 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVE: A Product Dataset for Multi-source Attribute Value Extraction
Dec 16, 2021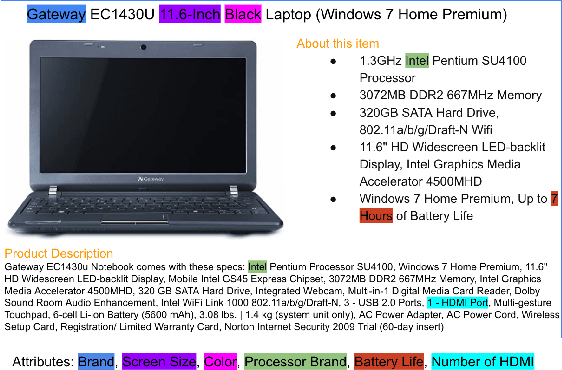
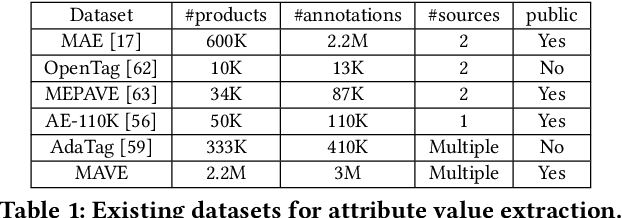

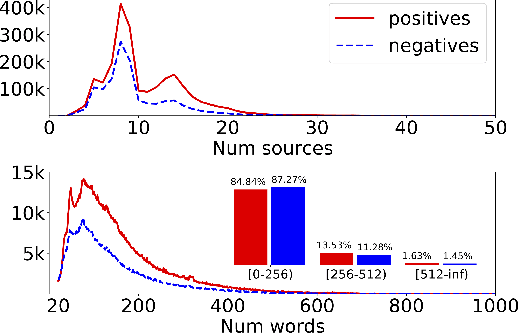
Attribute value extraction refers to the task of identifying values of an attribute of interest from product information. Product attribute values are essential in many e-commerce scenarios, such as customer service robots, product ranking, retrieval and recommendations. While in the real world, the attribute values of a product are usually incomplete and vary over time, which greatly hinders the practical applications. In this paper, we introduce MAVE, a new dataset to better facilitate research on product attribute value extraction. MAVE is composed of a curated set of 2.2 million products from Amazon pages, with 3 million attribute-value annotations across 1257 unique categories. MAVE has four main and unique advantages: First, MAVE is the largest product attribute value extraction dataset by the number of attribute-value examples. Second, MAVE includes multi-source representations from the product, which captures the full product information with high attribute coverage. Third, MAVE represents a more diverse set of attributes and values relative to what previous datasets cover. Lastly, MAVE provides a very challenging zero-shot test set, as we empirically illustrate in the experiments. We further propose a novel approach that effectively extracts the attribute value from the multi-source product information. We conduct extensive experiments with several baselines and show that MAVE is an effective dataset for attribute value extraction task. It is also a very challenging task on zero-shot attribute extraction. Data is available at {\it \url{https://github.com/google-research-datasets/MAVE}}.
Machine Learning and Data Analytics for Design and Manufacturing of High-Entropy Materials Exhibiting Mechanical or Fatigue Properties of Interest
Dec 05, 2020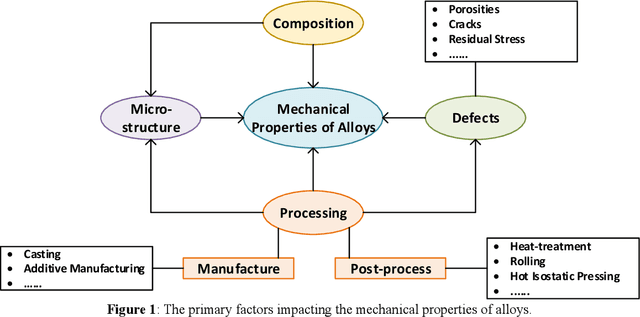
This chapter presents an innovative framework for the application of machine learning and data analytics for the identification of alloys or composites exhibiting certain desired properties of interest. The main focus is on alloys and composites with large composition spaces for structural materials. Such alloys or composites are referred to as high-entropy materials (HEMs) and are here presented primarily in context of structural applications. For each output property of interest, the corresponding driving (input) factors are identified. These input factors may include the material composition, heat treatment, manufacturing process, microstructure, temperature, strain rate, environment, or testing mode. The framework assumes the selection of an optimization technique suitable for the application at hand and the data available. Physics-based models are presented, such as for predicting the ultimate tensile strength (UTS) or fatigue resistance. We devise models capable of accounting for physics-based dependencies. We factor such dependencies into the models as a priori information. In case that an artificial neural network (ANN) is deemed suitable for the applications at hand, it is suggested to employ custom kernel functions consistent with the underlying physics, for the purpose of attaining tighter coupling, better prediction, and for extracting the most out of the - usually limited - input data available.
* Machine learning, Data analytics, Material design, Additive manufacturing, High-entropy material, Statistical regression, Sequential learning, Bayesian inference, Feature selection, Data curation, Inverse design representation, Forward prediction, Backward prediction, Joint optimization, Physics-based modeling, Reinforcement learning, Statistical fatigue life model, Low-data environment