 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelecting task with optimal transport self-supervised learning for few-shot classification
Apr 01, 2022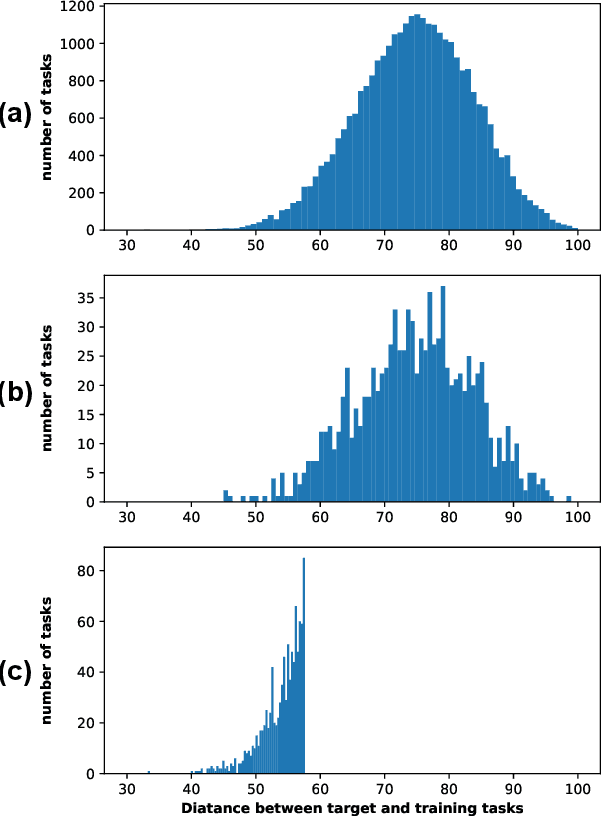
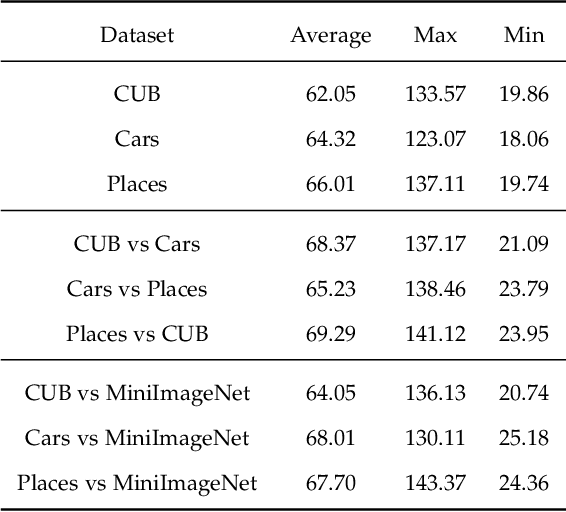

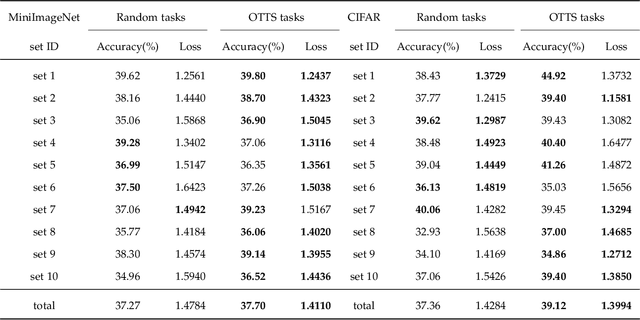
Few-Shot classification aims at solving problems that only a few samples are available in the training process. Due to the lack of samples, researchers generally employ a set of training tasks from other domains to assist the target task, where the distribution between assistant tasks and the target task is usually different. To reduce the distribution gap, several lines of methods have been proposed, such as data augmentation and domain alignment. However, one common drawback of these algorithms is that they ignore the similarity task selection before training. The fundamental problem is to push the auxiliary tasks close to the target task. In this paper, we propose a novel task selecting algorithm, named Optimal Transport Task Selecting (OTTS), to construct a training set by selecting similar tasks for Few-Shot learning. Specifically, the OTTS measures the task similarity by calculating the optimal transport distance and completes the model training via a self-supervised strategy. By utilizing the selected tasks with OTTS, the training process of Few-Shot learning become more stable and effective. Other proposed methods including data augmentation and domain alignment can be used in the meantime with OTTS. We conduct extensive experiments on a variety of datasets, including MiniImageNet, CIFAR, CUB, Cars, and Places, to evaluate the effectiveness of OTTS. Experimental results validate that our OTTS outperforms the typical baselines, i.e., MAML, matchingnet, protonet, by a large margin (averagely 1.72\% accuracy improvement).
Semantic-Preserving Adversarial Text Attacks
Aug 23, 2021


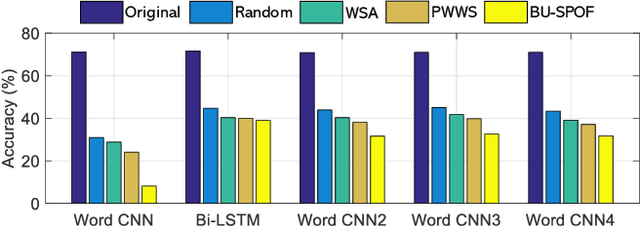
Deep neural networks (DNNs) are known to be vulnerable to adversarial images, while their robustness in text classification is rarely studied. Several lines of text attack methods have been proposed in the literature, including character-level, word-level, and sentence-level attacks. However, it is still a challenge to minimize the number of word changes necessary to induce misclassification, while simultaneously ensuring lexical correctness, syntactic soundness, and semantic similarity. In this paper, we propose a Bigram and Unigram based adaptive Semantic Preservation Optimization (BU-SPO) method to examine the vulnerability of deep models. Our method has four major merits. Firstly, we propose to attack text documents not only at the unigram word level but also at the bigram level which better keeps semantics and avoids producing meaningless outputs. Secondly, we propose a hybrid method to replace the input words with options among both their synonyms candidates and sememe candidates, which greatly enriches the potential substitutions compared to only using synonyms. Thirdly, we design an optimization algorithm, i.e., Semantic Preservation Optimization (SPO), to determine the priority of word replacements, aiming to reduce the modification cost. Finally, we further improve the SPO with a semantic Filter (named SPOF) to find the adversarial example with the highest semantic similarity. We evaluate the effectiveness of our BU-SPO and BU-SPOF on IMDB, AG's News, and Yahoo! Answers text datasets by attacking four popular DNNs models. Results show that our methods achieve the highest attack success rates and semantics rates by changing the smallest number of words compared with existing methods.
Targeted Attention Attack on Deep Learning Models in Road Sign Recognition
Oct 09, 2020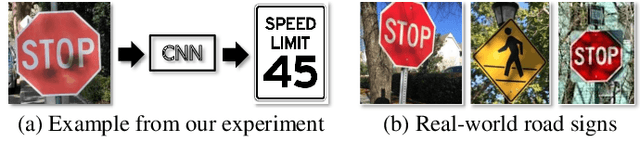
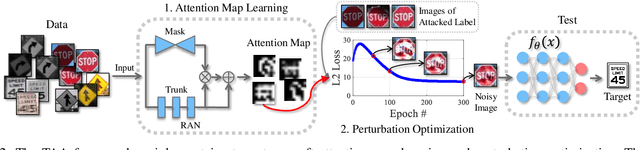
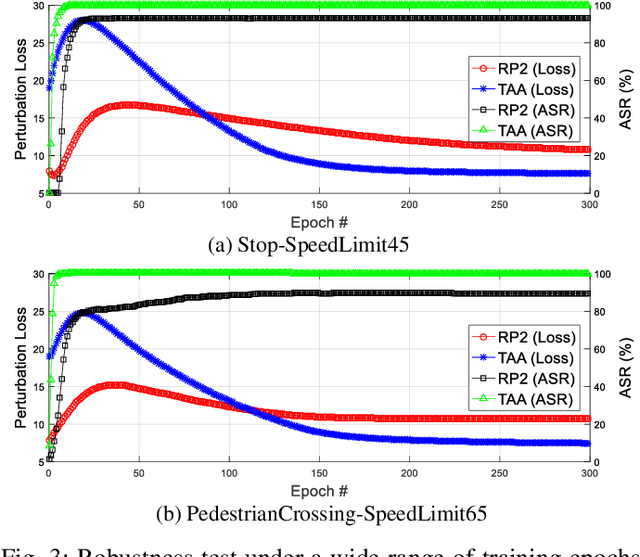
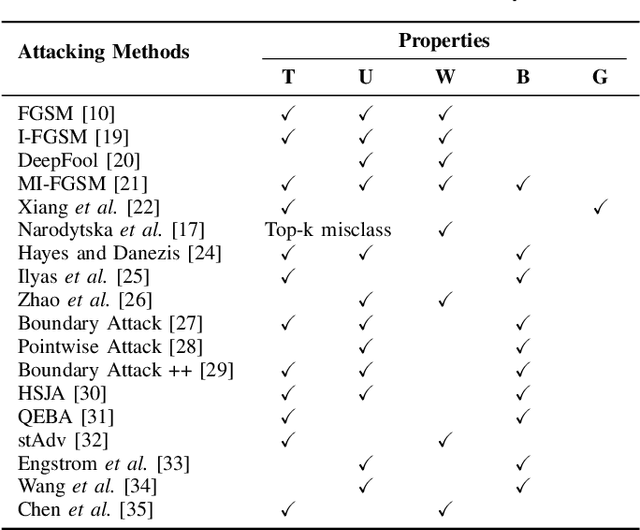
Real world traffic sign recognition is an important step towards building autonomous vehicles, most of which highly dependent on Deep Neural Networks (DNNs). Recent studies demonstrated that DNNs are surprisingly susceptible to adversarial examples. Many attack methods have been proposed to understand and generate adversarial examples, such as gradient based attack, score based attack, decision based attack, and transfer based attacks. However, most of these algorithms are ineffective in real-world road sign attack, because (1) iteratively learning perturbations for each frame is not realistic for a fast moving car and (2) most optimization algorithms traverse all pixels equally without considering their diverse contribution. To alleviate these problems, this paper proposes the targeted attention attack (TAA) method for real world road sign attack. Specifically, we have made the following contributions: (1) we leverage the soft attention map to highlight those important pixels and skip those zero-contributed areas - this also helps to generate natural perturbations, (2) we design an efficient universal attack that optimizes a single perturbation/noise based on a set of training images under the guidance of the pre-trained attention map, (3) we design a simple objective function that can be easily optimized, (4) we evaluate the effectiveness of TAA on real world data sets. Experimental results validate that the TAA method improves the attack successful rate (nearly 10%) and reduces the perturbation loss (about a quarter) compared with the popular RP2 method. Additionally, our TAA also provides good properties, e.g., transferability and generalization capability. We provide code and data to ensure the reproducibility: https://github.com/AdvAttack/RoadSignAttack.