 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemSim: Revisiting Weak-to-Strong Consistency from a Semantic Similarity Perspective for Semi-supervised Medical Image Segmentation
Paper and Code
Oct 17, 2024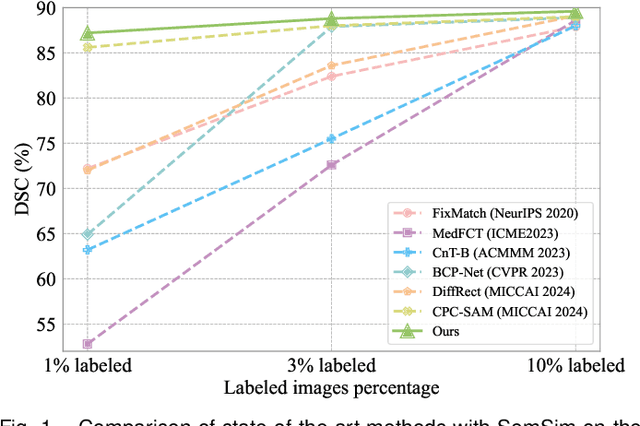
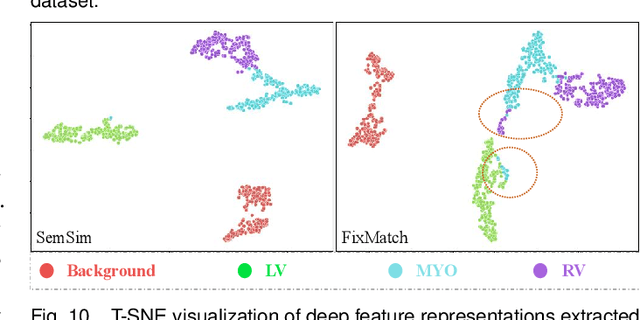

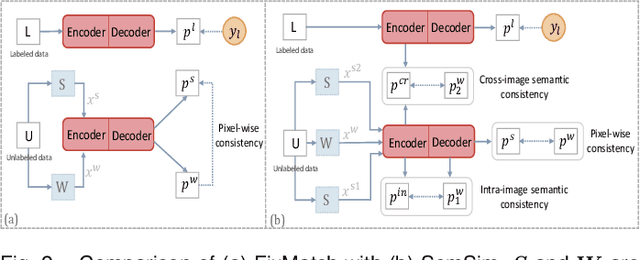
Semi-supervised learning (SSL) for medical image segmentation is a challenging yet highly practical task, which reduces reliance on large-scale labeled dataset by leveraging unlabeled samples. Among SSL techniques, the weak-to-strong consistency framework, popularized by FixMatch, has emerged as a state-of-the-art method in classification tasks. Notably, such a simple pipeline has also shown competitive performance in medical image segmentation. However, two key limitations still persist, impeding its efficient adaptation: (1) the neglect of contextual dependencies results in inconsistent predictions for similar semantic features, leading to incomplete object segmentation; (2) the lack of exploitation of semantic similarity between labeled and unlabeled data induces considerable class-distribution discrepancy. To address these limitations, we propose a novel semi-supervised framework based on FixMatch, named SemSim, powered by two appealing designs from semantic similarity perspective: (1) rectifying pixel-wise prediction by reasoning about the intra-image pair-wise affinity map, thus integrating contextual dependencies explicitly into the final prediction; (2) bridging labeled and unlabeled data via a feature querying mechanism for compact class representation learning, which fully considers cross-image anatomical similarities. As the reliable semantic similarity extraction depends on robust features, we further introduce an effective spatial-aware fusion module (SFM) to explore distinctive information from multiple scales. Extensive experiments show that SemSim yields consistent improvements over the state-of-the-art methods across three public segmentation benchmarks.