 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDFM: Multi-Decision Fusing Model for Few-Shot Learning
Dec 03, 2021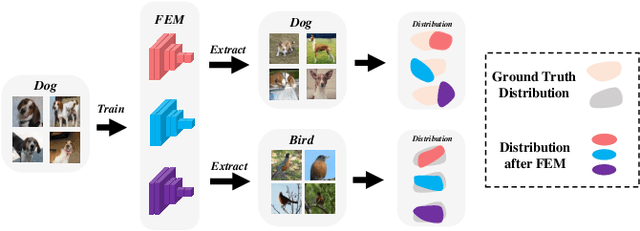
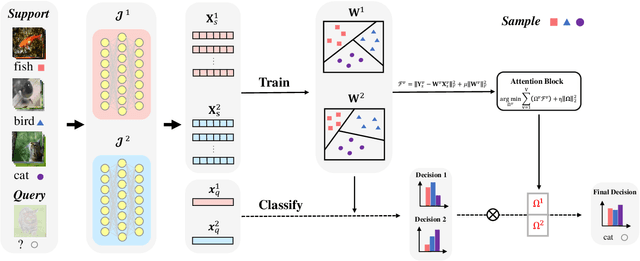
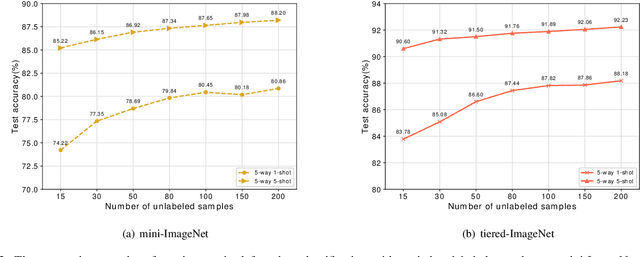
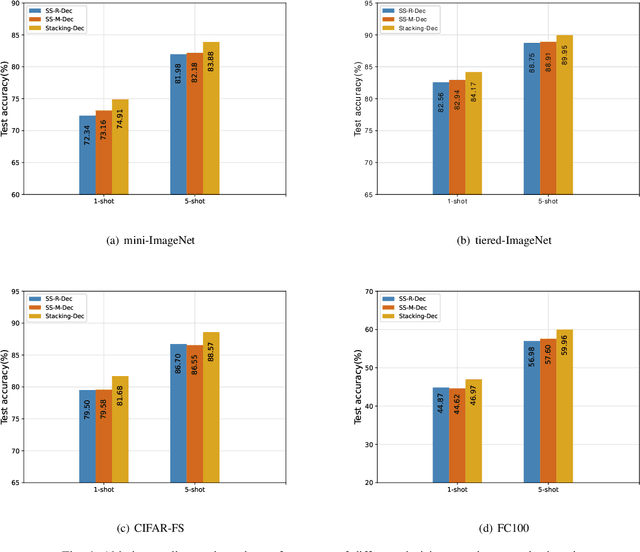
In recent years, researchers pay growing attention to the few-shot learning (FSL) task to address the data-scarce problem. A standard FSL framework is composed of two components: i) Pre-train. Employ the base data to generate a CNN-based feature extraction model (FEM). ii) Meta-test. Apply the trained FEM to the novel data (category is different from base data) to acquire the feature embeddings and recognize them. Although researchers have made remarkable breakthroughs in FSL, there still exists a fundamental problem. Since the trained FEM with base data usually cannot adapt to the novel class flawlessly, the novel data's feature may lead to the distribution shift problem. To address this challenge, we hypothesize that even if most of the decisions based on different FEMs are viewed as weak decisions, which are not available for all classes, they still perform decently in some specific categories. Inspired by this assumption, we propose a novel method Multi-Decision Fusing Model (MDFM), which comprehensively considers the decisions based on multiple FEMs to enhance the efficacy and robustness of the model. MDFM is a simple, flexible, non-parametric method that can directly apply to the existing FEMs. Besides, we extend the proposed MDFM to two FSL settings (i.e., supervised and semi-supervised settings). We evaluate the proposed method on five benchmark datasets and achieve significant improvements of 3.4%-7.3% compared with state-of-the-arts.
MHFC: Multi-Head Feature Collaboration for Few-Shot Learning
Oct 10, 2021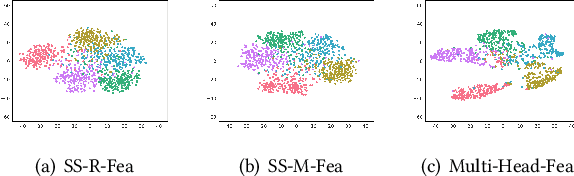
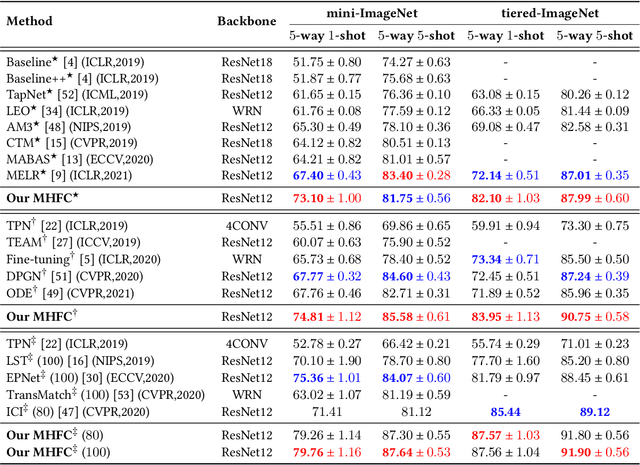
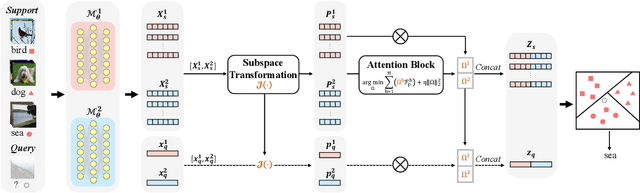
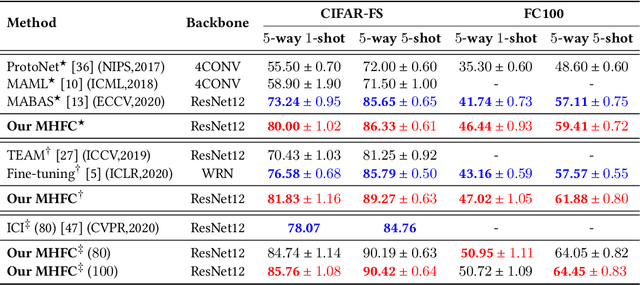
Few-shot learning (FSL) aims to address the data-scarce problem. A standard FSL framework is composed of two components: (1) Pre-train. Employ the base data to generate a CNN-based feature extraction model (FEM). (2) Meta-test. Apply the trained FEM to acquire the novel data's features and recognize them. FSL relies heavily on the design of the FEM. However, various FEMs have distinct emphases. For example, several may focus more attention on the contour information, whereas others may lay particular emphasis on the texture information. The single-head feature is only a one-sided representation of the sample. Besides the negative influence of cross-domain (e.g., the trained FEM can not adapt to the novel class flawlessly), the distribution of novel data may have a certain degree of deviation compared with the ground truth distribution, which is dubbed as distribution-shift-problem (DSP). To address the DSP, we propose Multi-Head Feature Collaboration (MHFC) algorithm, which attempts to project the multi-head features (e.g., multiple features extracted from a variety of FEMs) to a unified space and fuse them to capture more discriminative information. Typically, first, we introduce a subspace learning method to transform the multi-head features to aligned low-dimensional representations. It corrects the DSP via learning the feature with more powerful discrimination and overcomes the problem of inconsistent measurement scales from different head features. Then, we design an attention block to update combination weights for each head feature automatically. It comprehensively considers the contribution of various perspectives and further improves the discrimination of features. We evaluate the proposed method on five benchmark datasets (including cross-domain experiments) and achieve significant improvements of 2.1%-7.8% compared with state-of-the-arts.
CIM: Class-Irrelevant Mapping for Few-Shot Classification
Sep 07, 2021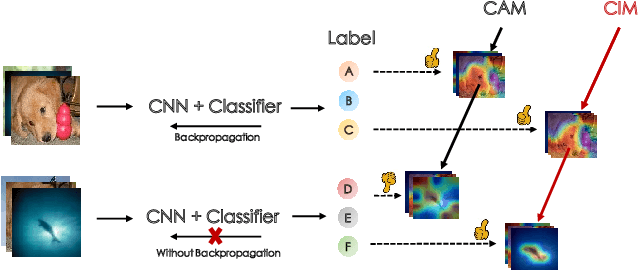
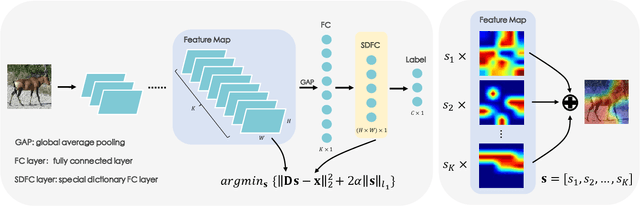
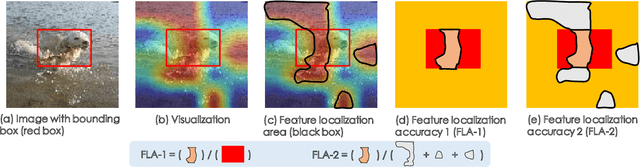
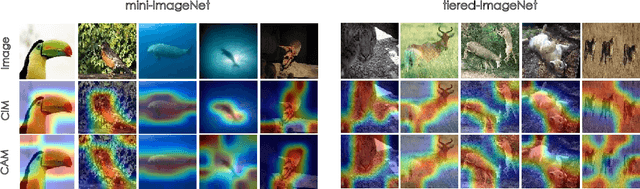
Few-shot classification (FSC) is one of the most concerned hot issues in recent years. The general setting consists of two phases: (1) Pre-train a feature extraction model (FEM) with base data (has large amounts of labeled samples). (2) Use the FEM to extract the features of novel data (with few labeled samples and totally different categories from base data), then classify them with the to-be-designed classifier. The adaptability of pre-trained FEM to novel data determines the accuracy of novel features, thereby affecting the final classification performances. To this end, how to appraise the pre-trained FEM is the most crucial focus in the FSC community. It sounds like traditional Class Activate Mapping (CAM) based methods can achieve this by overlaying weighted feature maps. However, due to the particularity of FSC (e.g., there is no backpropagation when using the pre-trained FEM to extract novel features), we cannot activate the feature map with the novel classes. To address this challenge, we propose a simple, flexible method, dubbed as Class-Irrelevant Mapping (CIM). Specifically, first, we introduce dictionary learning theory and view the channels of the feature map as the bases in a dictionary. Then we utilize the feature map to fit the feature vector of an image to achieve the corresponding channel weights. Finally, we overlap the weighted feature map for visualization to appraise the ability of pre-trained FEM on novel data. For fair use of CIM in evaluating different models, we propose a new measurement index, called Feature Localization Accuracy (FLA). In experiments, we first compare our CIM with CAM in regular tasks and achieve outstanding performances. Next, we use our CIM to appraise several classical FSC frameworks without considering the classification results and discuss them.
DLDL: Dynamic Label Dictionary Learning via Hypergraph Regularization
Oct 23, 2020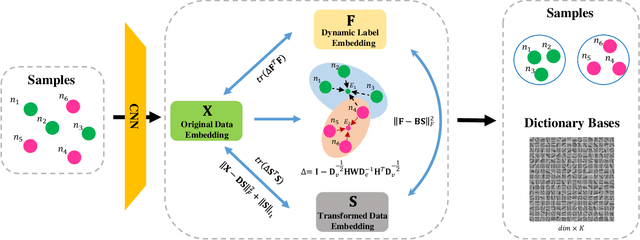
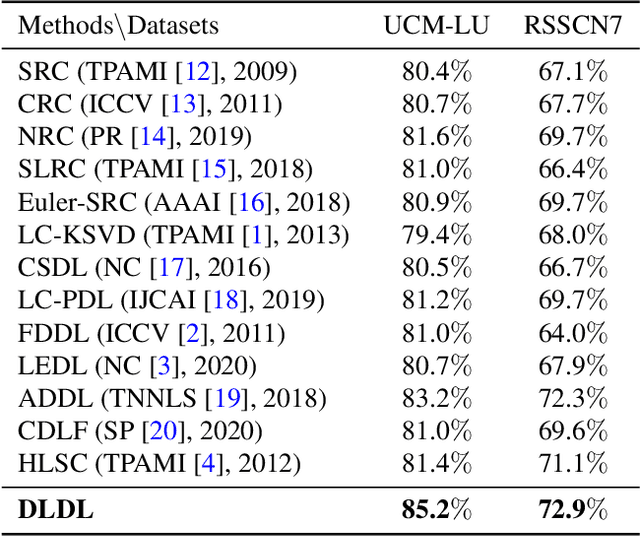
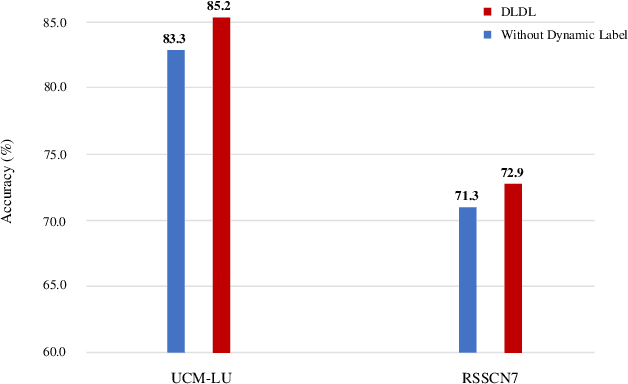
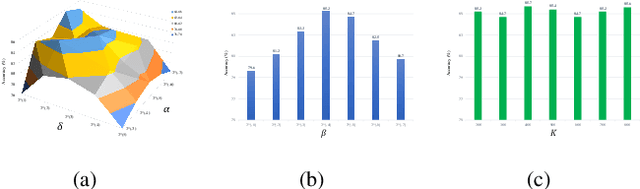
For classification tasks, dictionary learning based methods have attracted lots of attention in recent years. One popular way to achieve this purpose is to introduce label information to generate a discriminative dictionary to represent samples. However, compared with traditional dictionary learning, this category of methods only achieves significant improvements in supervised learning, and has little positive influence on semi-supervised or unsupervised learning. To tackle this issue, we propose a Dynamic Label Dictionary Learning (DLDL) algorithm to generate the soft label matrix for unlabeled data. Specifically, we employ hypergraph manifold regularization to keep the relations among original data, transformed data, and soft labels consistent. We demonstrate the efficiency of the proposed DLDL approach on two remote sensing datasets.
SAHDL: Sparse Attention Hypergraph Regularized Dictionary Learning
Oct 23, 2020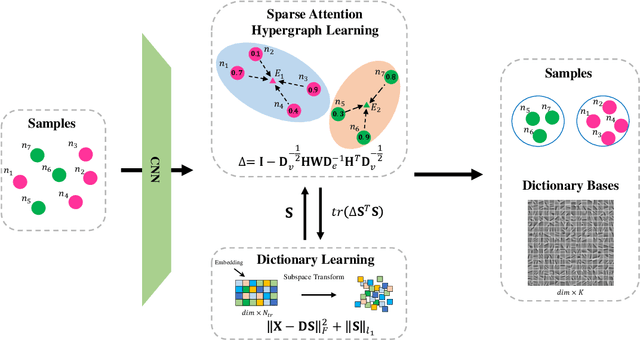
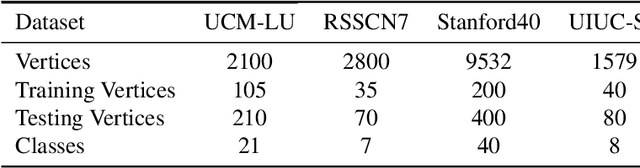
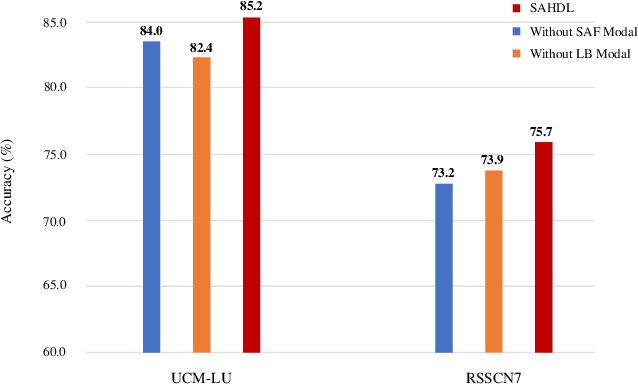
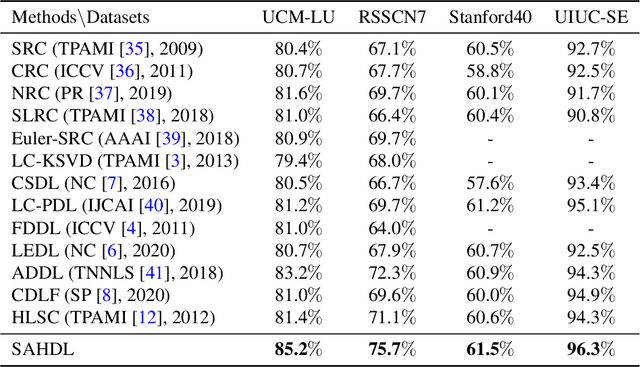
In recent years, the attention mechanism contributes significantly to hypergraph based neural networks. However, these methods update the attention weights with the network propagating. That is to say, this type of attention mechanism is only suitable for deep learning-based methods while not applicable to the traditional machine learning approaches. In this paper, we propose a hypergraph based sparse attention mechanism to tackle this issue and embed it into dictionary learning. More specifically, we first construct a sparse attention hypergraph, asset attention weights to samples by employing the $\ell_1$-norm sparse regularization to mine the high-order relationship among sample features. Then, we introduce the hypergraph Laplacian operator to preserve the local structure for subspace transformation in dictionary learning. Besides, we incorporate the discriminative information into the hypergraph as the guidance to aggregate samples. Unlike previous works, our method updates attention weights independently, does not rely on the deep network. We demonstrate the efficacy of our approach on four benchmark datasets.
Class Specific or Shared? A Hybrid Dictionary Learning Network for Image Classification
Apr 17, 2019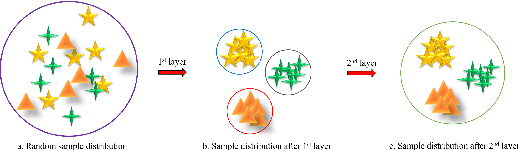
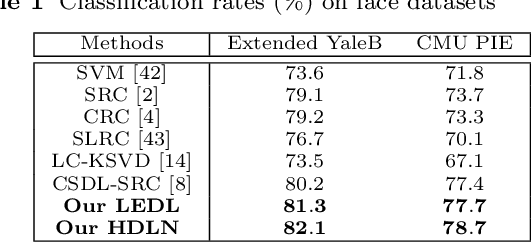
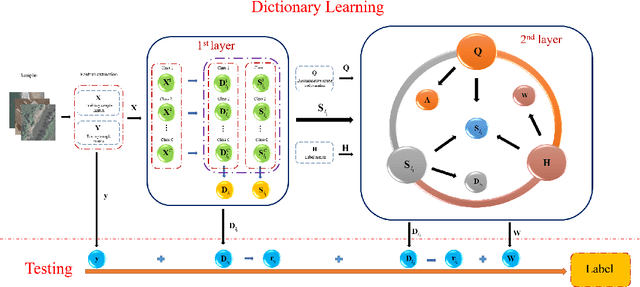
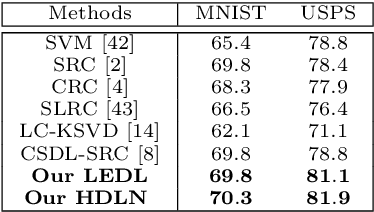
Dictionary learning methods can be split into two categories: i) class specific dictionary learning ii) class shared dictionary learning. The difference between the two categories is how to use the discriminative information. With the first category, samples of different classes are mapped to different subspaces which leads to some redundancy in the base vectors. For the second category, the samples in each specific class can not be described well. Moreover, most class shared dictionary learning methods use the L0-norm regularization term as the sparse constraint. In this paper, we first propose a novel class shared dictionary learning method named label embedded dictionary learning (LEDL) by introducing the L1-norm sparse constraint to replace the conventional L0-norm regularization term in LC-KSVD method. Then we propose a novel network named hybrid dictionary learning network (HDLN) to combine the class specific dictionary learning with class shared dictionary learning together to fully describe the feature to boost the performance of classification. Extensive experimental results on six benchmark datasets illustrate that our methods are capable of achieving superior performance compared to several conventional classification algorithms.
Label Embedded Dictionary Learning for Image Classification
Apr 17, 2019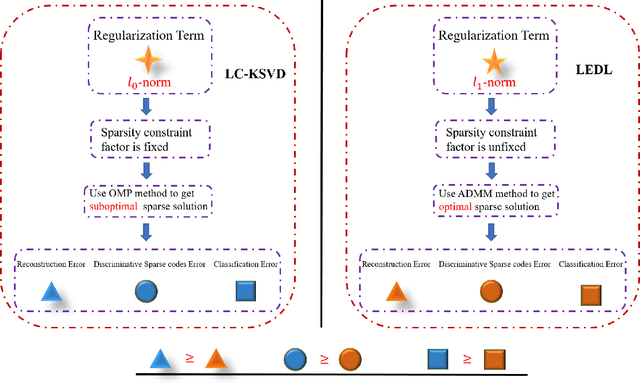


Recently, label consistent k-svd (LC-KSVD) algorithm has been successfully applied in image classification. The objective function of LC-KSVD is consisted of reconstruction error, classification error and discriminative sparse codes error with L0-norm sparse regularization term. The L0-norm, however, leads to NP-hard problem. Despite some methods such as orthogonal matching pursuit can help solve this problem to some extent, it is quite difficult to find the optimum sparse solution. To overcome this limitation, we propose a label embedded dictionary learning (LEDL) method to utilise the L1-norm as the sparse regularization term so that we can avoid the hard-to-optimize problem by solving the convex optimization problem. Alternating direction method of multipliers and blockwise coordinate descent algorithm are then exploited to optimize the corresponding objective function. Extensive experimental results on six benchmark datasets illustrate that the proposed algorithm has achieved superior performance compared to some conventional classification algorithms.
Image Tag Completion by Low-rank Factorization with Dual Reconstruction Structure Preserved
Jun 09, 2014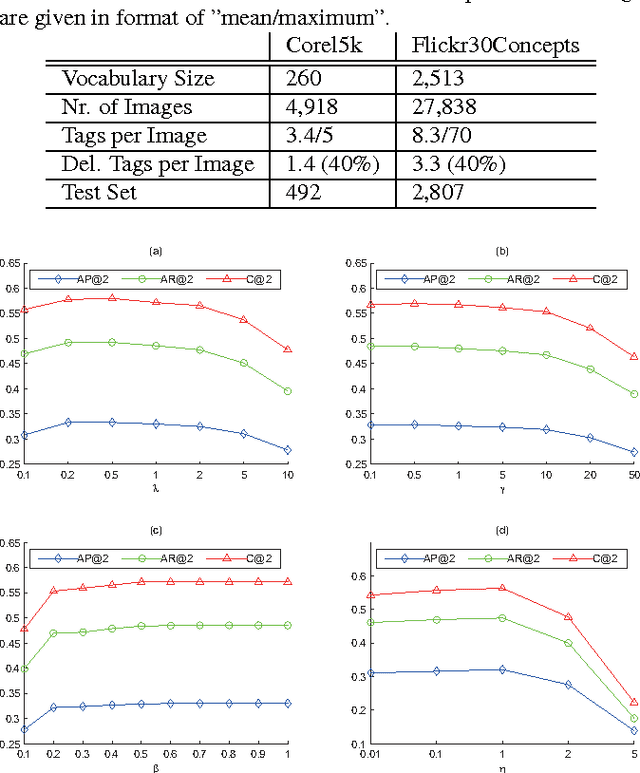
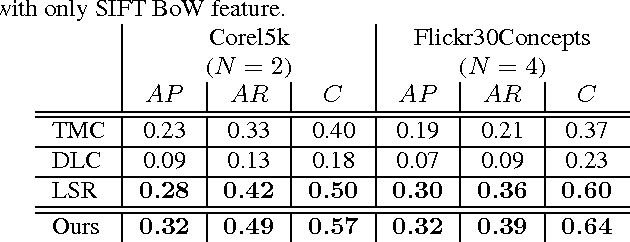
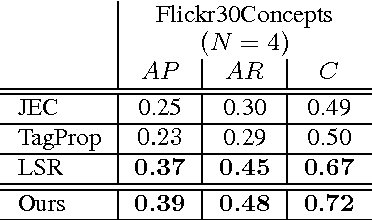
A novel tag completion algorithm is proposed in this paper, which is designed with the following features: 1) Low-rank and error s-parsity: the incomplete initial tagging matrix D is decomposed into the complete tagging matrix A and a sparse error matrix E. However, instead of minimizing its nuclear norm, A is further factor-ized into a basis matrix U and a sparse coefficient matrix V, i.e. D=UV+E. This low-rank formulation encapsulating sparse coding enables our algorithm to recover latent structures from noisy initial data and avoid performing too much denoising; 2) Local reconstruction structure consistency: to steer the completion of D, the local linear reconstruction structures in feature space and tag space are obtained and preserved by U and V respectively. Such a scheme could alleviate the negative effect of distances measured by low-level features and incomplete tags. Thus, we can seek a balance between exploiting as much information and not being mislead to suboptimal performance. Experiments conducted on Corel5k dataset and the newly issued Flickr30Concepts dataset demonstrate the effectiveness and efficiency of the proposed method.