 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Unsupervised Cross-Lingual Word Embedding using Domain Flow Interpolation
Oct 07, 2022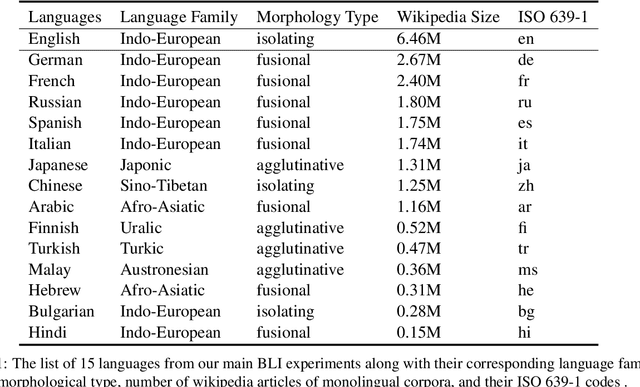
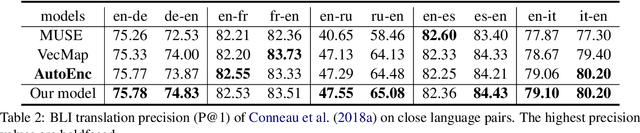

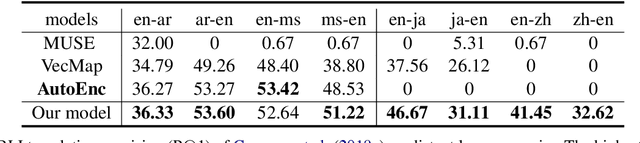
This paper investigates an unsupervised approach towards deriving a universal, cross-lingual word embedding space, where words with similar semantics from different languages are close to one another. Previous adversarial approaches have shown promising results in inducing cross-lingual word embedding without parallel data. However, the training stage shows instability for distant language pairs. Instead of mapping the source language space directly to the target language space, we propose to make use of a sequence of intermediate spaces for smooth bridging. Each intermediate space may be conceived as a pseudo-language space and is introduced via simple linear interpolation. This approach is modeled after domain flow in computer vision, but with a modified objective function. Experiments on intrinsic Bilingual Dictionary Induction tasks show that the proposed approach can improve the robustness of adversarial models with comparable and even better precision. Further experiments on the downstream task of Cross-Lingual Natural Language Inference show that the proposed model achieves significant performance improvement for distant language pairs in downstream tasks compared to state-of-the-art adversarial and non-adversarial models.