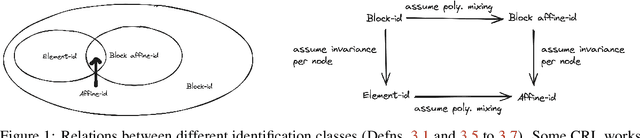
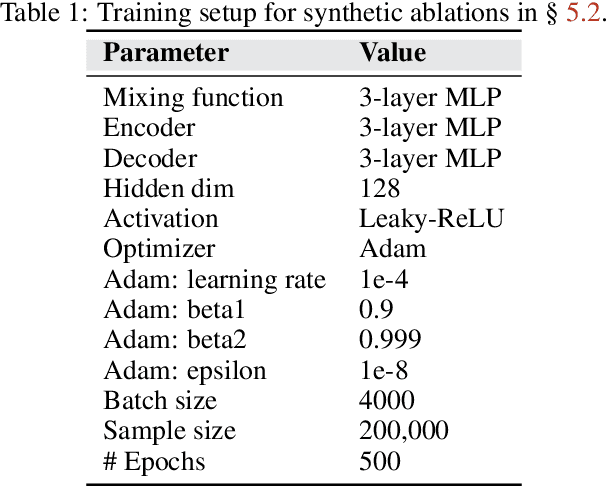
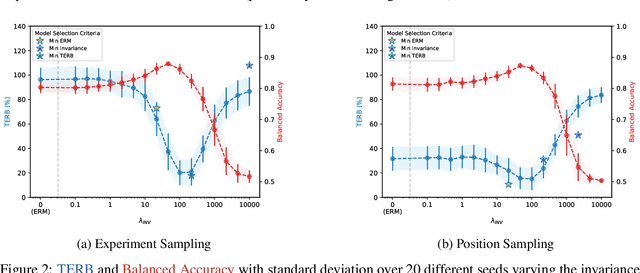

Causal representation learning aims at recovering latent causal variables from high-dimensional observations to solve causal downstream tasks, such as predicting the effect of new interventions or more robust classification. A plethora of methods have been developed, each tackling carefully crafted problem settings that lead to different types of identifiability. The folklore is that these different settings are important, as they are often linked to different rungs of Pearl's causal hierarchy, although not all neatly fit. Our main contribution is to show that many existing causal representation learning approaches methodologically align the representation to known data symmetries. Identification of the variables is guided by equivalence classes across different data pockets that are not necessarily causal. This result suggests important implications, allowing us to unify many existing approaches in a single method that can mix and match different assumptions, including non-causal ones, based on the invariances relevant to our application. It also significantly benefits applicability, which we demonstrate by improving treatment effect estimation on real-world high-dimensional ecological data. Overall, this paper clarifies the role of causality assumptions in the discovery of causal variables and shifts the focus to preserving data symmetries.
Smoke and Mirrors in Causal Downstream Tasks
May 27, 2024



Machine Learning and AI have the potential to transform data-driven scientific discovery, enabling accurate predictions for several scientific phenomena. As many scientific questions are inherently causal, this paper looks at the causal inference task of treatment effect estimation, where we assume binary effects that are recorded as high-dimensional images in a Randomized Controlled Trial (RCT). Despite being the simplest possible setting and a perfect fit for deep learning, we theoretically find that many common choices in the literature may lead to biased estimates. To test the practical impact of these considerations, we recorded the first real-world benchmark for causal inference downstream tasks on high-dimensional observations as an RCT studying how garden ants (Lasius neglectus) respond to microparticles applied onto their colony members by hygienic grooming. Comparing 6 480 models fine-tuned from state-of-the-art visual backbones, we find that the sampling and modeling choices significantly affect the accuracy of the causal estimate, and that classification accuracy is not a proxy thereof. We further validated the analysis, repeating it on a synthetically generated visual data set controlling the causal model. Our results suggest that future benchmarks should carefully consider real downstream scientific questions, especially causal ones. Further, we highlight guidelines for representation learning methods to help answer causal questions in the sciences. All code and data will be released.
Towards Robust and Adaptive Motion Forecasting: A Causal Representation Perspective
Nov 29, 2021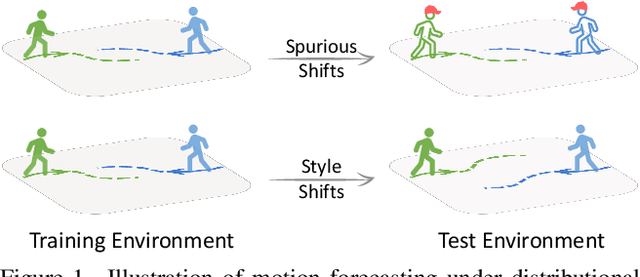



Learning behavioral patterns from observational data has been a de-facto approach to motion forecasting. Yet, the current paradigm suffers from two shortcomings: brittle under covariate shift and inefficient for knowledge transfer. In this work, we propose to address these challenges from a causal representation perspective. We first introduce a causal formalism of motion forecasting, which casts the problem as a dynamic process with three groups of latent variables, namely invariant mechanisms, style confounders, and spurious features. We then introduce a learning framework that treats each group separately: (i) unlike the common practice of merging datasets collected from different locations, we exploit their subtle distinctions by means of an invariance loss encouraging the model to suppress spurious correlations; (ii) we devise a modular architecture that factorizes the representations of invariant mechanisms and style confounders to approximate a causal graph; (iii) we introduce a style consistency loss that not only enforces the structure of style representations but also serves as a self-supervisory signal for test-time refinement on the fly. Experiment results on synthetic and real datasets show that our three proposed components significantly improve the robustness and reusability of the learned motion representations, outperforming prior state-of-the-art motion forecasting models for out-of-distribution generalization and low-shot transfer.