 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransform and Entropy Coding in AV2
Jan 06, 2026AV2 is the successor to the AV1 royalty-free video coding standard developed by the Alliance for Open Media (AOMedia). Its primary objective is to deliver substantial compression gains and subjective quality improvements while maintaining low-complexity encoder and decoder operations. This paper describes the transform, quantization and entropy coding design in AV2, including redesigned transform kernels and data-driven transforms, expanded transform partitioning, and a mode & coefficient dependent transform signaling. AV2 introduces several new coding tools including Intra/Inter Secondary Transforms (IST), Trellis Coded Quantization (TCQ), Adaptive Transform Coding (ATC), Probability Adaptation Rate Adjustment (PARA), Forward Skip Coding (FSC), Cross Chroma Component Transforms (CCTX), Parity Hiding (PH) tools and improved lossless coding. These advances enable AV2 to deliver the highest quality video experience for video applications at a significantly reduced bitrate.
Ultra Low-latency, Low-area Inference Accelerators using Heterogeneous Deep Quantization with QKeras and hls4ml
Jun 15, 2020


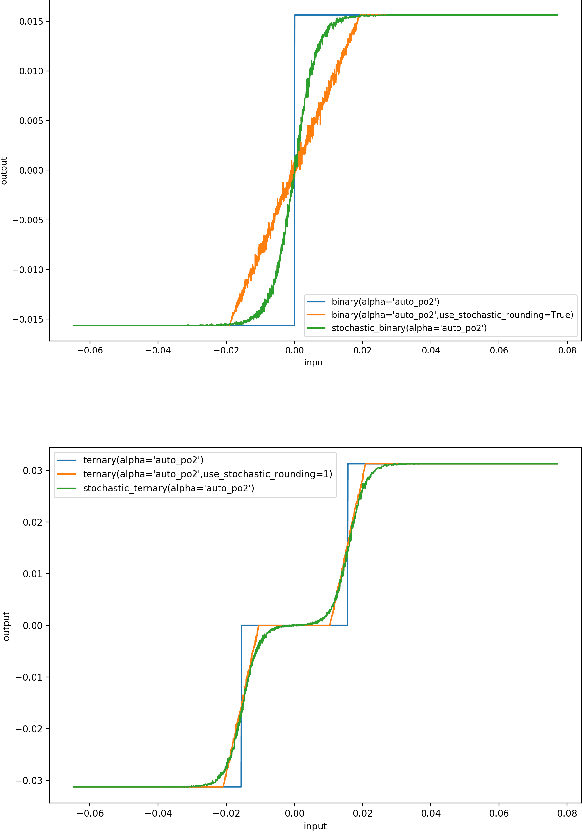
In this paper, we introduce the QKeras library, an extension of the Keras library allowing for the creation of heterogeneously quantized versions of deep neural network models, through drop-in replacement of Keras layers. These models are trained quantization-aware, where the user can trade off model area or energy consumption by accuracy. We demonstrate how the reduction of numerical precision, through quantization-aware training, significantly reduces resource consumption while retaining high accuracy when implemented on FPGA hardware. Together with the hls4ml library, this allows for a fully automated deployment of quantized Keras models on chip, crucial for ultra low-latency inference. As a benchmark problem, we consider a classification task for the triggering of events in proton-proton collisions at the CERN Large Hadron Collider, where a latency of ${\mathcal O}(1)~\mu$s is required.