 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Causal Representation Learning with the Invariance Principle
Paper and Code
Sep 04, 2024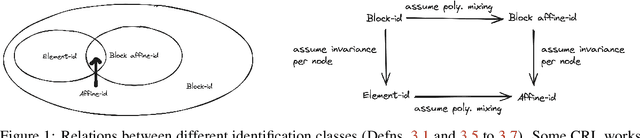
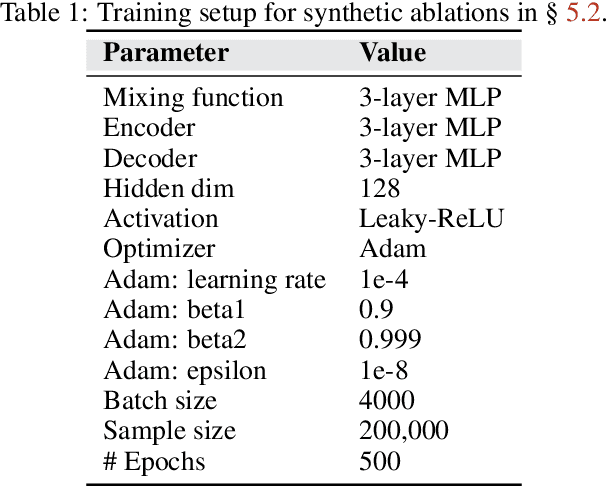
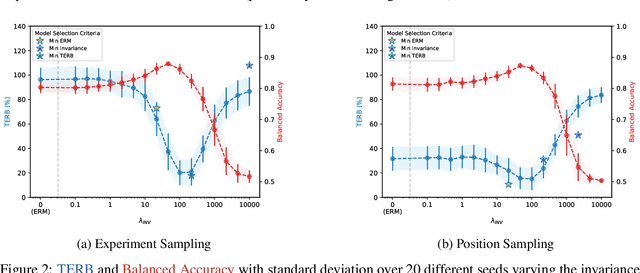

Causal representation learning aims at recovering latent causal variables from high-dimensional observations to solve causal downstream tasks, such as predicting the effect of new interventions or more robust classification. A plethora of methods have been developed, each tackling carefully crafted problem settings that lead to different types of identifiability. The folklore is that these different settings are important, as they are often linked to different rungs of Pearl's causal hierarchy, although not all neatly fit. Our main contribution is to show that many existing causal representation learning approaches methodologically align the representation to known data symmetries. Identification of the variables is guided by equivalence classes across different data pockets that are not necessarily causal. This result suggests important implications, allowing us to unify many existing approaches in a single method that can mix and match different assumptions, including non-causal ones, based on the invariances relevant to our application. It also significantly benefits applicability, which we demonstrate by improving treatment effect estimation on real-world high-dimensional ecological data. Overall, this paper clarifies the role of causality assumptions in the discovery of causal variables and shifts the focus to preserving data symmetries.