 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoltzmann Tuning of Generative Models
Apr 12, 2021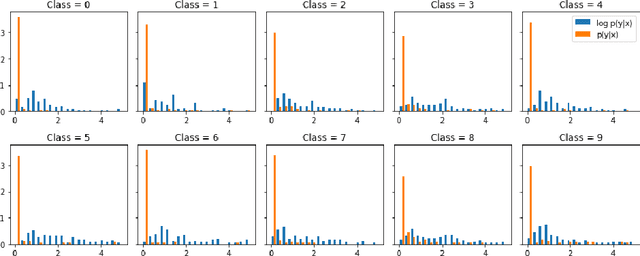
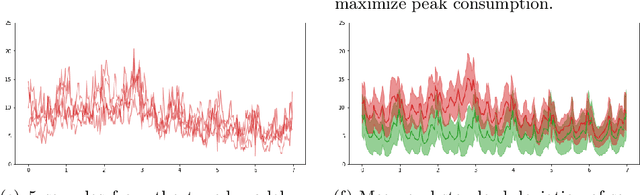
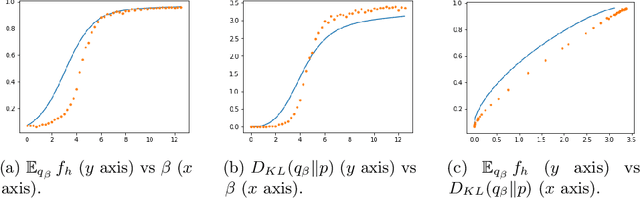
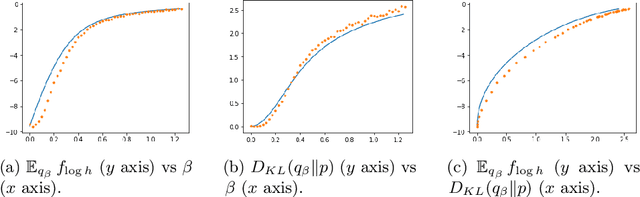
The paper focuses on the a posteriori tuning of a generative model in order to favor the generation of good instances in the sense of some external differentiable criterion. The proposed approach, called Boltzmann Tuning of Generative Models (BTGM), applies to a wide range of applications. It covers conditional generative modelling as a particular case, and offers an affordable alternative to rejection sampling. The contribution of the paper is twofold. Firstly, the objective is formalized and tackled as a well-posed optimization problem; a practical methodology is proposed to choose among the candidate criteria representing the same goal, the one best suited to efficiently learn a tuned generative model. Secondly, the merits of the approach are demonstrated on a real-world application, in the context of robust design for energy policies, showing the ability of BTGM to sample the extreme regions of the considered criteria.
Anomaly Detection With Conditional Variational Autoencoders
Oct 12, 2020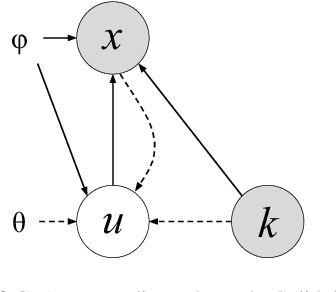
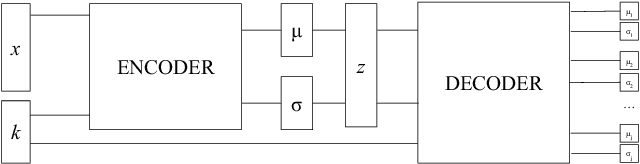

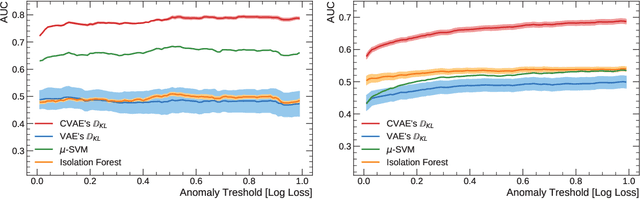
Exploiting the rapid advances in probabilistic inference, in particular variational Bayes and variational autoencoders (VAEs), for anomaly detection (AD) tasks remains an open research question. Previous works argued that training VAE models only with inliers is insufficient and the framework should be significantly modified in order to discriminate the anomalous instances. In this work, we exploit the deep conditional variational autoencoder (CVAE) and we define an original loss function together with a metric that targets hierarchically structured data AD. Our motivating application is a real world problem: monitoring the trigger system which is a basic component of many particle physics experiments at the CERN Large Hadron Collider (LHC). In the experiments we show the superior performance of this method for classical machine learning (ML) benchmarks and for our application.
Variational Auto-Encoder: not all failures are equal
Mar 04, 2020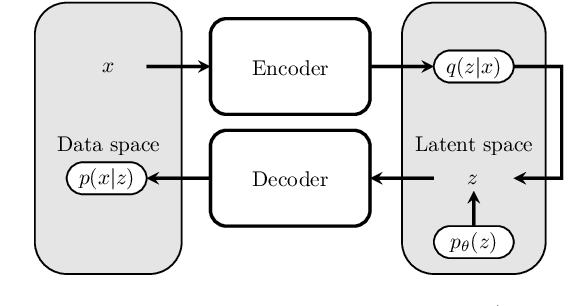
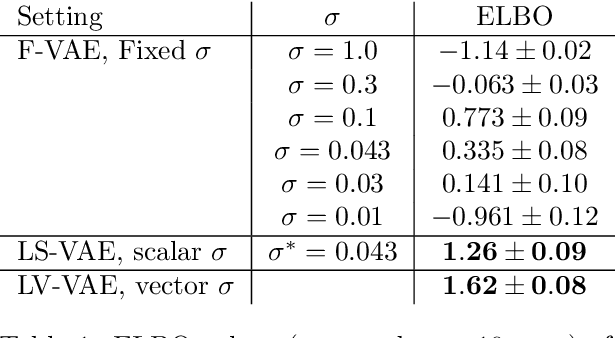
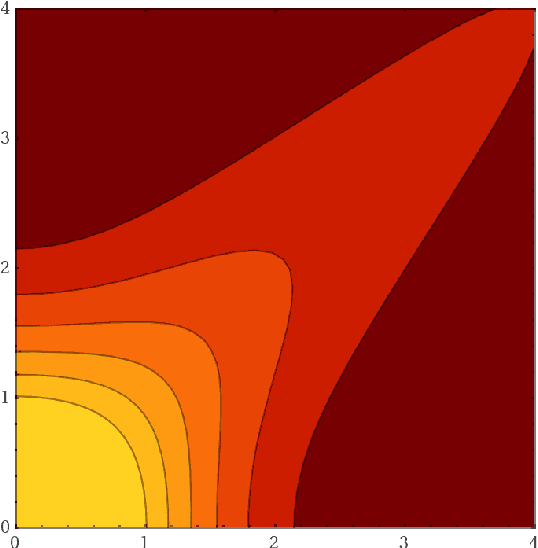

We claim that a source of severe failures for Variational Auto-Encoders is the choice of the distribution class used for the observation model.A first theoretical and experimental contribution of the paper is to establish that even in the large sample limit with arbitrarily powerful neural architectures and latent space, the VAE failsif the sharpness of the distribution class does not match the scale of the data.Our second claim is that the distribution sharpness must preferably be learned by the VAE (as opposed to, fixed and optimized offline): Autonomously adjusting this sharpness allows the VAE to dynamically control the trade-off between the optimization of the reconstruction loss and the latent compression. A second empirical contribution is to show how the control of this trade-off is instrumental in escaping poor local optima, akin a simulated annealing schedule.Both claims are backed upon experiments on artificial data, MNIST and CelebA, showing how sharpness learning addresses the notorious VAE blurriness issue.
From abstract items to latent spaces to observed data and back: Compositional Variational Auto-Encoder
Jan 22, 2020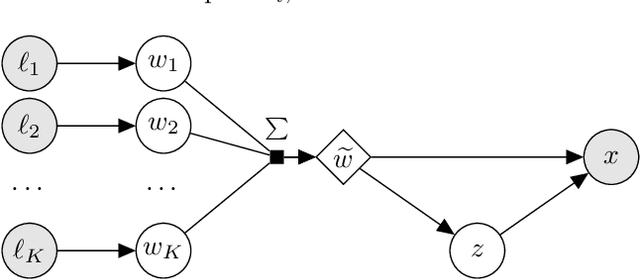
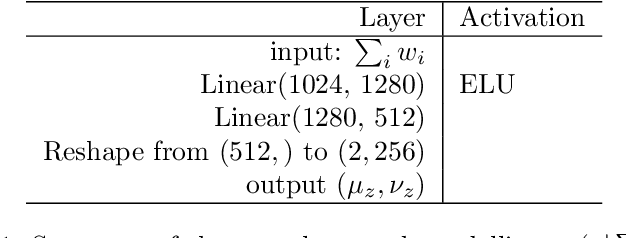
Conditional Generative Models are now acknowledged an essential tool in Machine Learning. This paper focuses on their control. While many approaches aim at disentangling the data through the coordinate-wise control of their latent representations, another direction is explored in this paper. The proposed CompVAE handles data with a natural multi-ensemblist structure (i.e. that can naturally be decomposed into elements). Derived from Bayesian variational principles, CompVAE learns a latent representation leveraging both observational and symbolic information. A first contribution of the approach is that this latent representation supports a compositional generative model, amenable to multi-ensemblist operations (addition or subtraction of elements in the composition). This compositional ability is enabled by the invariance and generality of the whole framework w.r.t. respectively, the order and number of the elements. The second contribution of the paper is a proof of concept on synthetic 1D and 2D problems, demonstrating the efficiency of the proposed approach.
New Losses for Generative Adversarial Learning
Jul 26, 2018



Generative Adversarial Networks (Goodfellow et al., 2014), a major breakthrough in the field of generative modeling, learn a discriminator to estimate some distance between the target and the candidate distributions. This paper examines mathematical issues regarding the way the gradients for the generative model are computed in this context, and notably how to take into account how the discriminator itself depends on the generator parameters. A unifying methodology is presented to define mathematically sound training objectives for generative models taking this dependency into account in a robust way, covering both GAN, VAE and some GAN variants as particular cases.