 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Promotion Method for Generation Error Based Video Anomaly Detection
Dec 17, 2019
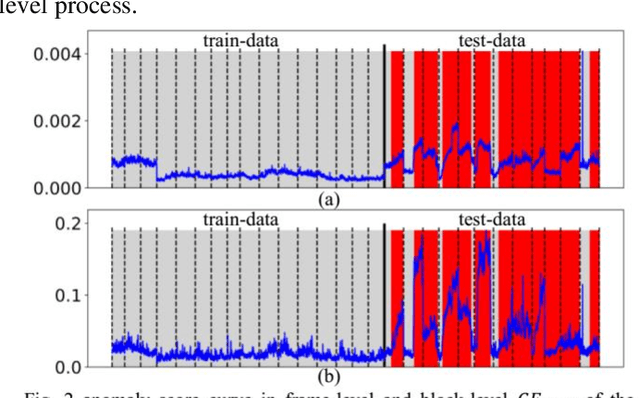
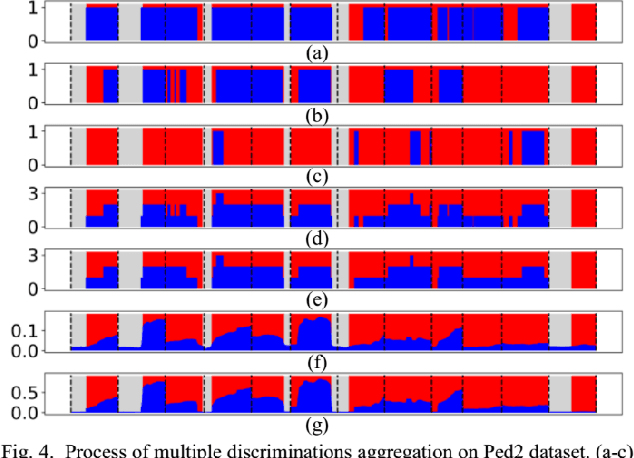
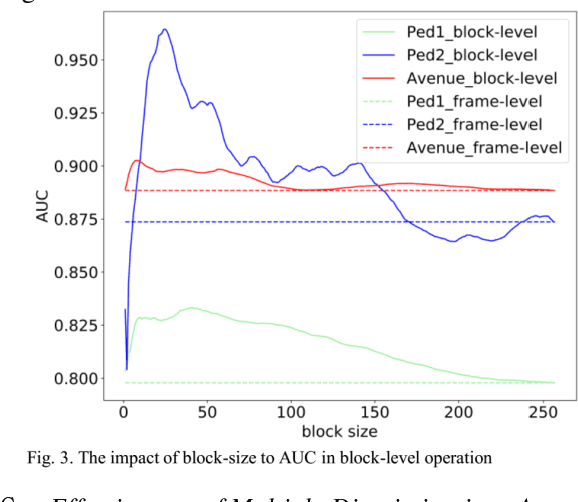
Using the generation error (GE) of a generative neural network (GNN) to detect video anomalies exhibits excellent performance. However, there are two problems when using the trained GNN models to detect anomalies. First, utilizing the frame-level GE to detect anomalies reduces the anomaly saliencies, because anomalies usually occur in local areas. Second, when multiple discriminants (a discriminant is an anomaly score sequence) are available, using the weighted sum method to aggregate multiple discriminants does not always perform effectively, and the weights are hard to tune. To address these problems, we propose an approach consists of two modules. Firstly, we replace the frame-level GE with the maximum of the block-level GEs in the frame to detect anomalies. Secondly, assuming that the higher the anomaly threshold, the more reliable the anomaly detected, we propose a reliable-anomaly (R-anomaly) based strategy to aggregate multiple discriminants. We use the R-anomalies in the auxiliary discriminants to enhance their anomaly scores in the main discriminant. Experiments are carried out on UCSD and CUHK Avenue datasets. The results demonstrate the effectiveness of the proposed method and achieve state-of-the-art performance.
Real-Time Steganalysis for Stream Media Based on Multi-channel Convolutional Sliding Windows
Feb 04, 2019
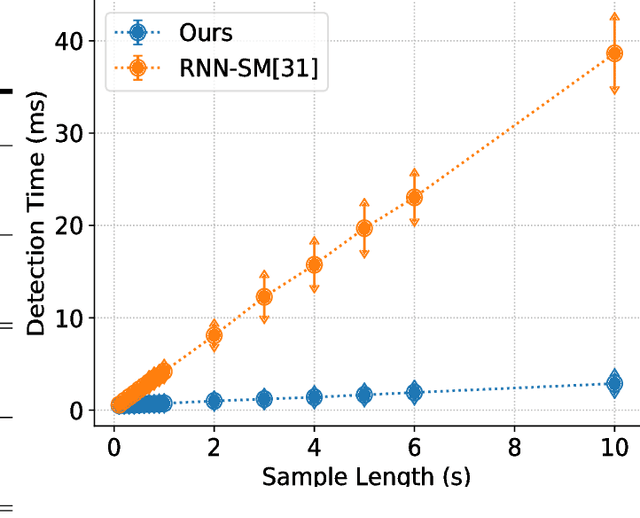
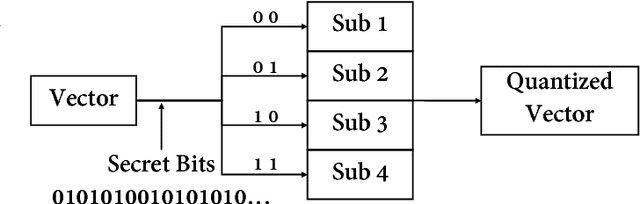
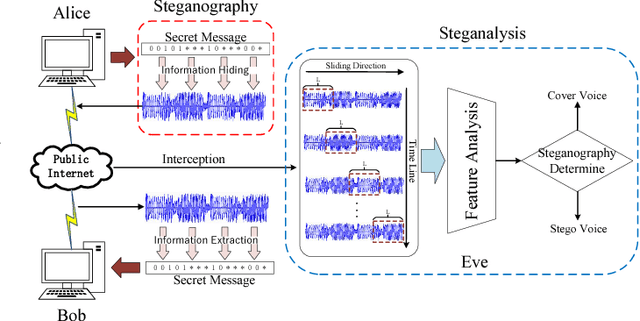
Previous VoIP steganalysis methods face great challenges in detecting speech signals at low embedding rates, and they are also generally difficult to perform real-time detection, making them hard to truly maintain cyberspace security. To solve these two challenges, in this paper, combined with the sliding window detection algorithm and Convolution Neural Network we propose a real-time VoIP steganalysis method which based on multi-channel convolution sliding windows. In order to analyze the correlations between frames and different neighborhood frames in a VoIP signal, we define multi channel sliding detection windows. Within each sliding window, we design two feature extraction channels which contain multiple convolution layers with multiple convolution kernels each layer to extract correlation features of the input signal. Then based on these extracted features, we use a forward fully connected network for feature fusion. Finally, by analyzing the statistical distribution of these features, the discriminator will determine whether the input speech signal contains covert information or not.We designed several experiments to test the proposed model's detection ability under various conditions, including different embedding rates, different speech length, etc. Experimental results showed that the proposed model outperforms all the previous methods, especially in the case of low embedding rate, which showed state-of-the-art performance. In addition, we also tested the detection efficiency of the proposed model, and the results showed that it can achieve almost real-time detection of VoIP speech signals.
Image Captioning with Object Detection and Localization
Jun 08, 2017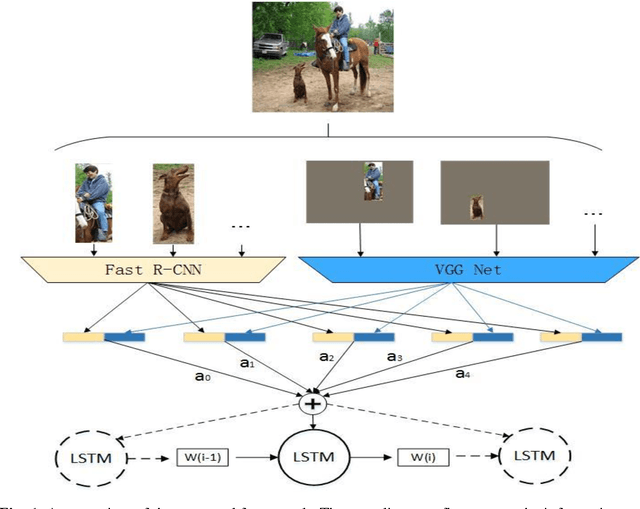
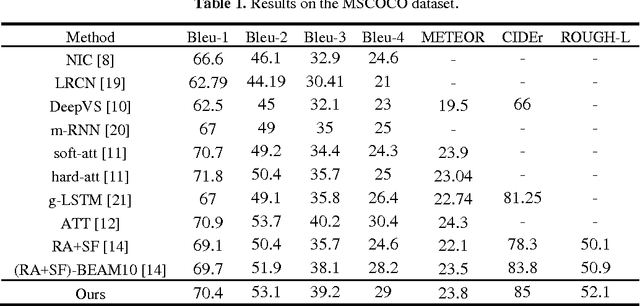


Automatically generating a natural language description of an image is a task close to the heart of image understanding. In this paper, we present a multi-model neural network method closely related to the human visual system that automatically learns to describe the content of images. Our model consists of two sub-models: an object detection and localization model, which extract the information of objects and their spatial relationship in images respectively; Besides, a deep recurrent neural network (RNN) based on long short-term memory (LSTM) units with attention mechanism for sentences generation. Each word of the description will be automatically aligned to different objects of the input image when it is generated. This is similar to the attention mechanism of the human visual system. Experimental results on the COCO dataset showcase the merit of the proposed method, which outperforms previous benchmark models.
A Deep and Autoregressive Approach for Topic Modeling of Multimodal Data
Dec 31, 2015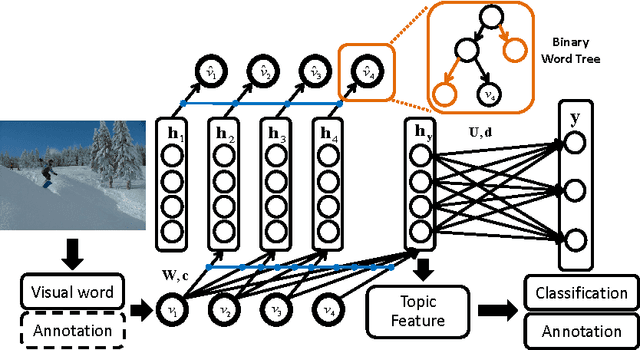

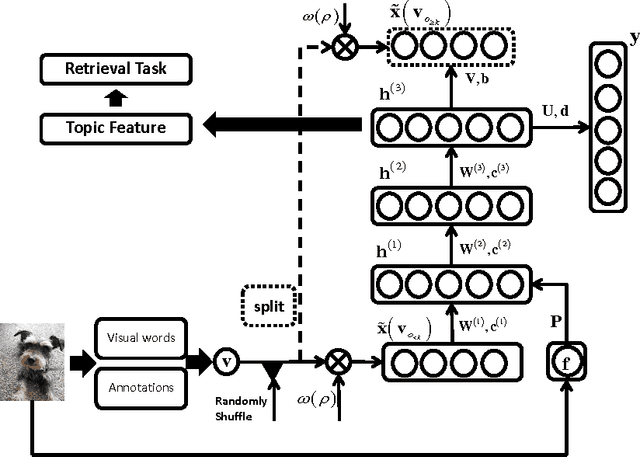

Topic modeling based on latent Dirichlet allocation (LDA) has been a framework of choice to deal with multimodal data, such as in image annotation tasks. Another popular approach to model the multimodal data is through deep neural networks, such as the deep Boltzmann machine (DBM). Recently, a new type of topic model called the Document Neural Autoregressive Distribution Estimator (DocNADE) was proposed and demonstrated state-of-the-art performance for text document modeling. In this work, we show how to successfully apply and extend this model to multimodal data, such as simultaneous image classification and annotation. First, we propose SupDocNADE, a supervised extension of DocNADE, that increases the discriminative power of the learned hidden topic features and show how to employ it to learn a joint representation from image visual words, annotation words and class label information. We test our model on the LabelMe and UIUC-Sports data sets and show that it compares favorably to other topic models. Second, we propose a deep extension of our model and provide an efficient way of training the deep model. Experimental results show that our deep model outperforms its shallow version and reaches state-of-the-art performance on the Multimedia Information Retrieval (MIR) Flickr data set.
Image Tag Completion by Low-rank Factorization with Dual Reconstruction Structure Preserved
Jun 09, 2014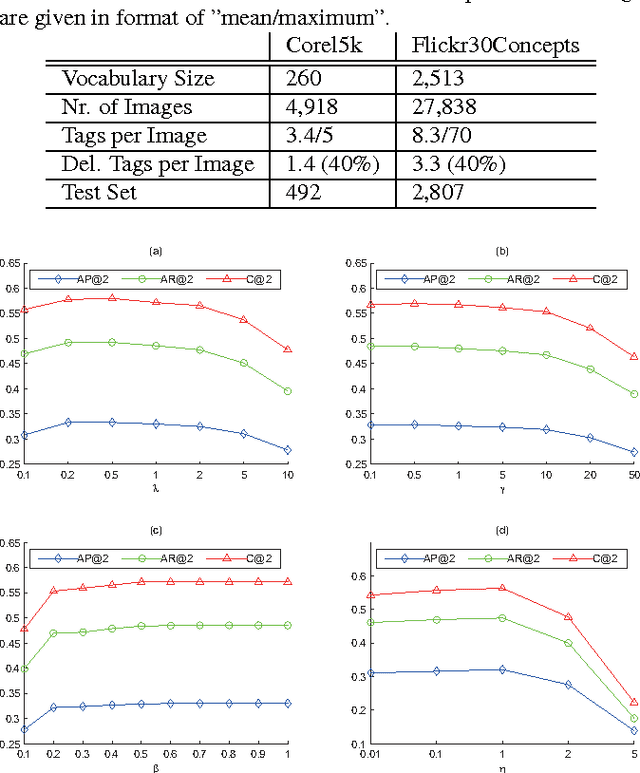
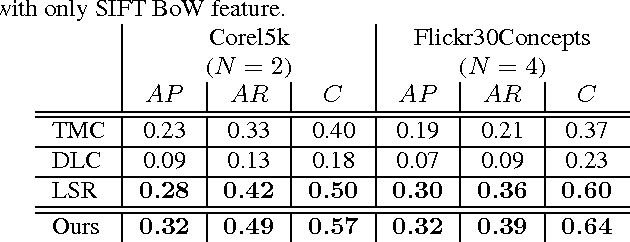
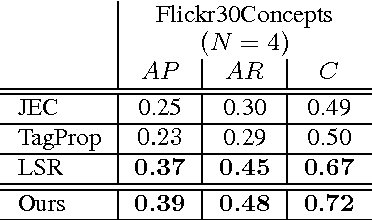
A novel tag completion algorithm is proposed in this paper, which is designed with the following features: 1) Low-rank and error s-parsity: the incomplete initial tagging matrix D is decomposed into the complete tagging matrix A and a sparse error matrix E. However, instead of minimizing its nuclear norm, A is further factor-ized into a basis matrix U and a sparse coefficient matrix V, i.e. D=UV+E. This low-rank formulation encapsulating sparse coding enables our algorithm to recover latent structures from noisy initial data and avoid performing too much denoising; 2) Local reconstruction structure consistency: to steer the completion of D, the local linear reconstruction structures in feature space and tag space are obtained and preserved by U and V respectively. Such a scheme could alleviate the negative effect of distances measured by low-level features and incomplete tags. Thus, we can seek a balance between exploiting as much information and not being mislead to suboptimal performance. Experiments conducted on Corel5k dataset and the newly issued Flickr30Concepts dataset demonstrate the effectiveness and efficiency of the proposed method.
Image retrieval with hierarchical matching pursuit
Jun 05, 2014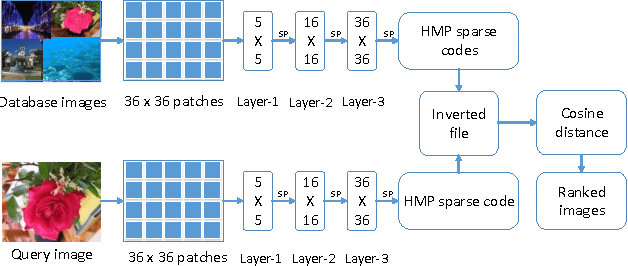
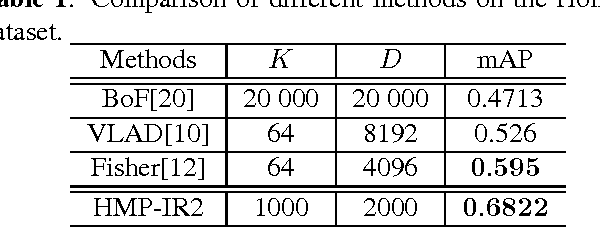
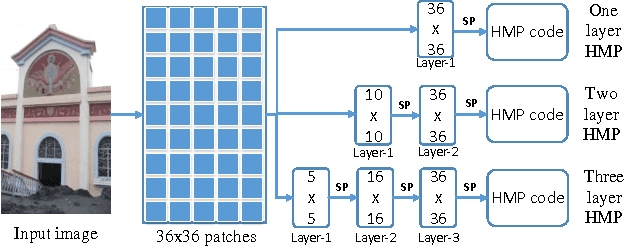
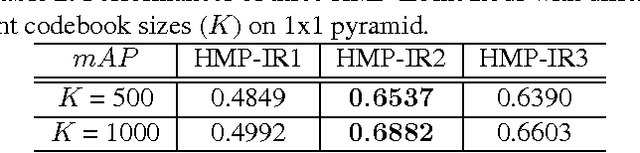
A novel representation of images for image retrieval is introduced in this paper, by using a new type of feature with remarkable discriminative power. Despite the multi-scale nature of objects, most existing models perform feature extraction on a fixed scale, which will inevitably degrade the performance of the whole system. Motivated by this, we introduce a hierarchical sparse coding architecture for image retrieval to explore multi-scale cues. Sparse codes extracted on lower layers are transmitted to higher layers recursively. With this mechanism, cues from different scales are fused. Experiments on the Holidays dataset show that the proposed method achieves an excellent retrieval performance with a small code length.
A Supervised Neural Autoregressive Topic Model for Simultaneous Image Classification and Annotation
May 23, 2013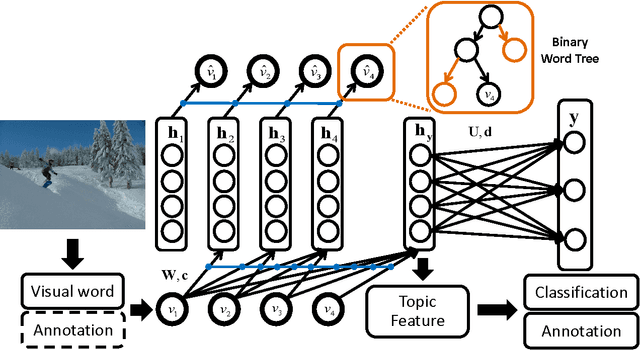

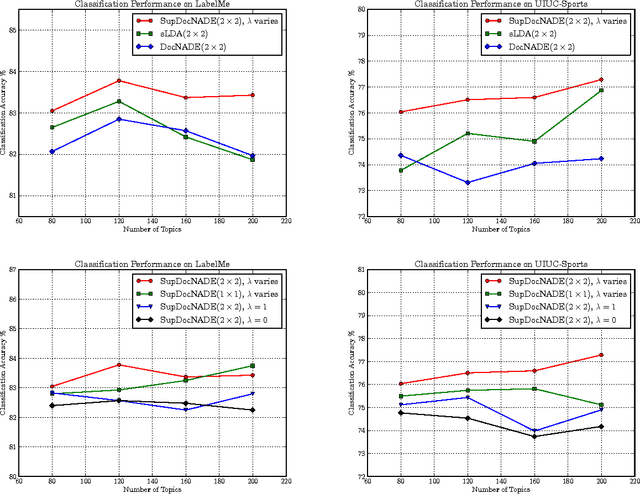

Topic modeling based on latent Dirichlet allocation (LDA) has been a framework of choice to perform scene recognition and annotation. Recently, a new type of topic model called the Document Neural Autoregressive Distribution Estimator (DocNADE) was proposed and demonstrated state-of-the-art performance for document modeling. In this work, we show how to successfully apply and extend this model to the context of visual scene modeling. Specifically, we propose SupDocNADE, a supervised extension of DocNADE, that increases the discriminative power of the hidden topic features by incorporating label information into the training objective of the model. We also describe how to leverage information about the spatial position of the visual words and how to embed additional image annotations, so as to simultaneously perform image classification and annotation. We test our model on the Scene15, LabelMe and UIUC-Sports datasets and show that it compares favorably to other topic models such as the supervised variant of LDA.