 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeam voyTECH: User Activity Modeling with Boosting Trees
Jul 03, 2020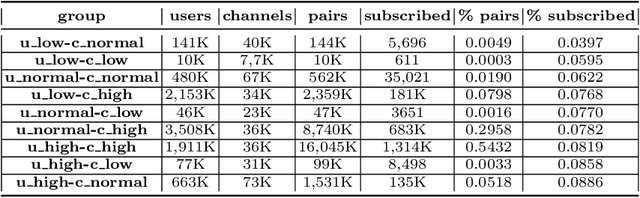
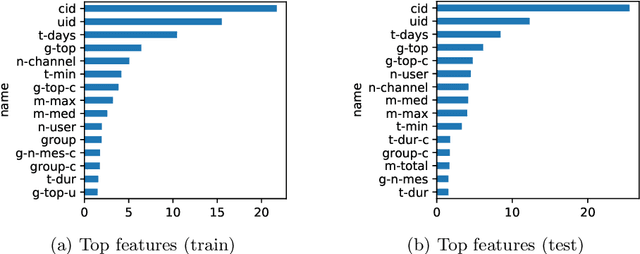
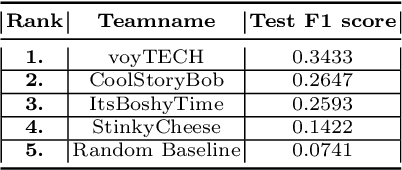
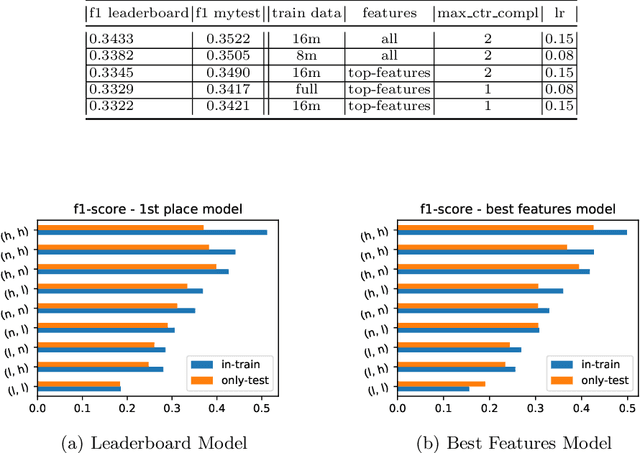
This paper describes our winning solution for the ECML-PKDD ChAT Discovery Challenge 2020. We show that whether or not a Twitch user has subscribed to a channel can be well predicted by modeling user activity with boosting trees. We introduce the connection between target-encodings and boosting trees in the context of high cardinality categoricals and find that modeling user activity is more powerful then direct modeling of content when encoded properly and combined with a suitable optimization approach.
Graph Based Relational Features for Collective Classification
Feb 09, 2017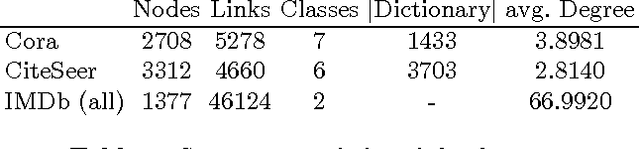
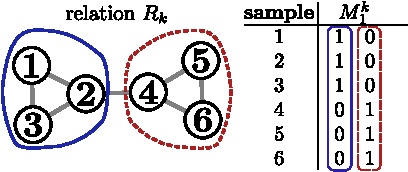
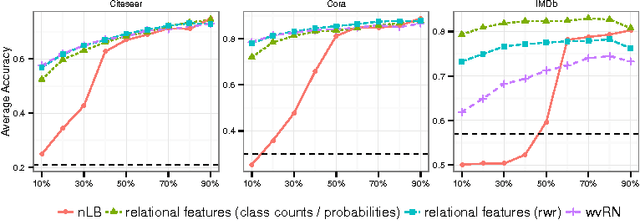
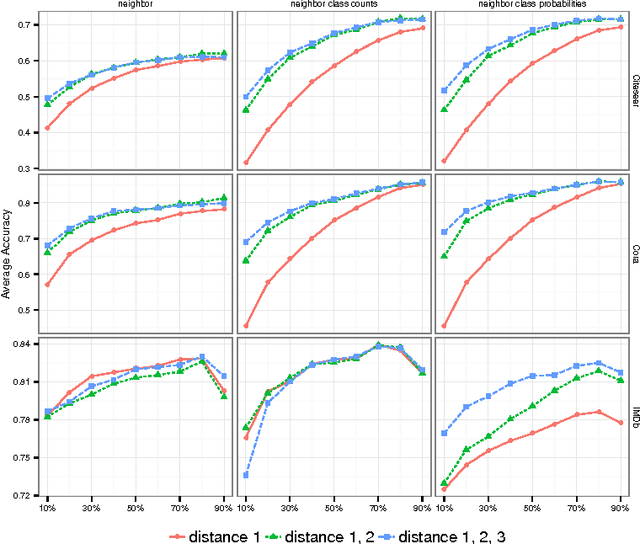
Statistical Relational Learning (SRL) methods have shown that classification accuracy can be improved by integrating relations between samples. Techniques such as iterative classification or relaxation labeling achieve this by propagating information between related samples during the inference process. When only a few samples are labeled and connections between samples are sparse, collective inference methods have shown large improvements over standard feature-based ML methods. However, in contrast to feature based ML, collective inference methods require complex inference procedures and often depend on the strong assumption of label consistency among related samples. In this paper, we introduce new relational features for standard ML methods by extracting information from direct and indirect relations. We show empirically on three standard benchmark datasets that our relational features yield results comparable to collective inference methods. Finally we show that our proposal outperforms these methods when additional information is available.
fastFM: A Library for Factorization Machines
Nov 23, 2016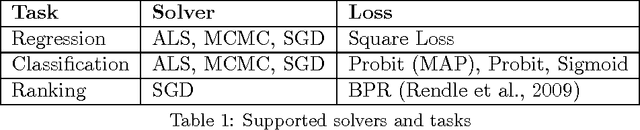
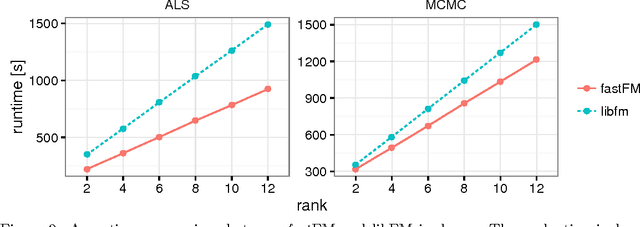
Factorization Machines (FM) are only used in a narrow range of applications and are not part of the standard toolbox of machine learning models. This is a pity, because even though FMs are recognized as being very successful for recommender system type applications they are a general model to deal with sparse and high dimensional features. Our Factorization Machine implementation provides easy access to many solvers and supports regression, classification and ranking tasks. Such an implementation simplifies the use of FM's for a wide field of applications. This implementation has the potential to improve our understanding of the FM model and drive new development.
* Source Code is available at https://github.com/ibayer/fastFM
A Generic Coordinate Descent Framework for Learning from Implicit Feedback
Nov 15, 2016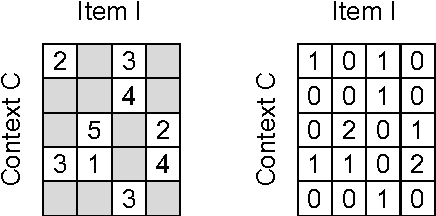
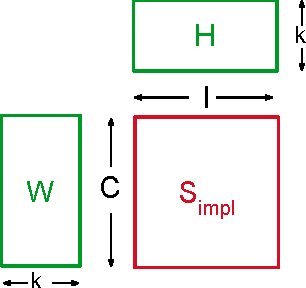
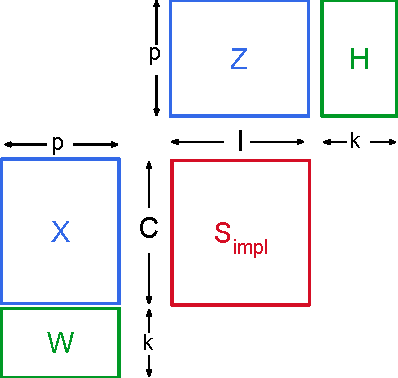
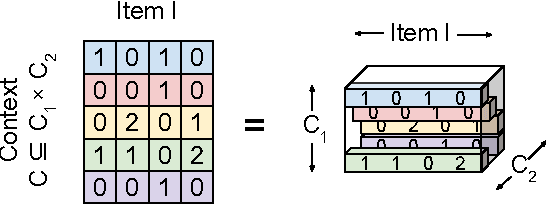
In recent years, interest in recommender research has shifted from explicit feedback towards implicit feedback data. A diversity of complex models has been proposed for a wide variety of applications. Despite this, learning from implicit feedback is still computationally challenging. So far, most work relies on stochastic gradient descent (SGD) solvers which are easy to derive, but in practice challenging to apply, especially for tasks with many items. For the simple matrix factorization model, an efficient coordinate descent (CD) solver has been previously proposed. However, efficient CD approaches have not been derived for more complex models. In this paper, we provide a new framework for deriving efficient CD algorithms for complex recommender models. We identify and introduce the property of k-separable models. We show that k-separability is a sufficient property to allow efficient optimization of implicit recommender problems with CD. We illustrate this framework on a variety of state-of-the-art models including factorization machines and Tucker decomposition. To summarize, our work provides the theory and building blocks to derive efficient implicit CD algorithms for complex recommender models.