 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-dimensional structure learning of binary pairwise Markov networks: A comparative numerical study
Jan 14, 2019
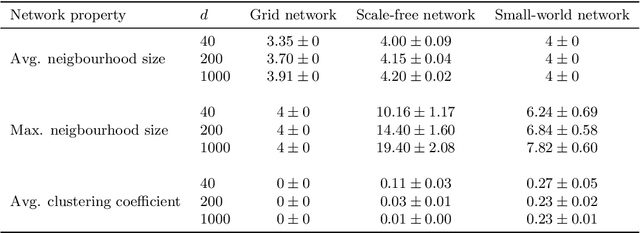


Learning the undirected graph structure of a Markov network from data is a problem that has received a lot of attention during the last few decades. As a result of the general applicability of the model class, a myriad of methods have been developed in parallel in several research fields. Recently, as the size of the considered systems has increased, the focus of new methods has been shifted towards the high-dimensional domain. In particular, the introduction of the pseudo-likelihood function has pushed the limits of score-based methods originally based on the likelihood. At the same time, an array of methods based on simple pairwise tests have been developed to meet the challenges set by the increasingly large data sets in computational biology. Apart from being applicable on high-dimensional problems, methods based on the pseudo-likelihood and pairwise tests are fundamentally very different. In this work, we perform an extensive numerical study comparing the different types of methods on data generated by binary pairwise Markov networks. For sampling large networks, we use a parallelizable Gibbs sampler based on sparse restricted Boltzmann machines. Our results show that pairwise methods can be more accurate than pseudo-likelihood methods in settings often encountered in high-dimensional structure learning.