 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep and Autoregressive Approach for Topic Modeling of Multimodal Data
Paper and Code
Dec 31, 2015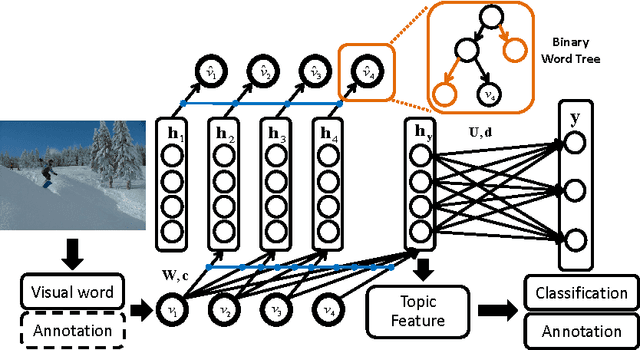

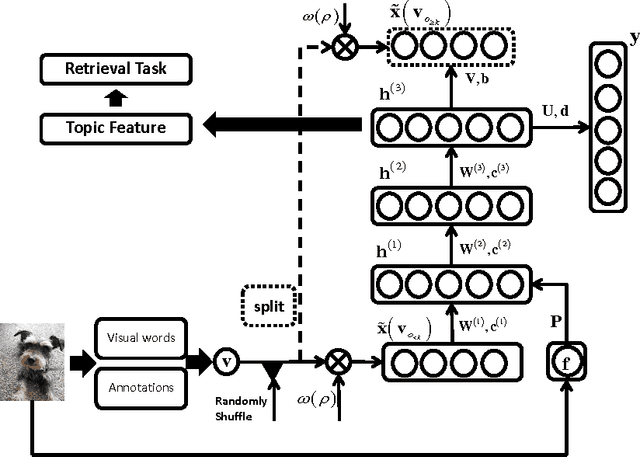

Topic modeling based on latent Dirichlet allocation (LDA) has been a framework of choice to deal with multimodal data, such as in image annotation tasks. Another popular approach to model the multimodal data is through deep neural networks, such as the deep Boltzmann machine (DBM). Recently, a new type of topic model called the Document Neural Autoregressive Distribution Estimator (DocNADE) was proposed and demonstrated state-of-the-art performance for text document modeling. In this work, we show how to successfully apply and extend this model to multimodal data, such as simultaneous image classification and annotation. First, we propose SupDocNADE, a supervised extension of DocNADE, that increases the discriminative power of the learned hidden topic features and show how to employ it to learn a joint representation from image visual words, annotation words and class label information. We test our model on the LabelMe and UIUC-Sports data sets and show that it compares favorably to other topic models. Second, we propose a deep extension of our model and provide an efficient way of training the deep model. Experimental results show that our deep model outperforms its shallow version and reaches state-of-the-art performance on the Multimedia Information Retrieval (MIR) Flickr data set.