 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Vector Quantization with Distributional Matching: A Theoretical and Empirical Study
Jun 18, 2025The success of autoregressive models largely depends on the effectiveness of vector quantization, a technique that discretizes continuous features by mapping them to the nearest code vectors within a learnable codebook. Two critical issues in existing vector quantization methods are training instability and codebook collapse. Training instability arises from the gradient discrepancy introduced by the straight-through estimator, especially in the presence of significant quantization errors, while codebook collapse occurs when only a small subset of code vectors are utilized during training. A closer examination of these issues reveals that they are primarily driven by a mismatch between the distributions of the features and code vectors, leading to unrepresentative code vectors and significant data information loss during compression. To address this, we employ the Wasserstein distance to align these two distributions, achieving near 100\% codebook utilization and significantly reducing the quantization error. Both empirical and theoretical analyses validate the effectiveness of the proposed approach.
Rethinking The Uniformity Metric in Self-Supervised Learning
Mar 01, 2024



Uniformity plays a crucial role in the assessment of learned representations, contributing to a deeper comprehension of self-supervised learning. The seminal work by \citet{Wang2020UnderstandingCR} introduced a uniformity metric that quantitatively measures the collapse degree of learned representations. Directly optimizing this metric together with alignment proves to be effective in preventing constant collapse. However, we present both theoretical and empirical evidence revealing that this metric lacks sensitivity to dimensional collapse, highlighting its limitations. To address this limitation and design a more effective uniformity metric, this paper identifies five fundamental properties, some of which the existing uniformity metric fails to meet. We subsequently introduce a novel uniformity metric that satisfies all of these desiderata and exhibits sensitivity to dimensional collapse. When applied as an auxiliary loss in various established self-supervised methods, our proposed uniformity metric consistently enhances their performance in downstream tasks.Our code was released at https://github.com/sunset-clouds/WassersteinUniformityMetric.
Discrete Auto-regressive Variational Attention Models for Text Modeling
Jun 16, 2021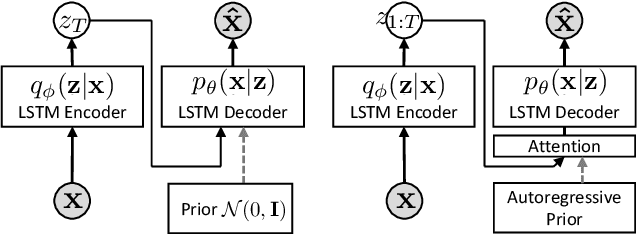

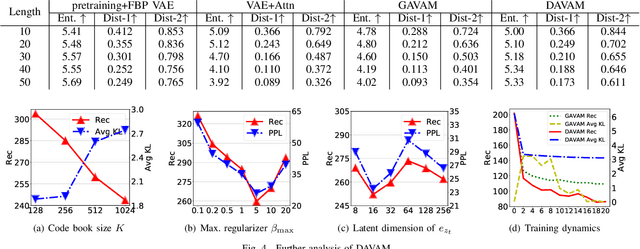

Variational autoencoders (VAEs) have been widely applied for text modeling. In practice, however, they are troubled by two challenges: information underrepresentation and posterior collapse. The former arises as only the last hidden state of LSTM encoder is transformed into the latent space, which is generally insufficient to summarize the data. The latter is a long-standing problem during the training of VAEs as the optimization is trapped to a disastrous local optimum. In this paper, we propose Discrete Auto-regressive Variational Attention Model (DAVAM) to address the challenges. Specifically, we introduce an auto-regressive variational attention approach to enrich the latent space by effectively capturing the semantic dependency from the input. We further design discrete latent space for the variational attention and mathematically show that our model is free from posterior collapse. Extensive experiments on language modeling tasks demonstrate the superiority of DAVAM against several VAE counterparts.
Discrete Variational Attention Models for Language Generation
Apr 21, 2020

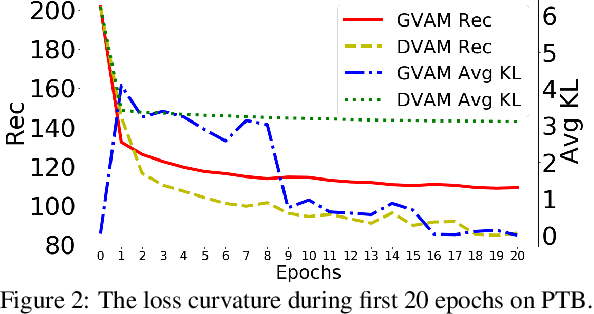

Variational autoencoders have been widely applied for natural language generation, however, there are two long-standing problems: information under-representation and posterior collapse. The former arises from the fact that only the last hidden state from the encoder is transformed to the latent space, which is insufficient to summarize data. The latter comes as a result of the imbalanced scale between the reconstruction loss and the KL divergence in the objective function. To tackle these issues, in this paper we propose the discrete variational attention model with categorical distribution over the attention mechanism owing to the discrete nature in languages. Our approach is combined with an auto-regressive prior to capture the sequential dependency from observations, which can enhance the latent space for language generation. Moreover, thanks to the property of discreteness, the training of our proposed approach does not suffer from posterior collapse. Furthermore, we carefully analyze the superiority of discrete latent space over the continuous space with the common Gaussian distribution. Extensive experiments on language generation demonstrate superior advantages of our proposed approach in comparison with the state-of-the-art counterparts.
DART: Domain-Adversarial Residual-Transfer Networks for Unsupervised Cross-Domain Image Classification
Dec 30, 2018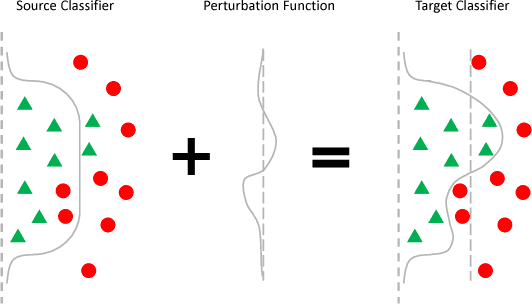

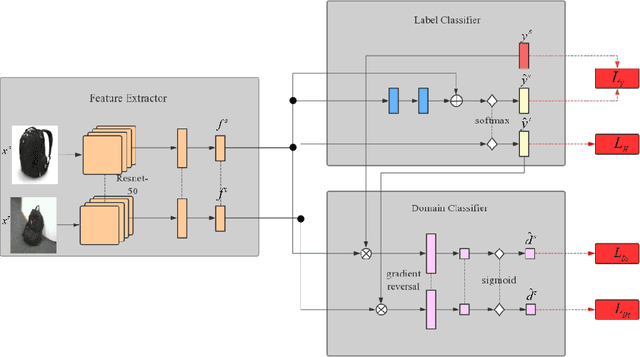
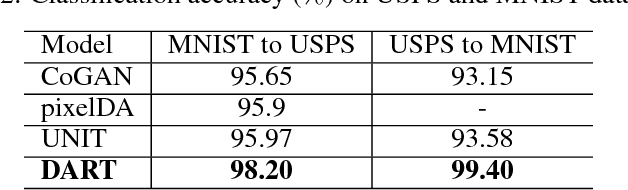
The accuracy of deep learning (e.g., convolutional neural networks) for an image classification task critically relies on the amount of labeled training data. Aiming to solve an image classification task on a new domain that lacks labeled data but gains access to cheaply available unlabeled data, unsupervised domain adaptation is a promising technique to boost the performance without incurring extra labeling cost, by assuming images from different domains share some invariant characteristics. In this paper, we propose a new unsupervised domain adaptation method named Domain-Adversarial Residual-Transfer (DART) learning of Deep Neural Networks to tackle cross-domain image classification tasks. In contrast to the existing unsupervised domain adaption approaches, the proposed DART not only learns domain-invariant features via adversarial training, but also achieves robust domain-adaptive classification via a residual-transfer strategy, all in an end-to-end training framework. We evaluate the performance of the proposed method for cross-domain image classification tasks on several well-known benchmark data sets, in which our method clearly outperforms the state-of-the-art approaches.