 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Variational Attention Models for Language Generation
Paper and Code


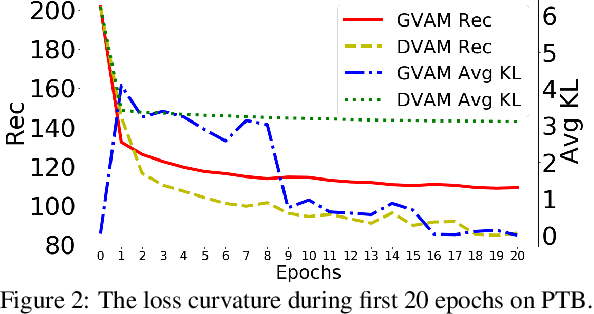

Variational autoencoders have been widely applied for natural language generation, however, there are two long-standing problems: information under-representation and posterior collapse. The former arises from the fact that only the last hidden state from the encoder is transformed to the latent space, which is insufficient to summarize data. The latter comes as a result of the imbalanced scale between the reconstruction loss and the KL divergence in the objective function. To tackle these issues, in this paper we propose the discrete variational attention model with categorical distribution over the attention mechanism owing to the discrete nature in languages. Our approach is combined with an auto-regressive prior to capture the sequential dependency from observations, which can enhance the latent space for language generation. Moreover, thanks to the property of discreteness, the training of our proposed approach does not suffer from posterior collapse. Furthermore, we carefully analyze the superiority of discrete latent space over the continuous space with the common Gaussian distribution. Extensive experiments on language generation demonstrate superior advantages of our proposed approach in comparison with the state-of-the-art counterparts.